 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Benchmark Democratization and Carpentry
Dec 12, 2025Benchmarks are a cornerstone of modern machine learning, enabling reproducibility, comparison, and scientific progress. However, AI benchmarks are increasingly complex, requiring dynamic, AI-focused workflows. Rapid evolution in model architectures, scale, datasets, and deployment contexts makes evaluation a moving target. Large language models often memorize static benchmarks, causing a gap between benchmark results and real-world performance. Beyond traditional static benchmarks, continuous adaptive benchmarking frameworks are needed to align scientific assessment with deployment risks. This calls for skills and education in AI Benchmark Carpentry. From our experience with MLCommons, educational initiatives, and programs like the DOE's Trillion Parameter Consortium, key barriers include high resource demands, limited access to specialized hardware, lack of benchmark design expertise, and uncertainty in relating results to application domains. Current benchmarks often emphasize peak performance on top-tier hardware, offering limited guidance for diverse, real-world scenarios. Benchmarking must become dynamic, incorporating evolving models, updated data, and heterogeneous platforms while maintaining transparency, reproducibility, and interpretability. Democratization requires both technical innovation and systematic education across levels, building sustained expertise in benchmark design and use. Benchmarks should support application-relevant comparisons, enabling informed, context-sensitive decisions. Dynamic, inclusive benchmarking will ensure evaluation keeps pace with AI evolution and supports responsible, reproducible, and accessible AI deployment. Community efforts can provide a foundation for AI Benchmark Carpentry.
An MLCommons Scientific Benchmarks Ontology
Nov 06, 2025



Scientific machine learning research spans diverse domains and data modalities, yet existing benchmark efforts remain siloed and lack standardization. This makes novel and transformative applications of machine learning to critical scientific use-cases more fragmented and less clear in pathways to impact. This paper introduces an ontology for scientific benchmarking developed through a unified, community-driven effort that extends the MLCommons ecosystem to cover physics, chemistry, materials science, biology, climate science, and more. Building on prior initiatives such as XAI-BENCH, FastML Science Benchmarks, PDEBench, and the SciMLBench framework, our effort consolidates a large set of disparate benchmarks and frameworks into a single taxonomy of scientific, application, and system-level benchmarks. New benchmarks can be added through an open submission workflow coordinated by the MLCommons Science Working Group and evaluated against a six-category rating rubric that promotes and identifies high-quality benchmarks, enabling stakeholders to select benchmarks that meet their specific needs. The architecture is extensible, supporting future scientific and AI/ML motifs, and we discuss methods for identifying emerging computing patterns for unique scientific workloads. The MLCommons Science Benchmarks Ontology provides a standardized, scalable foundation for reproducible, cross-domain benchmarking in scientific machine learning. A companion webpage for this work has also been developed as the effort evolves: https://mlcommons-science.github.io/benchmark/
An Overview of MLCommons Cloud Mask Benchmark: Related Research and Data
Dec 08, 2023Cloud masking is a crucial task that is well-motivated for meteorology and its applications in environmental and atmospheric sciences. Its goal is, given satellite images, to accurately generate cloud masks that identify each pixel in image to contain either cloud or clear sky. In this paper, we summarize some of the ongoing research activities in cloud masking, with a focus on the research and benchmark currently conducted in MLCommons Science Working Group. This overview is produced with the hope that others will have an easier time getting started and collaborate on the activities related to MLCommons Cloud Mask Benchmark.
In-depth Analysis On Parallel Processing Patterns for High-Performance Dataframes
Jul 03, 2023

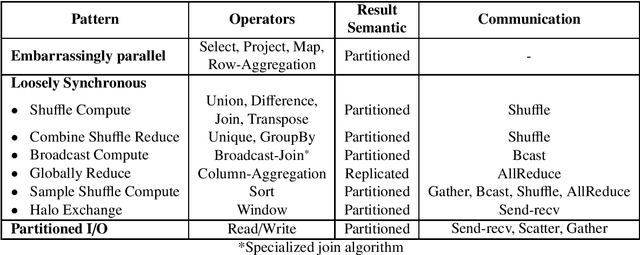

The Data Science domain has expanded monumentally in both research and industry communities during the past decade, predominantly owing to the Big Data revolution. Artificial Intelligence (AI) and Machine Learning (ML) are bringing more complexities to data engineering applications, which are now integrated into data processing pipelines to process terabytes of data. Typically, a significant amount of time is spent on data preprocessing in these pipelines, and hence improving its e fficiency directly impacts the overall pipeline performance. The community has recently embraced the concept of Dataframes as the de-facto data structure for data representation and manipulation. However, the most widely used serial Dataframes today (R, pandas) experience performance limitations while working on even moderately large data sets. We believe that there is plenty of room for improvement by taking a look at this problem from a high-performance computing point of view. In a prior publication, we presented a set of parallel processing patterns for distributed dataframe operators and the reference runtime implementation, Cylon [1]. In this paper, we are expanding on the initial concept by introducing a cost model for evaluating the said patterns. Furthermore, we evaluate the performance of Cylon on the ORNL Summit supercomputer.
