 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOriented-grid Encoder for 3D Implicit Representations
Feb 09, 2024



Encoding 3D points is one of the primary steps in learning-based implicit scene representation. Using features that gather information from neighbors with multi-resolution grids has proven to be the best geometric encoder for this task. However, prior techniques do not exploit some characteristics of most objects or scenes, such as surface normals and local smoothness. This paper is the first to exploit those 3D characteristics in 3D geometric encoders explicitly. In contrast to prior work on using multiple levels of details, regular cube grids, and trilinear interpolation, we propose 3D-oriented grids with a novel cylindrical volumetric interpolation for modeling local planar invariance. In addition, we explicitly include a local feature aggregation for feature regularization and smoothing of the cylindrical interpolation features. We evaluate our approach on ABC, Thingi10k, ShapeNet, and Matterport3D, for object and scene representation. Compared to the use of regular grids, our geometric encoder is shown to converge in fewer steps and obtain sharper 3D surfaces. When compared to the prior techniques, our method gets state-of-the-art results.
3DRegNet: A Deep Neural Network for 3D Point Registration
Apr 02, 2019



We present 3DRegNet, a deep learning algorithm for the registration of 3D scans. With the recent emergence of inexpensive 3D commodity sensors, it would be beneficial to develop a learning based 3D registration algorithm. Given a set of 3D point correspondences, we build a deep neural network using deep residual layers and convolutional layers to achieve two tasks: (1) classification of the point correspondences into correct/incorrect ones, and (2) regression of the motion parameters that can align the scans into a common reference frame. 3DRegNet has several advantages over classical methods. First, since 3DRegNet works on point correspondences and not on the original scans, our approach is significantly faster than many conventional approaches. Second, we show that the algorithm can be extended for multi-view scenarios, i.e., simultaneous handling of the registration for more than two scans. In contrast to pose regression networks that employ four variables to represent rotation using quaternions, we use Lie algebra to represent the rotation using only three variables. Extensive experiments on two challenging datasets (i.e. ICL-NUIM and SUN3D) demonstrate that we outperform other methods and achieve state-of-the-art results. The code will be made available.
OmniDRL: Robust Pedestrian Detection using Deep Reinforcement Learning on Omnidirectional Cameras
Mar 02, 2019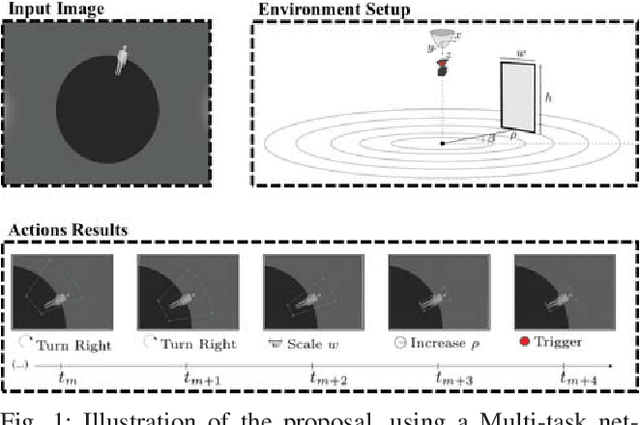
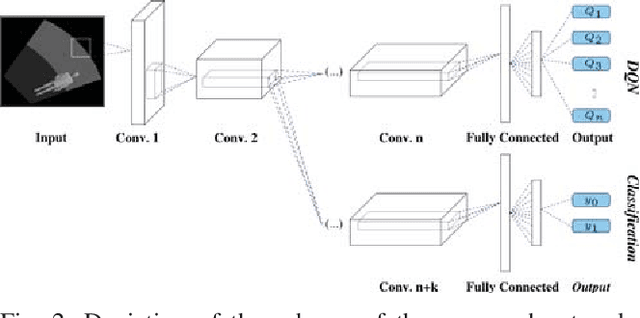
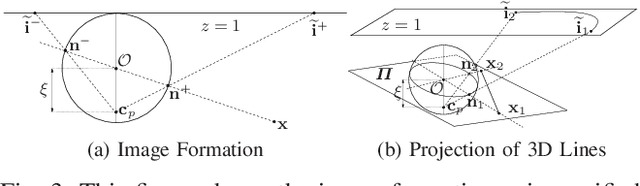

Pedestrian detection is one of the most explored topics in computer vision and robotics. The use of deep learning methods allowed the development of new and highly competitive algorithms. Deep Reinforcement Learning has proved to be within the state-of-the-art in terms of both detection in perspective cameras and robotics applications. However, for detection in omnidirectional cameras, the literature is still scarce, mostly because of their high levels of distortion. This paper presents a novel and efficient technique for robust pedestrian detection in omnidirectional images. The proposed method uses deep Reinforcement Learning that takes advantage of the distortion in the image. By considering the 3D bounding boxes and their distorted projections into the image, our method is able to provide the pedestrian's position in the world, in contrast to the image positions provided by most state-of-the-art methods for perspective cameras. Our method avoids the need of pre-processing steps to remove the distortion, which is computationally expensive. Beyond the novel solution, our method compares favorably with the state-of-the-art methodologies that do not consider the underlying distortion for the detection task.