 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-shot Synthesis with Group-Supervised Learning
Paper and Code
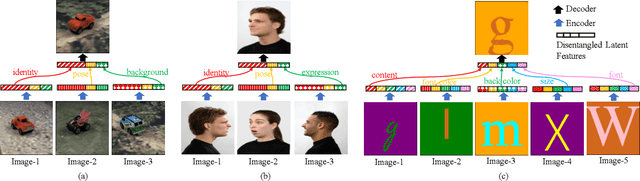
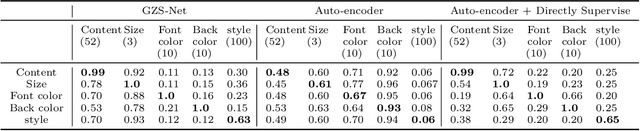
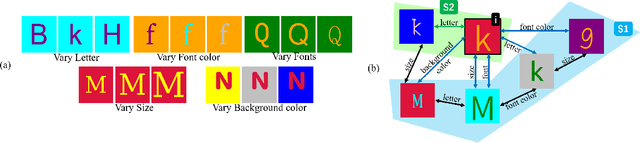
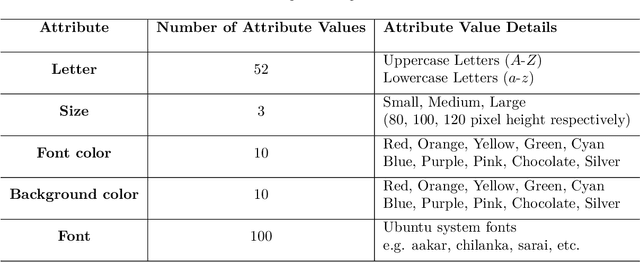
Visual cognition of primates is superior to that of artificial neural networks in its ability to 'envision' a visual object, even a newly-introduced one, in different attributes including pose, position, color, texture, etc. To aid neural networks to envision objects with different attributes, we propose a family of objective functions, expressed on groups of examples, as a novel learning framework that we term Group-Supervised Learning (GSL). GSL decomposes inputs into a disentangled representation with swappable components that can be recombined to synthesize new samples, trained through similarity mining within groups of exemplars. For instance, images of red boats & blue cars can be decomposed and recombined to synthesize novel images of red cars. We describe a general class of datasets admissible by GSL. We propose an implementation based on auto-encoder, termed group-supervised zero-shot synthesis network (GZS-Net) trained with our learning framework, that can produce a high-quality red car even if no such example is witnessed during training. We test our model and learning framework on existing benchmarks, in addition to new dataset that we open-source. We qualitatively and quantitatively demonstrate that GZS-Net trained with GSL outperforms state-of-the-art methods