 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometric Jensen-Shannon Divergence Between Gaussian Measures On Hilbert Space
Jun 12, 2025This work studies the Geometric Jensen-Shannon divergence, based on the notion of geometric mean of probability measures, in the setting of Gaussian measures on an infinite-dimensional Hilbert space. On the set of all Gaussian measures equivalent to a fixed one, we present a closed form expression for this divergence that directly generalizes the finite-dimensional version. Using the notion of Log-Determinant divergences between positive definite unitized trace class operators, we then define a Regularized Geometric Jensen-Shannon divergence that is valid for any pair of Gaussian measures and that recovers the exact Geometric Jensen-Shannon divergence between two equivalent Gaussian measures when the regularization parameter tends to zero.
Learning a Single Index Model from Anisotropic Data with vanilla Stochastic Gradient Descent
Mar 31, 2025We investigate the problem of learning a Single Index Model (SIM)- a popular model for studying the ability of neural networks to learn features - from anisotropic Gaussian inputs by training a neuron using vanilla Stochastic Gradient Descent (SGD). While the isotropic case has been extensively studied, the anisotropic case has received less attention and the impact of the covariance matrix on the learning dynamics remains unclear. For instance, Mousavi-Hosseini et al. (2023b) proposed a spherical SGD that requires a separate estimation of the data covariance matrix, thereby oversimplifying the influence of covariance. In this study, we analyze the learning dynamics of vanilla SGD under the SIM with anisotropic input data, demonstrating that vanilla SGD automatically adapts to the data's covariance structure. Leveraging these results, we derive upper and lower bounds on the sample complexity using a notion of effective dimension that is determined by the structure of the covariance matrix instead of the input data dimension.
Kullback-Leibler and Renyi divergences in reproducing kernel Hilbert space and Gaussian process settings
Jul 18, 2022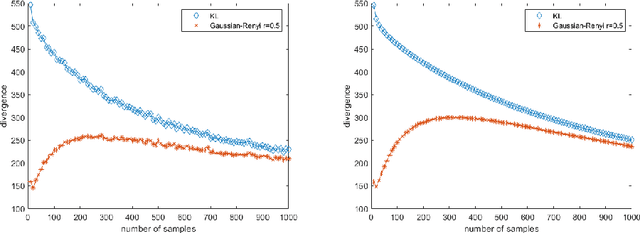
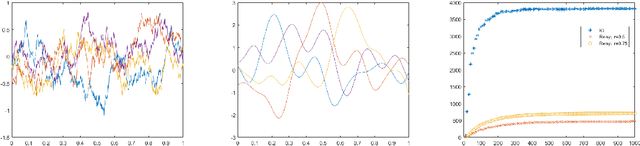
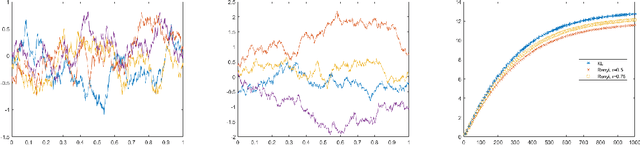
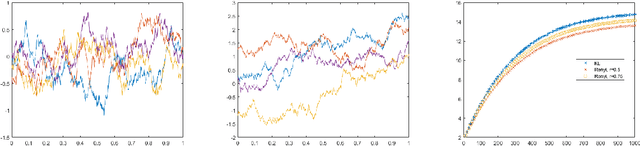
In this work, we present formulations for regularized Kullback-Leibler and R\'enyi divergences via the Alpha Log-Determinant (Log-Det) divergences between positive Hilbert-Schmidt operators on Hilbert spaces in two different settings, namely (i) covariance operators and Gaussian measures defined on reproducing kernel Hilbert spaces (RKHS); and (ii) Gaussian processes with squared integrable sample paths. For characteristic kernels, the first setting leads to divergences between arbitrary Borel probability measures on a complete, separable metric space. We show that the Alpha Log-Det divergences are continuous in the Hilbert-Schmidt norm, which enables us to apply laws of large numbers for Hilbert space-valued random variables. As a consequence of this, we show that, in both settings, the infinite-dimensional divergences can be consistently and efficiently estimated from their finite-dimensional versions, using finite-dimensional Gram matrices/Gaussian measures and finite sample data, with {\it dimension-independent} sample complexities in all cases. RKHS methodology plays a central role in the theoretical analysis in both settings. The mathematical formulation is illustrated by numerical experiments.