Time Series Analysis of Blockchain-Based Cryptocurrency Price Changes
Feb 19, 2022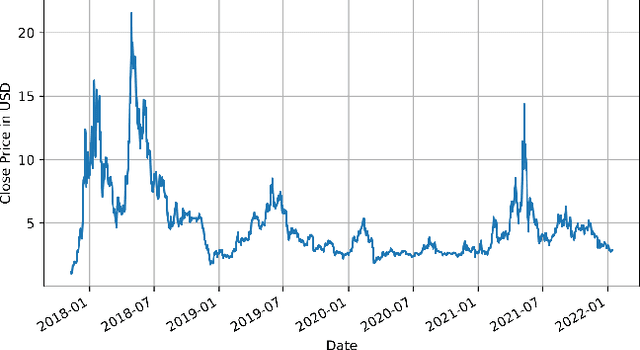
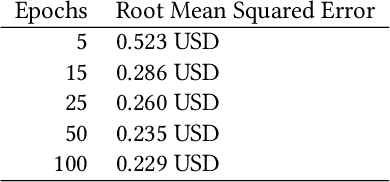
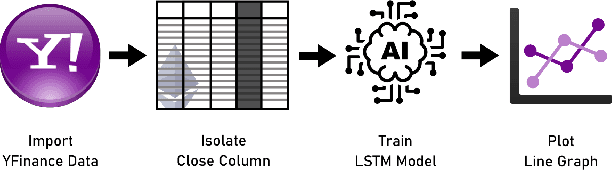

In this paper we apply neural networks and Artificial Intelligence (AI) to historical records of high-risk cryptocurrency coins to train a prediction model that guesses their price. This paper's code contains Jupyter notebooks, one of which outputs a timeseries graph of any cryptocurrency price once a CSV file of the historical data is inputted into the program. Another Jupyter notebook trains an LSTM, or a long short-term memory model, to predict a cryptocurrency's closing price. The LSTM is fed the close price, which is the price that the currency has at the end of the day, so it can learn from those values. The notebook creates two sets: a training set and a test set to assess the accuracy of the results. The data is then normalized using manual min-max scaling so that the model does not experience any bias; this also enhances the performance of the model. Then, the model is trained using three layers -- an LSTM, dropout, and dense layer-minimizing the loss through 50 epochs of training; from this training, a recurrent neural network (RNN) is produced and fitted to the training set. Additionally, a graph of the loss over each epoch is produced, with the loss minimizing over time. Finally, the notebook plots a line graph of the actual currency price in red and the predicted price in blue. The process is then repeated for several more cryptocurrencies to compare prediction models. The parameters for the LSTM, such as number of epochs and batch size, are tweaked to try and minimize the root mean square error.
HPTMT Parallel Operators for High Performance Data Science & Data Engineering
Aug 13, 2021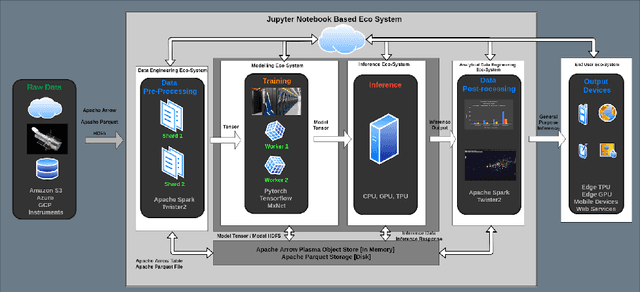


Data-intensive applications are becoming commonplace in all science disciplines. They are comprised of a rich set of sub-domains such as data engineering, deep learning, and machine learning. These applications are built around efficient data abstractions and operators that suit the applications of different domains. Often lack of a clear definition of data structures and operators in the field has led to other implementations that do not work well together. The HPTMT architecture that we proposed recently, identifies a set of data structures, operators, and an execution model for creating rich data applications that links all aspects of data engineering and data science together efficiently. This paper elaborates and illustrates this architecture using an end-to-end application with deep learning and data engineering parts working together.
