 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Reconstruction of Stochastic Pedigrees
May 08, 2020
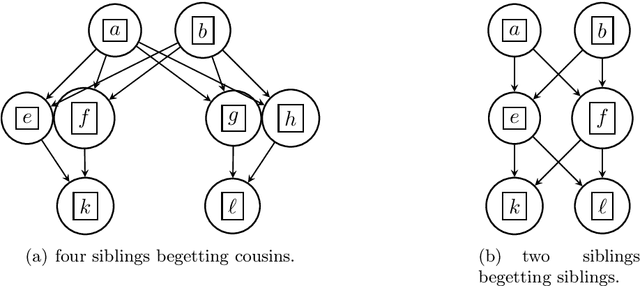
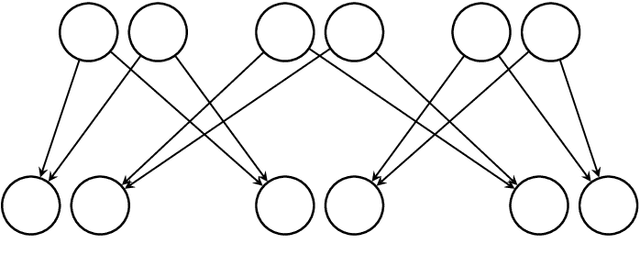
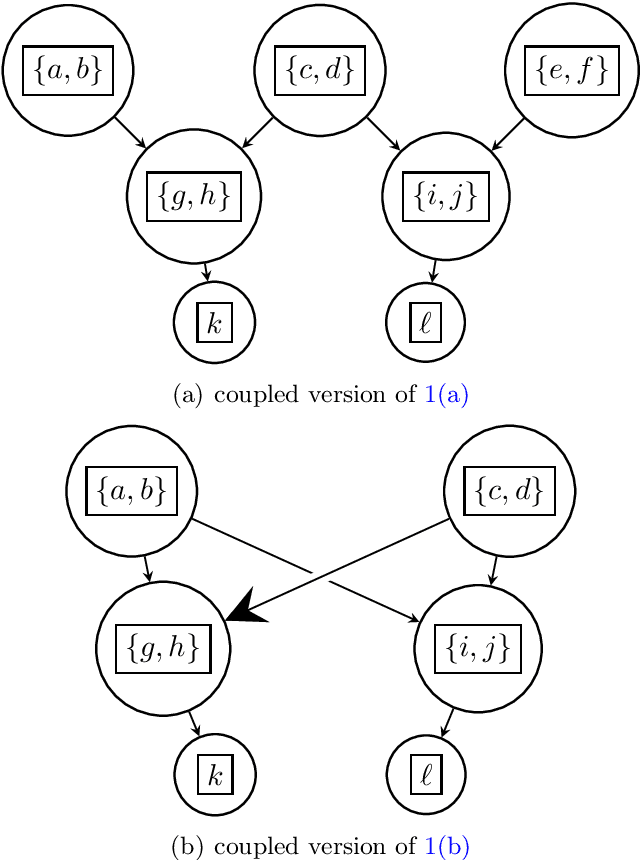
We introduce a new algorithm called {\sc Rec-Gen} for reconstructing the genealogy or \textit{pedigree} of an extant population purely from its genetic data. We justify our approach by giving a mathematical proof of the effectiveness of {\sc Rec-Gen} when applied to pedigrees from an idealized generative model that replicates some of the features of real-world pedigrees. Our algorithm is iterative and provides an accurate reconstruction of a large fraction of the pedigree while having relatively low \emph{sample complexity}, measured in terms of the length of the genetic sequences of the population. We propose our approach as a prototype for further investigation of the pedigree reconstruction problem toward the goal of applications to real-world examples. As such, our results have some conceptual bearing on the increasingly important issue of genomic privacy.
From Soft Classifiers to Hard Decisions: How fair can we be?
