 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Matching with Post-allocation Service and its Application to Refugee Resettlement
Oct 30, 2024

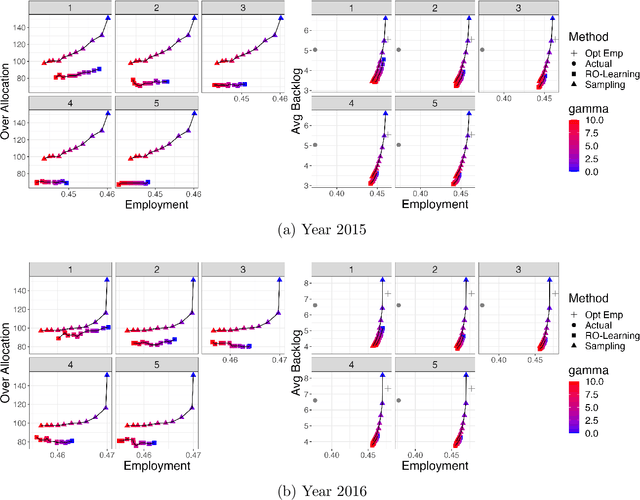
Motivated by our collaboration with a major refugee resettlement agency in the U.S., we study a dynamic matching problem where each new arrival (a refugee case) must be matched immediately and irrevocably to one of the static resources (a location with a fixed annual quota). In addition to consuming the static resource, each case requires post-allocation service from a server, such as a translator. Given the time-consuming nature of service, a server may not be available at a given time, thus we refer to it as a dynamic resource. Upon matching, the case will wait to avail service in a first-come-first-serve manner. Bursty matching to a location may result in undesirable congestion at its corresponding server. Consequently, the central planner (the agency) faces a dynamic matching problem with an objective that combines the matching reward (captured by pair-specific employment outcomes) with the cost for congestion for dynamic resources and over-allocation for the static ones. Motivated by the observed fluctuations in the composition of refugee pools across the years, we design algorithms that do not rely on distributional knowledge constructed based on past years' data. To that end, we develop learning-based algorithms that are asymptotically optimal in certain regimes, easy to interpret, and computationally fast. Our design is based on learning the dual variables of the underlying optimization problem; however, the main challenge lies in the time-varying nature of the dual variables associated with dynamic resources. To overcome this challenge, our theoretical development brings together techniques from Lyapunov analysis, adversarial online learning, and stochastic optimization. On the application side, when tested on real data from our partner agency, our method outperforms existing ones making it a viable candidate for replacing the current practice upon experimentation.
Heterogeneous Treatment Effects in Panel Data
Jun 09, 2024



We address a core problem in causal inference: estimating heterogeneous treatment effects using panel data with general treatment patterns. Many existing methods either do not utilize the potential underlying structure in panel data or have limitations in the allowable treatment patterns. In this work, we propose and evaluate a new method that first partitions observations into disjoint clusters with similar treatment effects using a regression tree, and then leverages the (assumed) low-rank structure of the panel data to estimate the average treatment effect for each cluster. Our theoretical results establish the convergence of the resulting estimates to the true treatment effects. Computation experiments with semi-synthetic data show that our method achieves superior accuracy compared to alternative approaches, using a regression tree with no more than 40 leaves. Hence, our method provides more accurate and interpretable estimates than alternative methods.
Random Distribution Shift in Refugee Placement: Strategies for Building Robust Models
Jun 05, 2023
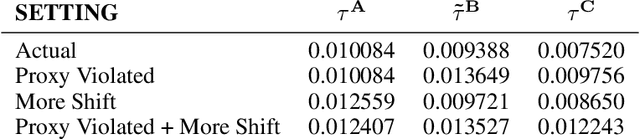


Algorithmic assignment of refugees and asylum seekers to locations within host countries has gained attention in recent years, with implementations in the US and Switzerland. These approaches use data on past arrivals to generate machine learning models that can be used (along with assignment algorithms) to match families to locations, with the goal of maximizing a policy-relevant integration outcome such as employment status after a certain duration. Existing implementations and research train models to predict the policy outcome directly, and use these predictions in the assignment procedure. However, the merits of this approach, particularly in non-stationary settings, has not been previously explored. This study proposes and compares three different modeling strategies: the standard approach described above, an approach that uses newer data and proxy outcomes, and a hybrid approach. We show that the hybrid approach is robust to both distribution shift and weak proxy relationships -- the failure points of the other two methods, respectively. We compare these approaches empirically using data on asylum seekers in the Netherlands. Surprisingly, we find that both the proxy and hybrid approaches out-perform the standard approach in practice. These insights support the development of a real-world recommendation tool currently used by NGOs and government agencies.