 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModular and Adaptive Conformal Prediction for Sequential Models via Residual Decomposition
Oct 06, 2025Conformal prediction offers finite-sample coverage guarantees under minimal assumptions. However, existing methods treat the entire modeling process as a black box, overlooking opportunities to exploit modular structure. We introduce a conformal prediction framework for two-stage sequential models, where an upstream predictor generates intermediate representations for a downstream model. By decomposing the overall prediction residual into stage-specific components, our method enables practitioners to attribute uncertainty to specific pipeline stages. We develop a risk-controlled parameter selection procedure using family-wise error rate (FWER) control to calibrate stage-wise scaling parameters, and propose an adaptive extension for non-stationary settings that preserves long-run coverage guarantees. Experiments on synthetic distribution shifts, as well as real-world supply chain and stock market data, demonstrate that our approach maintains coverage under conditions that degrade standard conformal methods, while providing interpretable stage-wise uncertainty attribution. This framework offers diagnostic advantages and robust coverage that standard conformal methods lack.
Aligning Learning and Endogenous Decision-Making
Jul 01, 2025Many of the observations we make are biased by our decisions. For instance, the demand of items is impacted by the prices set, and online checkout choices are influenced by the assortments presented. The challenge in decision-making under this setting is the lack of counterfactual information, and the need to learn it instead. We introduce an end-to-end method under endogenous uncertainty to train ML models to be aware of their downstream, enabling their effective use in the decision-making stage. We further introduce a robust optimization variant that accounts for uncertainty in ML models -- specifically by constructing uncertainty sets over the space of ML models and optimizing actions to protect against worst-case predictions. We prove guarantees that this robust approach can capture near-optimal decisions with high probability as a function of data. Besides this, we also introduce a new class of two-stage stochastic optimization problems to the end-to-end learning framework that can now be addressed through our framework. Here, the first stage is an information-gathering problem to decide which random variable to poll and gain information about before making a second-stage decision based off of it. We present several computational experiments for pricing and inventory assortment/recommendation problems. We compare against existing methods in online learning/bandits/offline reinforcement learning and show our approach has consistent improved performance over these. Just as in the endogenous setting, the model's prediction also depends on the first-stage decision made. While this decision does not affect the random variable in this setting, it does affect the correct point forecast that should be made.
Causal LLM Routing: End-to-End Regret Minimization from Observational Data
May 21, 2025LLM routing aims to select the most appropriate model for each query, balancing competing performance metrics such as accuracy and cost across a pool of language models. Prior approaches typically adopt a decoupled strategy, where the metrics are first predicted and the model is then selected based on these estimates. This setup is prone to compounding errors and often relies on full-feedback data, where each query is evaluated by all candidate models, which is costly to obtain and maintain in practice. In contrast, we learn from observational data, which records only the outcome of the model actually deployed. We propose a causal end-to-end framework that learns routing policies by minimizing decision-making regret from observational data. To enable efficient optimization, we introduce two theoretically grounded surrogate objectives: a classification-based upper bound, and a softmax-weighted regret approximation shown to recover the optimal policy at convergence. We further extend our framework to handle heterogeneous cost preferences via an interval-conditioned architecture. Experiments on public benchmarks show that our method outperforms existing baselines, achieving state-of-the-art performance across different embedding models.
Efficient End-to-End Learning for Decision-Making: A Meta-Optimization Approach
May 16, 2025End-to-end learning has become a widely applicable and studied problem in training predictive ML models to be aware of their impact on downstream decision-making tasks. These end-to-end models often outperform traditional methods that separate training from the optimization and only myopically focus on prediction error. However, the computational complexity of end-to-end frameworks poses a significant challenge, particularly for large-scale problems. While training an ML model using gradient descent, each time we need to compute a gradient we must solve an expensive optimization problem. We present a meta-optimization method that learns efficient algorithms to approximate optimization problems, dramatically reducing computational overhead of solving the decision problem in general, an aspect we leverage in the training within the end-to-end framework. Our approach introduces a neural network architecture that near-optimally solves optimization problems while ensuring feasibility constraints through alternate projections. We prove exponential convergence, approximation guarantees, and generalization bounds for our learning method. This method offers superior computational efficiency, producing high-quality approximations faster and scaling better with problem size compared to existing techniques. Our approach applies to a wide range of optimization problems including deterministic, single-stage as well as two-stage stochastic optimization problems. We illustrate how our proposed method applies to (1) an electricity generation problem using real data from an electricity routing company coordinating the movement of electricity throughout 13 states, (2) a shortest path problem with a computer vision task of predicting edge costs from terrain maps, (3) a two-stage multi-warehouse cross-fulfillment newsvendor problem, as well as a variety of other newsvendor-like problems.
