 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEncouraging Disentangled and Convex Representation with Controllable Interpolation Regularization
Dec 06, 2021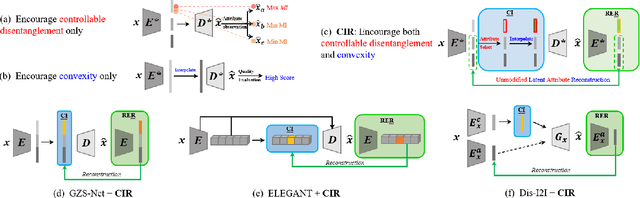
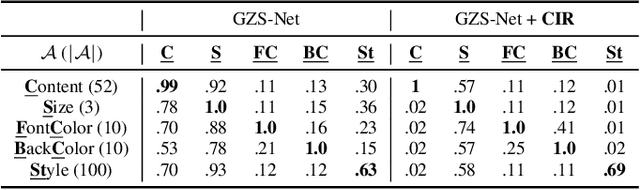

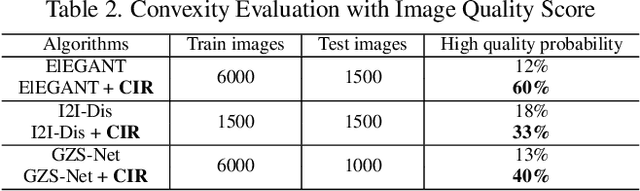
We focus on controllable disentangled representation learning (C-Dis-RL), where users can control the partition of the disentangled latent space to factorize dataset attributes (concepts) for downstream tasks. Two general problems remain under-explored in current methods: (1) They lack comprehensive disentanglement constraints, especially missing the minimization of mutual information between different attributes across latent and observation domains. (2) They lack convexity constraints in disentangled latent space, which is important for meaningfully manipulating specific attributes for downstream tasks. To encourage both comprehensive C-Dis-RL and convexity simultaneously, we propose a simple yet efficient method: Controllable Interpolation Regularization (CIR), which creates a positive loop where the disentanglement and convexity can help each other. Specifically, we conduct controlled interpolation in latent space during training and 'reuse' the encoder to help form a 'perfect disentanglement' regularization. In that case, (a) disentanglement loss implicitly enlarges the potential 'understandable' distribution to encourage convexity; (b) convexity can in turn improve robust and precise disentanglement. CIR is a general module and we merge CIR with three different algorithms: ELEGANT, I2I-Dis, and GZS-Net to show the compatibility and effectiveness. Qualitative and quantitative experiments show improvement in C-Dis-RL and latent convexity by CIR. This further improves downstream tasks: controllable image synthesis, cross-modality image translation and zero-shot synthesis. More experiments demonstrate CIR can also improve other downstream tasks, such as new attribute value mining, data augmentation, and eliminating bias for fairness.
Zero-shot Synthesis with Group-Supervised Learning
Sep 14, 2020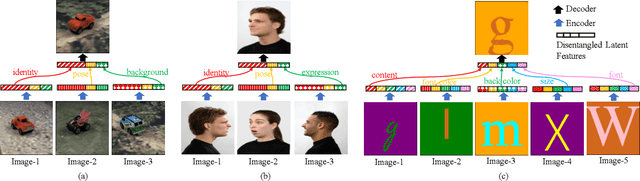
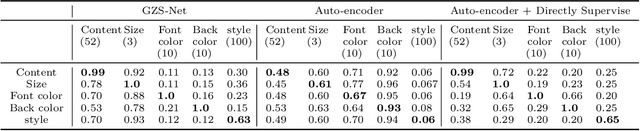
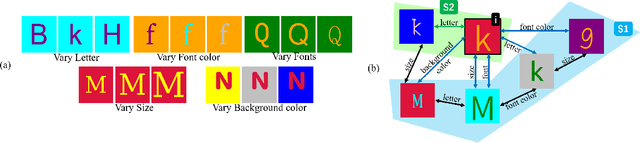
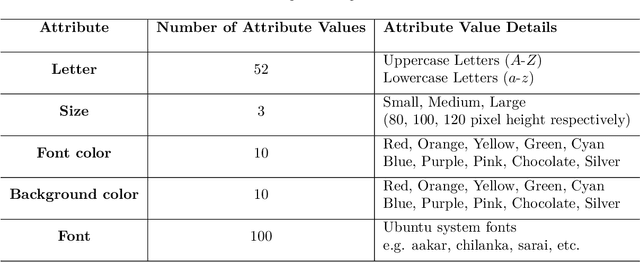
Visual cognition of primates is superior to that of artificial neural networks in its ability to 'envision' a visual object, even a newly-introduced one, in different attributes including pose, position, color, texture, etc. To aid neural networks to envision objects with different attributes, we propose a family of objective functions, expressed on groups of examples, as a novel learning framework that we term Group-Supervised Learning (GSL). GSL decomposes inputs into a disentangled representation with swappable components that can be recombined to synthesize new samples, trained through similarity mining within groups of exemplars. For instance, images of red boats & blue cars can be decomposed and recombined to synthesize novel images of red cars. We describe a general class of datasets admissible by GSL. We propose an implementation based on auto-encoder, termed group-supervised zero-shot synthesis network (GZS-Net) trained with our learning framework, that can produce a high-quality red car even if no such example is witnessed during training. We test our model and learning framework on existing benchmarks, in addition to new dataset that we open-source. We qualitatively and quantitatively demonstrate that GZS-Net trained with GSL outperforms state-of-the-art methods