Finite sample approximations of exact and entropic Wasserstein distances between covariance operators and Gaussian processes
Apr 26, 2021This work studies finite sample approximations of the exact and entropic regularized Wasserstein distances between centered Gaussian processes and, more generally, covariance operators of functional random processes. We first show that these distances/divergences are fully represented by reproducing kernel Hilbert space (RKHS) covariance and cross-covariance operators associated with the corresponding covariance functions. Using this representation, we show that the Sinkhorn divergence between two centered Gaussian processes can be consistently and efficiently estimated from the divergence between their corresponding normalized finite-dimensional covariance matrices, or alternatively, their sample covariance operators. Consequently, this leads to a consistent and efficient algorithm for estimating the Sinkhorn divergence from finite samples generated by the two processes. For a fixed regularization parameter, the convergence rates are {\it dimension-independent} and of the same order as those for the Hilbert-Schmidt distance. If at least one of the RKHS is finite-dimensional, we obtain a {\it dimension-dependent} sample complexity for the exact Wasserstein distance between the Gaussian processes.
Convergence and finite sample approximations of entropic regularized Wasserstein distances in Gaussian and RKHS settings
Jan 05, 2021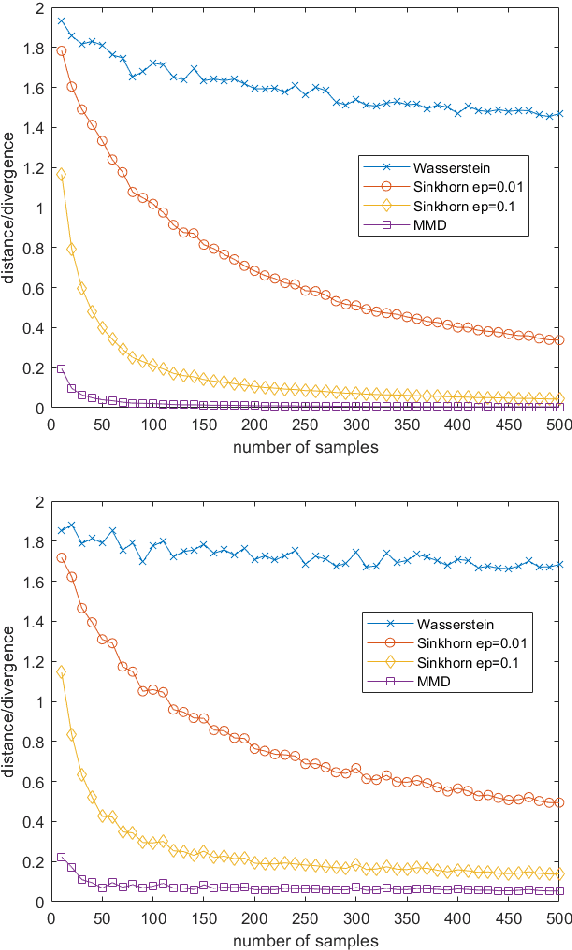
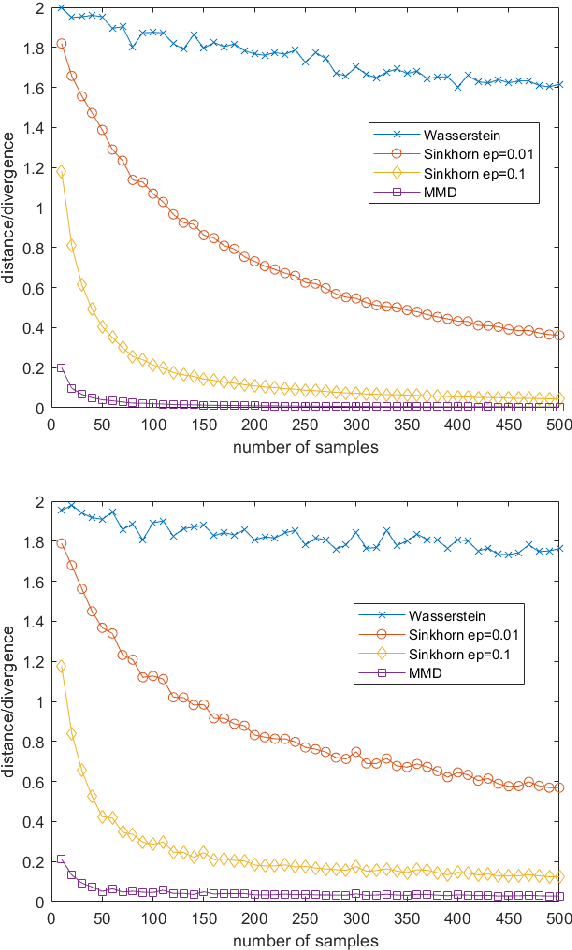
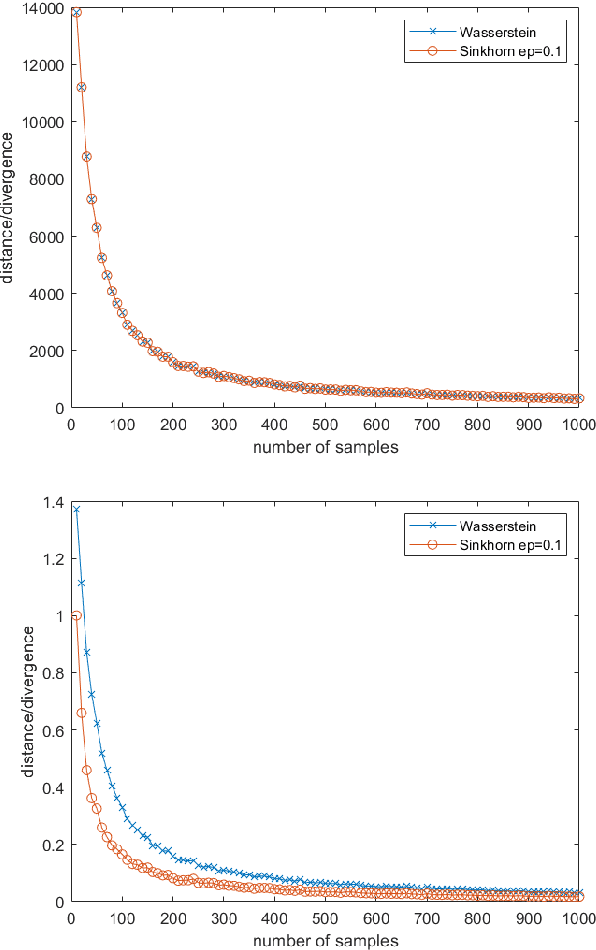
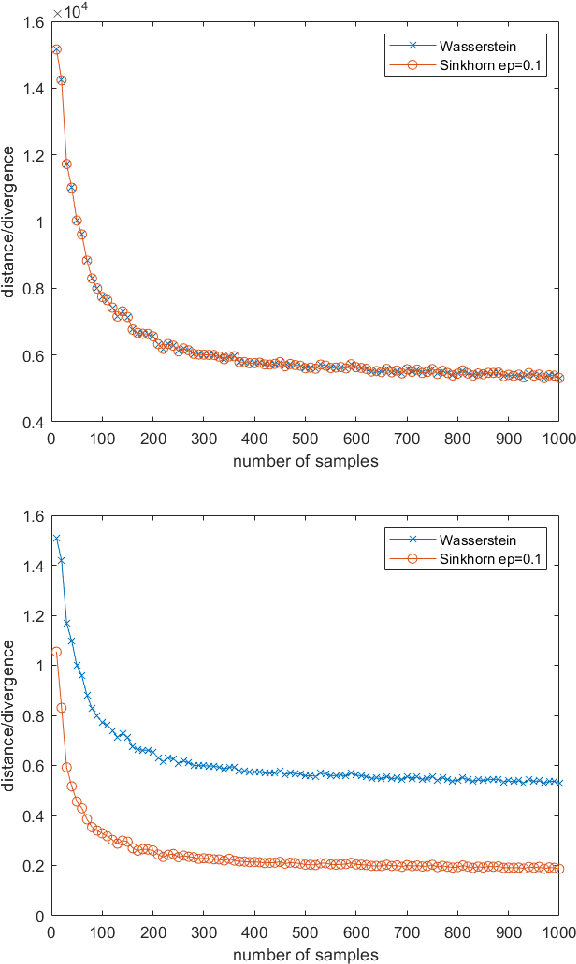