CoRe: Coherency Regularization for Hierarchical Time Series
Feb 21, 2025Hierarchical time series forecasting presents unique challenges, particularly when dealing with noisy data that may not perfectly adhere to aggregation constraints. This paper introduces a novel approach to soft coherency in hierarchical time series forecasting using neural networks. We present a network coherency regularization method, which we denote as CoRe (Coherency Regularization), a technique that trains neural networks to produce forecasts that are inherently coherent across hierarchies, without strictly enforcing aggregation constraints. Our method offers several key advantages. (1) It provides theoretical guarantees on the coherency of forecasts, even for out-of-sample data. (2) It is adaptable to scenarios where data may contain errors or missing values, making it more robust than strict coherency methods. (3) It can be easily integrated into existing neural network architectures for time series forecasting. We demonstrate the effectiveness of our approach on multiple benchmark datasets, comparing it against state-of-the-art methods in both coherent and noisy data scenarios. Additionally, our method can be used within existing generative probabilistic forecasting frameworks to generate coherent probabilistic forecasts. Our results show improved generalization and forecast accuracy, particularly in the presence of data inconsistencies. On a variety of datasets, including both strictly hierarchically coherent and noisy data, our training method has either equal or better accuracy at all levels of the hierarchy while being strictly more coherent out-of-sample than existing soft-coherency methods.
Inter-Series Transformer: Attending to Products in Time Series Forecasting
Aug 07, 2024Time series forecasting is an important task in many fields ranging from supply chain management to weather forecasting. Recently, Transformer neural network architectures have shown promising results in forecasting on common time series benchmark datasets. However, application to supply chain demand forecasting, which can have challenging characteristics such as sparsity and cross-series effects, has been limited. In this work, we explore the application of Transformer-based models to supply chain demand forecasting. In particular, we develop a new Transformer-based forecasting approach using a shared, multi-task per-time series network with an initial component applying attention across time series, to capture interactions and help address sparsity. We provide a case study applying our approach to successfully improve demand prediction for a medical device manufacturing company. To further validate our approach, we also apply it to public demand forecasting datasets as well and demonstrate competitive to superior performance compared to a variety of baseline and state-of-the-art forecast methods across the private and public datasets.
Heterogeneous Treatment Effects in Panel Data
Jun 09, 2024



We address a core problem in causal inference: estimating heterogeneous treatment effects using panel data with general treatment patterns. Many existing methods either do not utilize the potential underlying structure in panel data or have limitations in the allowable treatment patterns. In this work, we propose and evaluate a new method that first partitions observations into disjoint clusters with similar treatment effects using a regression tree, and then leverages the (assumed) low-rank structure of the panel data to estimate the average treatment effect for each cluster. Our theoretical results establish the convergence of the resulting estimates to the true treatment effects. Computation experiments with semi-synthetic data show that our method achieves superior accuracy compared to alternative approaches, using a regression tree with no more than 40 leaves. Hence, our method provides more accurate and interpretable estimates than alternative methods.
