 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProjected Model Counting
Jul 28, 2015


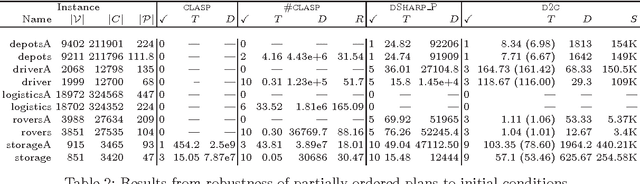
Model counting is the task of computing the number of assignments to variables V that satisfy a given propositional theory F. Model counting is an essential tool in probabilistic reasoning. In this paper, we introduce the problem of model counting projected on a subset P of original variables that we call 'priority' variables. The task is to compute the number of assignments to P such that there exists an extension to 'non-priority' variables V\P that satisfies F. Projected model counting arises when some parts of the model are irrelevant to the counts, in particular when we require additional variables to model the problem we are counting in SAT. We discuss three different approaches to projected model counting (two of which are novel), and compare their performance on different benchmark problems. To appear in 18th International Conference on Theory and Applications of Satisfiability Testing, September 24-27, 2015, Austin, Texas, USA
Stable Model Counting and Its Application in Probabilistic Logic Programming
Nov 20, 2014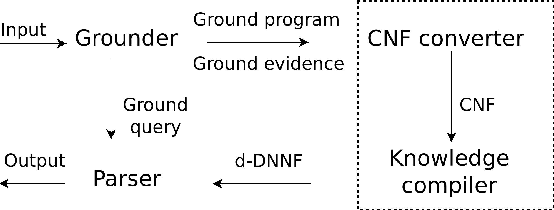
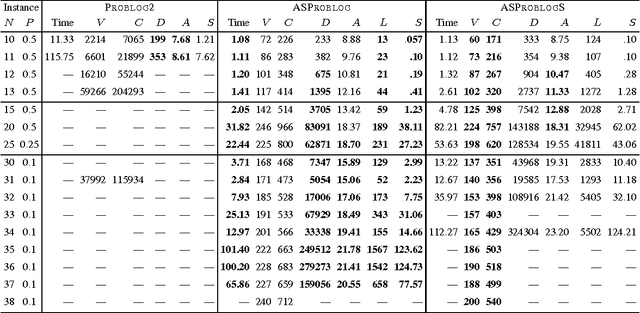
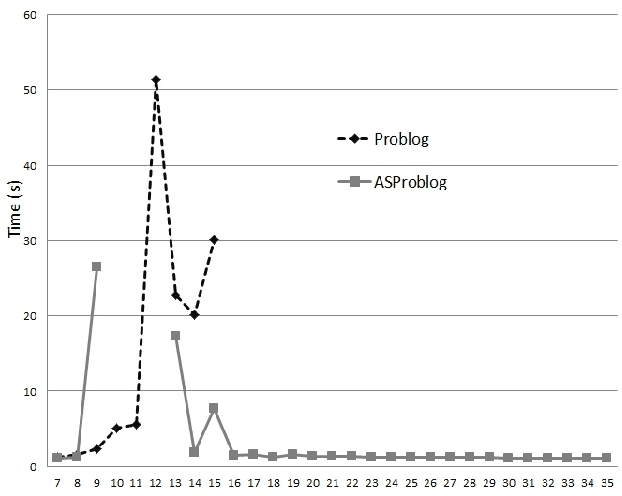
Model counting is the problem of computing the number of models that satisfy a given propositional theory. It has recently been applied to solving inference tasks in probabilistic logic programming, where the goal is to compute the probability of given queries being true provided a set of mutually independent random variables, a model (a logic program) and some evidence. The core of solving this inference task involves translating the logic program to a propositional theory and using a model counter. In this paper, we show that for some problems that involve inductive definitions like reachability in a graph, the translation of logic programs to SAT can be expensive for the purpose of solving inference tasks. For such problems, direct implementation of stable model semantics allows for more efficient solving. We present two implementation techniques, based on unfounded set detection, that extend a propositional model counter to a stable model counter. Our experiments show that for particular problems, our approach can outperform a state-of-the-art probabilistic logic programming solver by several orders of magnitude in terms of running time and space requirements, and can solve instances of significantly larger sizes on which the current solver runs out of time or memory.
Grounding Bound Founded Answer Set Programs
May 14, 2014
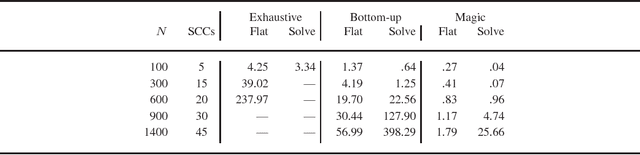
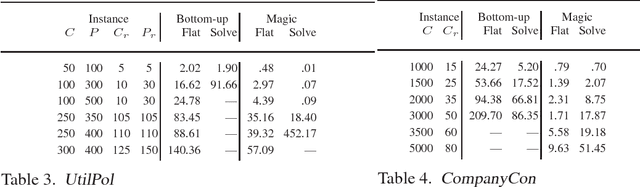
To appear in Theory and Practice of Logic Programming (TPLP) Bound Founded Answer Set Programming (BFASP) is an extension of Answer Set Programming (ASP) that extends stable model semantics to numeric variables. While the theory of BFASP is defined on ground rules, in practice BFASP programs are written as complex non-ground expressions. Flattening of BFASP is a technique used to simplify arbitrary expressions of the language to a small and well defined set of primitive expressions. In this paper, we first show how we can flatten arbitrary BFASP rule expressions, to give equivalent BFASP programs. Next, we extend the bottom-up grounding technique and magic set transformation used by ASP to BFASP programs. Our implementation shows that for BFASP problems, these techniques can significantly reduce the ground program size, and improve subsequent solving.
Structure Based Extended Resolution for Constraint Programming
Jun 19, 2013



Nogood learning is a powerful approach to reducing search in Constraint Programming (CP) solvers. The current state of the art, called Lazy Clause Generation (LCG), uses resolution to derive nogoods expressing the reasons for each search failure. Such nogoods can prune other parts of the search tree, producing exponential speedups on a wide variety of problems. Nogood learning solvers can be seen as resolution proof systems. The stronger the proof system, the faster it can solve a CP problem. It has recently been shown that the proof system used in LCG is at least as strong as general resolution. However, stronger proof systems such as \emph{extended resolution} exist. Extended resolution allows for literals expressing arbitrary logical concepts over existing variables to be introduced and can allow exponentially smaller proofs than general resolution. The primary problem in using extended resolution is to figure out exactly which literals are useful to introduce. In this paper, we show that we can use the structural information contained in a CP model in order to introduce useful literals, and that this can translate into significant speedups on a range of problems.