This work studies the convergence and finite sample approximations of entropic regularized Wasserstein distances in the Hilbert space setting. Our first main result is that for Gaussian measures on an infinite-dimensional Hilbert space, convergence in the 2-Sinkhorn divergence is {\it strictly weaker} than convergence in the exact 2-Wasserstein distance. Specifically, a sequence of centered Gaussian measures converges in the 2-Sinkhorn divergence if the corresponding covariance operators converge in the Hilbert-Schmidt norm. This is in contrast to the previous known result that a sequence of centered Gaussian measures converges in the exact 2-Wasserstein distance if and only if the covariance operators converge in the trace class norm. In the reproducing kernel Hilbert space (RKHS) setting, the {\it kernel Gaussian-Sinkhorn divergence}, which is the Sinkhorn divergence between Gaussian measures defined on an RKHS, defines a semi-metric on the set of Borel probability measures on a Polish space, given a characteristic kernel on that space. With the Hilbert-Schmidt norm convergence, we obtain {\it dimension-independent} convergence rates for finite sample approximations of the kernel Gaussian-Sinkhorn divergence, with the same order as the Maximum Mean Discrepancy. These convergence rates apply in particular to Sinkhorn divergence between Gaussian measures on Euclidean and infinite-dimensional Hilbert spaces. The sample complexity for the 2-Wasserstein distance between Gaussian measures on Euclidean space, while dimension-dependent and larger than that of the Sinkhorn divergence, is exponentially faster than the worst case scenario in the literature.