HPTMT: Operator-Based Architecture for Scalable High-Performance Data-Intensive Frameworks
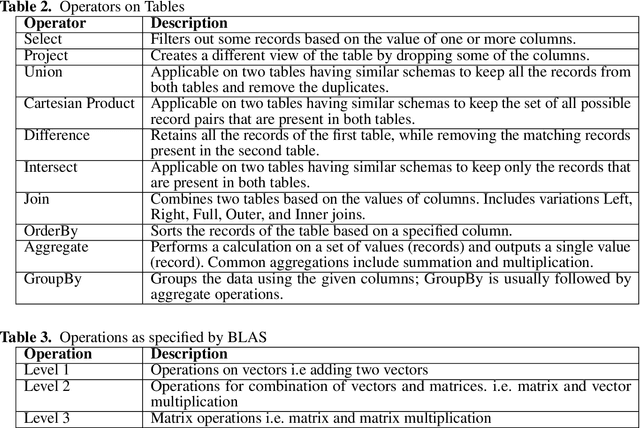
Jul 30, 2021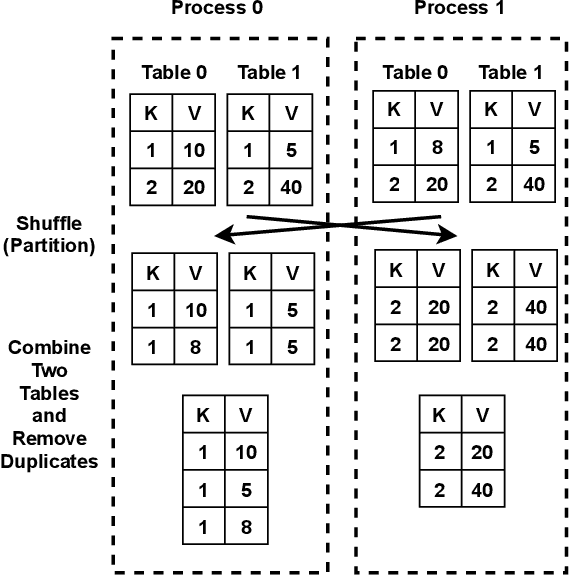
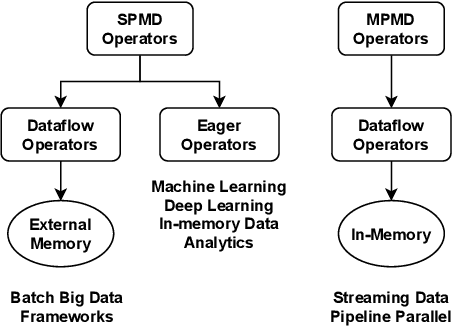
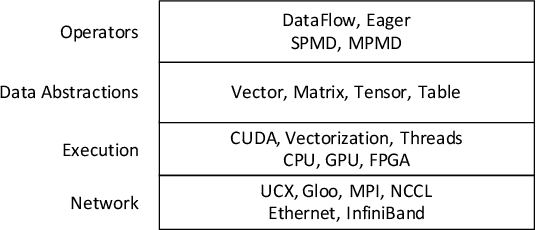
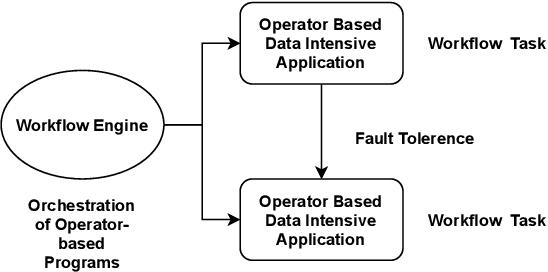
Data-intensive applications impact many domains, and their steadily increasing size and complexity demands high-performance, highly usable environments. We integrate a set of ideas developed in various data science and data engineering frameworks. They employ a set of operators on specific data abstractions that include vectors, matrices, tensors, graphs, and tables. Our key concepts are inspired from systems like MPI, HPF (High-Performance Fortran), NumPy, Pandas, Spark, Modin, PyTorch, TensorFlow, RAPIDS(NVIDIA), and OneAPI (Intel). Further, it is crucial to support different languages in everyday use in the Big Data arena, including Python, R, C++, and Java. We note the importance of Apache Arrow and Parquet for enabling language agnostic high performance and interoperability. In this paper, we propose High-Performance Tensors, Matrices and Tables (HPTMT), an operator-based architecture for data-intensive applications, and identify the fundamental principles needed for performance and usability success. We illustrate these principles by a discussion of examples using our software environments, Cylon and Twister2 that embody HPTMT.
