 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnsemble of Generative and Discriminative Techniques for Sentiment Analysis of Movie Reviews
May 27, 2015

Sentiment analysis is a common task in natural language processing that aims to detect polarity of a text document (typically a consumer review). In the simplest settings, we discriminate only between positive and negative sentiment, turning the task into a standard binary classification problem. We compare several ma- chine learning approaches to this problem, and combine them to achieve the best possible results. We show how to use for this task the standard generative lan- guage models, which are slightly complementary to the state of the art techniques. We achieve strong results on a well-known dataset of IMDB movie reviews. Our results are easily reproducible, as we publish also the code needed to repeat the experiments. This should simplify further advance of the state of the art, as other researchers can combine their techniques with ours with little effort.
Better Mixing via Deep Representations
Jul 18, 2012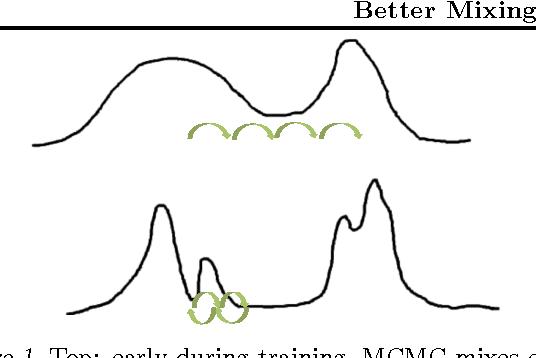


It has previously been hypothesized, and supported with some experimental evidence, that deeper representations, when well trained, tend to do a better job at disentangling the underlying factors of variation. We study the following related conjecture: better representations, in the sense of better disentangling, can be exploited to produce faster-mixing Markov chains. Consequently, mixing would be more efficient at higher levels of representation. To better understand why and how this is happening, we propose a secondary conjecture: the higher-level samples fill more uniformly the space they occupy and the high-density manifolds tend to unfold when represented at higher levels. The paper discusses these hypotheses and tests them experimentally through visualization and measurements of mixing and interpolating between samples.