 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAV-DTEC: Self-Supervised Audio-Visual Fusion for Drone Trajectory Estimation and Classification
Dec 22, 2024



The increasing use of compact UAVs has created significant threats to public safety, while traditional drone detection systems are often bulky and costly. To address these challenges, we propose AV-DTEC, a lightweight self-supervised audio-visual fusion-based anti-UAV system. AV-DTEC is trained using self-supervised learning with labels generated by LiDAR, and it simultaneously learns audio and visual features through a parallel selective state-space model. With the learned features, a specially designed plug-and-play primary-auxiliary feature enhancement module integrates visual features into audio features for better robustness in cross-lighting conditions. To reduce reliance on auxiliary features and align modalities, we propose a teacher-student model that adaptively adjusts the weighting of visual features. AV-DTEC demonstrates exceptional accuracy and effectiveness in real-world multi-modality data. The code and trained models are publicly accessible on GitHub \url{https://github.com/AmazingDay1/AV-DETC}.
TAME: Temporal Audio-based Mamba for Enhanced Drone Trajectory Estimation and Classification
Dec 17, 2024



The increasing prevalence of compact UAVs has introduced significant risks to public safety, while traditional drone detection systems are often bulky and costly. To address these challenges, we present TAME, the Temporal Audio-based Mamba for Enhanced Drone Trajectory Estimation and Classification. This innovative anti-UAV detection model leverages a parallel selective state-space model to simultaneously capture and learn both the temporal and spectral features of audio, effectively analyzing propagation of sound. To further enhance temporal features, we introduce a Temporal Feature Enhancement Module, which integrates spectral features into temporal data using residual cross-attention. This enhanced temporal information is then employed for precise 3D trajectory estimation and classification. Our model sets a new standard of performance on the MMUAD benchmarks, demonstrating superior accuracy and effectiveness. The code and trained models are publicly available on GitHub \url{https://github.com/AmazingDay1/TAME}.
Multi-feature Reconstruction Network using Crossed-mask Restoration for Unsupervised Anomaly Detection
Apr 20, 2024



Unsupervised anomaly detection using only normal samples is of great significance for quality inspection in industrial manufacturing. Although existing reconstruction-based methods have achieved promising results, they still face two problems: poor distinguishable information in image reconstruction and well abnormal regeneration caused by model over-generalization ability. To overcome the above issues, we convert the image reconstruction into a combination of parallel feature restorations and propose a multi-feature reconstruction network, MFRNet, using crossed-mask restoration in this paper. Specifically, a multi-scale feature aggregator is first developed to generate more discriminative hierarchical representations of the input images from a pre-trained model. Subsequently, a crossed-mask generator is adopted to randomly cover the extracted feature map, followed by a restoration network based on the transformer structure for high-quality repair of the missing regions. Finally, a hybrid loss is equipped to guide model training and anomaly estimation, which gives consideration to both the pixel and structural similarity. Extensive experiments show that our method is highly competitive with or significantly outperforms other state-of-the-arts on four public available datasets and one self-made dataset.
Defect Transformer: An Efficient Hybrid Transformer Architecture for Surface Defect Detection
Jul 17, 2022
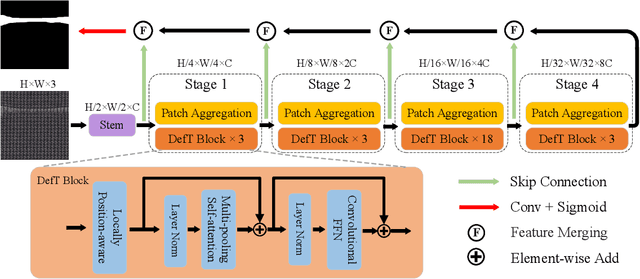
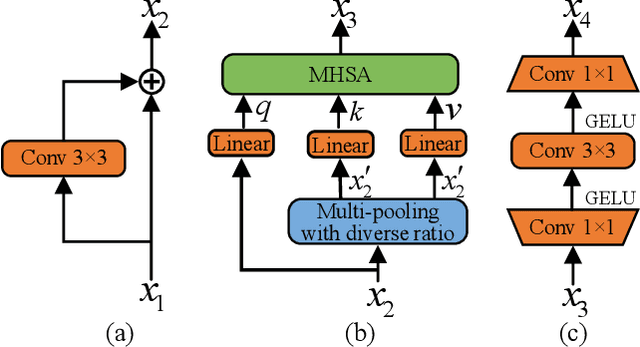
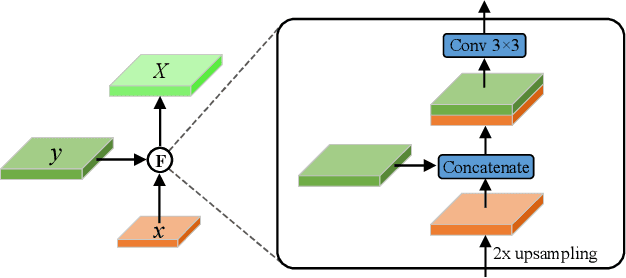
Surface defect detection is an extremely crucial step to ensure the quality of industrial products. Nowadays, convolutional neural networks (CNNs) based on encoder-decoder architecture have achieved tremendous success in various defect detection tasks. However, due to the intrinsic locality of convolution, they commonly exhibit a limitation in explicitly modeling long-range interactions, critical for pixel-wise defect detection in complex cases, e.g., cluttered background and illegible pseudo-defects. Recent transformers are especially skilled at learning global image dependencies but with limited local structural information necessary for detailed defect location. To overcome the above limitations, we propose an efficient hybrid transformer architecture, termed Defect Transformer (DefT), for surface defect detection, which incorporates CNN and transformer into a unified model to capture local and non-local relationships collaboratively. Specifically, in the encoder module, a convolutional stem block is firstly adopted to retain more detailed spatial information. Then, the patch aggregation blocks are used to generate multi-scale representation with four hierarchies, each of them is followed by a series of DefT blocks, which respectively include a locally position-aware block for local position encoding, a lightweight multi-pooling self-attention to model multi-scale global contextual relationships with good computational efficiency, and a convolutional feed-forward network for feature transformation and further location information learning. Finally, a simple but effective decoder module is proposed to gradually recover spatial details from the skip connections in the encoder. Extensive experiments on three datasets demonstrate the superiority and efficiency of our method compared with other CNN- and transformer-based networks.