Entropic regularization of Wasserstein distance between infinite-dimensional Gaussian measures and Gaussian processes
Nov 15, 2020This work studies the entropic regularization formulation of the 2-Wasserstein distance on an infinite-dimensional Hilbert space, in particular for the Gaussian setting. We first present the Minimum Mutual Information property, namely the joint measures of two Gaussian measures on Hilbert space with the smallest mutual information are joint Gaussian measures. This is the infinite-dimensional generalization of the Maximum Entropy property of Gaussian densities on Euclidean space. We then give closed form formulas for the optimal entropic transport plan, 2-Wasserstein distance, and Sinkhorn divergence between two Gaussian measures on a Hilbert space, along with the fixed point equations for the barycenter of a set of Gaussian measures. Our formulations fully exploit the regularization aspect of the entropic formulation and are valid both in singular and nonsingular settings. In the infinite-dimensional setting, both the entropic 2-Wasserstein distance and Sinkhorn divergence are Fr\'echet differentiable, in contrast to the exact 2-Wasserstein distance, which is not differentiable. Our Sinkhorn barycenter equation is new and always has a unique solution. In contrast, the finite-dimensional barycenter equation for the entropic 2-Wasserstein distance fails to generalize to the Hilbert space setting. In the setting of reproducing kernel Hilbert spaces (RKHS), our distance formulas are given explicitly in terms of the corresponding kernel Gram matrices, providing an interpolation between the kernel Maximum Mean Discrepancy (MMD) and the kernel 2-Wasserstein distance.