Oct 03, 2018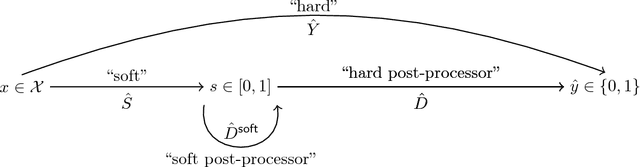
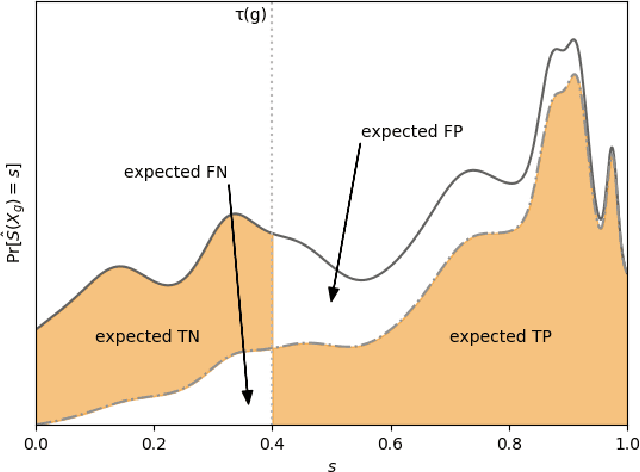
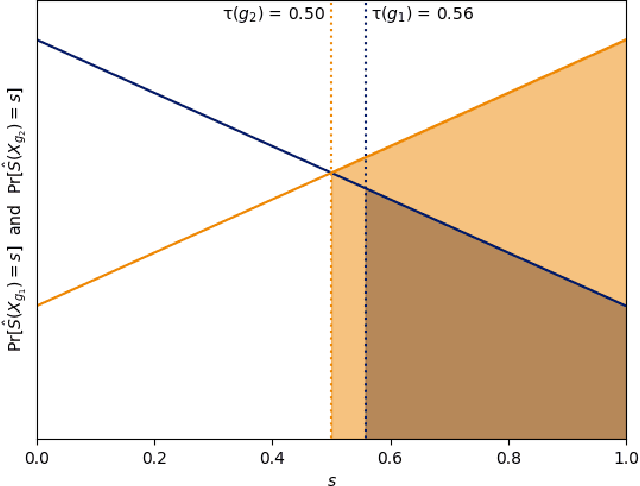
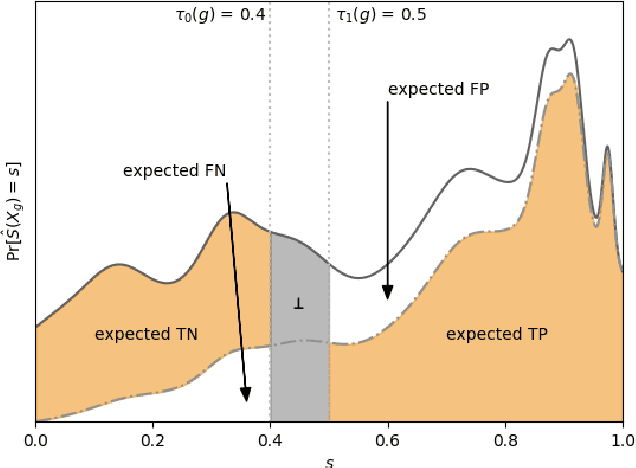
A popular methodology for building binary decision-making classifiers in the presence of imperfect information is to first construct a non-binary "scoring" classifier that is calibrated over all protected groups, and then to post-process this score to obtain a binary decision. We study the feasibility of achieving various fairness properties by post-processing calibrated scores, and then show that deferring post-processors allow for more fairness conditions to hold on the final decision. Specifically, we show: 1. There does not exist a general way to post-process a calibrated classifier to equalize protected groups' positive or negative predictive value (PPV or NPV). For certain "nice" calibrated classifiers, either PPV or NPV can be equalized when the post-processor uses different thresholds across protected groups, though there exist distributions of calibrated scores for which the two measures cannot be both equalized. When the post-processing consists of a single global threshold across all groups, natural fairness properties, such as equalizing PPV in a nontrivial way, do not hold even for "nice" classifiers. 2. When the post-processing is allowed to `defer' on some decisions (that is, to avoid making a decision by handing off some examples to a separate process), then for the non-deferred decisions, the resulting classifier can be made to equalize PPV, NPV, false positive rate (FPR) and false negative rate (FNR) across the protected groups. This suggests a way to partially evade the impossibility results of Chouldechova and Kleinberg et al., which preclude equalizing all of these measures simultaneously. We also present different deferring strategies and show how they affect the fairness properties of the overall system. We evaluate our post-processing techniques using the COMPAS data set from 2016.
Equalizing Financial Impact in Supervised Learning
Jun 24, 2018Notions of "fair classification" that have arisen in computer science generally revolve around equalizing certain statistics across protected groups. This approach has been criticized as ignoring societal issues, including how errors can hurt certain groups disproportionately. We pose a modification of one of the fairness criteria from Hardt, Price, and Srebro [NIPS, 2016] that makes a small step towards addressing this issue in the case of financial decisions like giving loans. We call this new notion "equalized financial impact."