Tightness of prescriptive tree-based mixed-integer optimization formulations
Feb 28, 2023We focus on modeling the relationship between an input feature vector and the predicted outcome of a trained decision tree using mixed-integer optimization. This can be used in many practical applications where a decision tree or tree ensemble is incorporated into an optimization problem to model the predicted outcomes of a decision. We propose tighter mixed-integer optimization formulations than those previously introduced. Existing formulations can be shown to have linear relaxations that have fractional extreme points, even for the simple case of modeling a single decision tree. A formulation we propose, based on a projected union of polyhedra approach, is ideal for a single decision tree. While the formulation is generally not ideal for tree ensembles or if additional constraints are added, it generally has fewer extreme points, leading to a faster time to solve, particularly if the formulation has relatively few trees. However, previous work has shown that formulations based on a binary representation of the feature vector perform well computationally and hence are attractive for use in practical applications. We present multiple approaches to tighten existing formulations with binary vectors, and show that fractional extreme points are removed when there are multiple splits on the same feature. At an extreme, we prove that this results in ideal formulations for tree ensembles modeling a one-dimensional feature vector. Building on this result, we also show via numerical simulations that these additional constraints result in significantly tighter linear relaxations when the feature vector is low dimensional. We also present instances where the time to solve to optimality is significantly improved using these formulations.
Optimizing Objective Functions from Trained ReLU Neural Networks via Sampling
Jun 06, 2022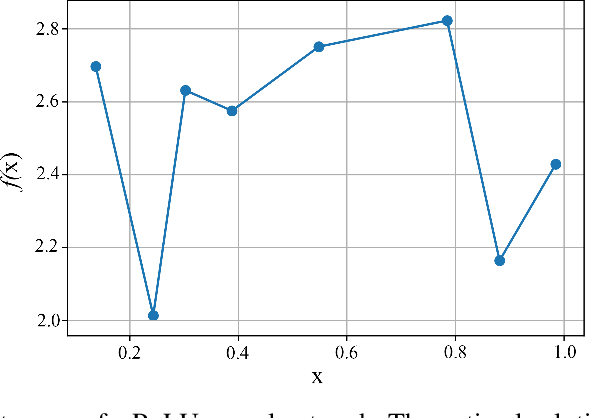
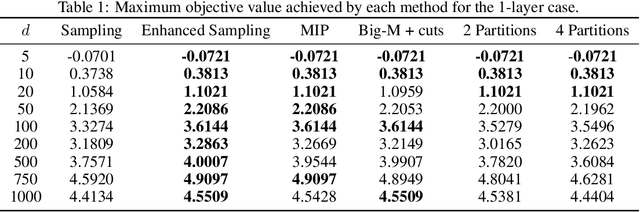
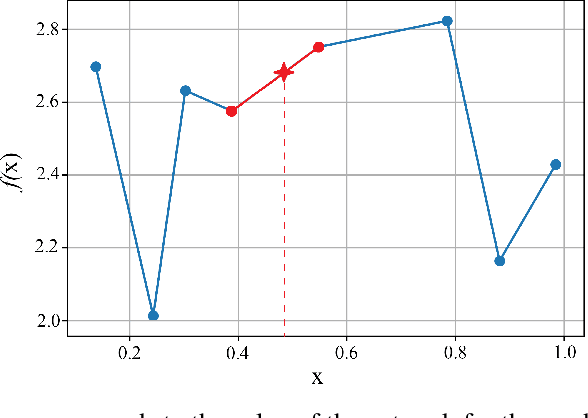
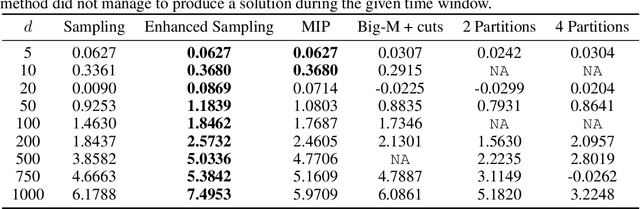
This paper introduces scalable, sampling-based algorithms that optimize trained neural networks with ReLU activations. We first propose an iterative algorithm that takes advantage of the piecewise linear structure of ReLU neural networks and reduces the initial mixed-integer optimization problem (MIP) into multiple easy-to-solve linear optimization problems (LPs) through sampling. Subsequently, we extend this approach by searching around the neighborhood of the LP solution computed at each iteration. This scheme allows us to devise a second, enhanced algorithm that reduces the initial MIP problem into smaller, easier-to-solve MIPs. We analytically show the convergence of the methods and we provide a sample complexity guarantee. We also validate the performance of our algorithms by comparing them against state-of-the-art MIP-based methods. Finally, we show computationally how the sampling algorithms can be used effectively to warm-start MIP-based methods.