Infinite-dimensional Log-Determinant divergences II: Alpha-Beta divergences
Jan 14, 2017This work presents a parametrized family of divergences, namely Alpha-Beta Log- Determinant (Log-Det) divergences, between positive definite unitized trace class operators on a Hilbert space. This is a generalization of the Alpha-Beta Log-Determinant divergences between symmetric, positive definite matrices to the infinite-dimensional setting. The family of Alpha-Beta Log-Det divergences is highly general and contains many divergences as special cases, including the recently formulated infinite dimensional affine-invariant Riemannian distance and the infinite-dimensional Alpha Log-Det divergences between positive definite unitized trace class operators. In particular, it includes a parametrized family of metrics between positive definite trace class operators, with the affine-invariant Riemannian distance and the square root of the symmetric Stein divergence being special cases. For the Alpha-Beta Log-Det divergences between covariance operators on a Reproducing Kernel Hilbert Space (RKHS), we obtain closed form formulas via the corresponding Gram matrices.
Scalable Matrix-valued Kernel Learning for High-dimensional Nonlinear Multivariate Regression and Granger Causality
Mar 08, 2013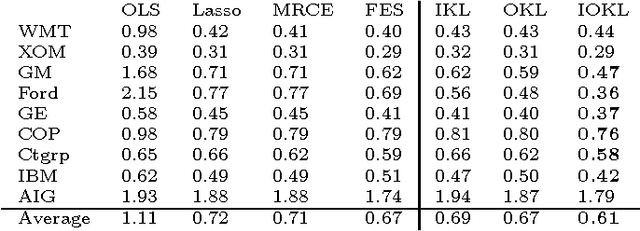

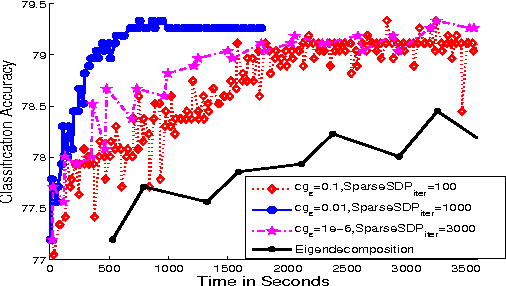
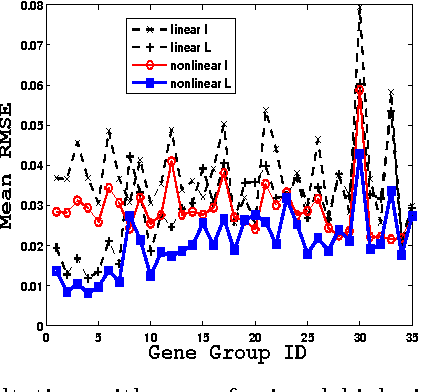
We propose a general matrix-valued multiple kernel learning framework for high-dimensional nonlinear multivariate regression problems. This framework allows a broad class of mixed norm regularizers, including those that induce sparsity, to be imposed on a dictionary of vector-valued Reproducing Kernel Hilbert Spaces. We develop a highly scalable and eigendecomposition-free algorithm that orchestrates two inexact solvers for simultaneously learning both the input and output components of separable matrix-valued kernels. As a key application enabled by our framework, we show how high-dimensional causal inference tasks can be naturally cast as sparse function estimation problems, leading to novel nonlinear extensions of a class of Graphical Granger Causality techniques. Our algorithmic developments and extensive empirical studies are complemented by theoretical analyses in terms of Rademacher generalization bounds.
Further properties of Gaussian Reproducing Kernel Hilbert Spaces
Oct 23, 2012We generalize the orthonormal basis for the Gaussian RKHS described in \cite{MinhGaussian2010} to an infinite, continuously parametrized, family of orthonormal bases, along with some implications. The proofs are direct generalizations of those in \cite{MinhGaussian2010}.