AICov: An Integrative Deep Learning Framework for COVID-19 Forecasting with Population Covariates
Oct 08, 2020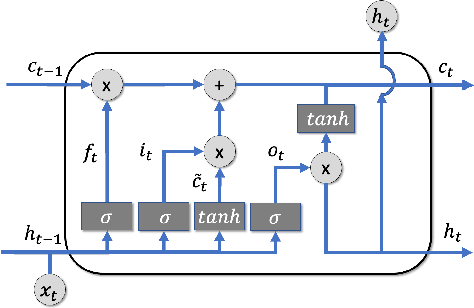

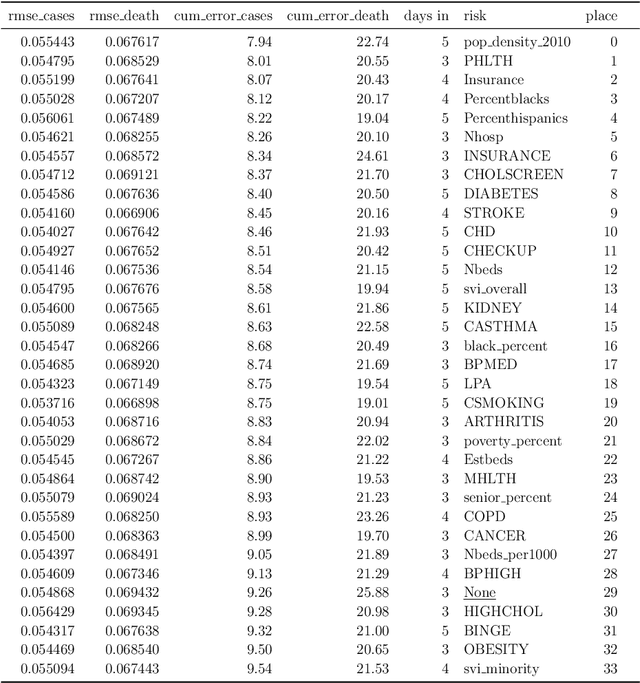
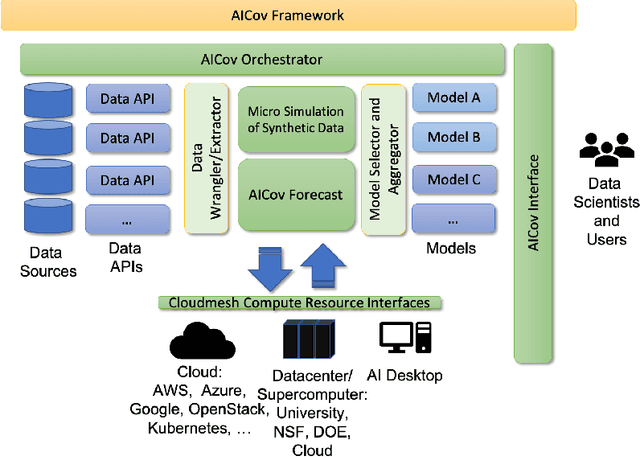
The COVID-19 pandemic has profound global consequences on health, economic, social, political, and almost every major aspect of human life. Therefore, it is of great importance to model COVID-19 and other pandemics in terms of the broader social contexts in which they take place. We present the architecture of AICov, which provides an integrative deep learning framework for COVID-19 forecasting with population covariates, some of which may serve as putative risk factors. We have integrated multiple different strategies into AICov, including the ability to use deep learning strategies based on LSTM and even modeling. To demonstrate our approach, we have conducted a pilot that integrates population covariates from multiple sources. Thus, AICov not only includes data on COVID-19 cases and deaths but, more importantly, the population's socioeconomic, health and behavioral risk factors at a local level. The compiled data are fed into AICov, and thus we obtain improved prediction by integration of the data to our model as compared to one that only uses case and death data.