 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoMeSci- A 5 Star Open Data Gold Standard Knowledge Graph of Software Mentions in Scientific Articles
Aug 20, 2021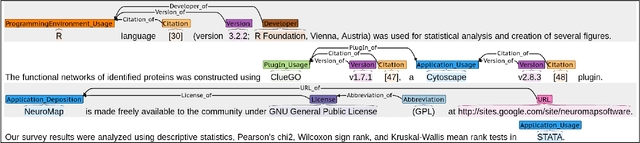
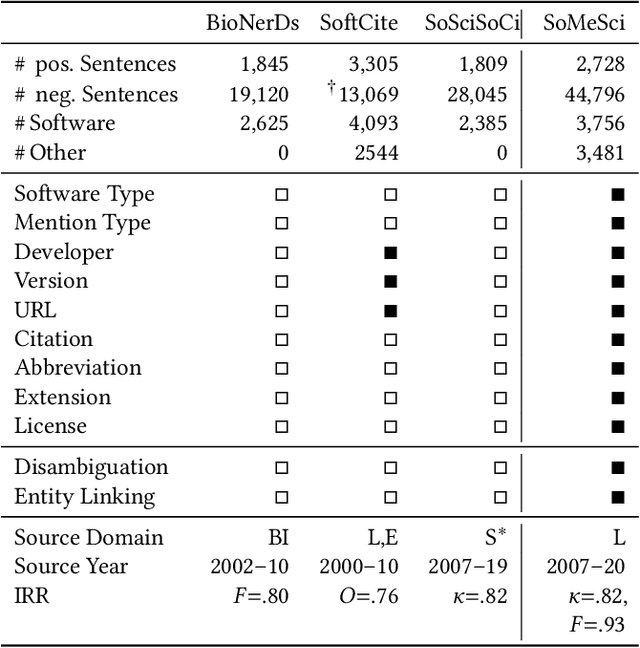
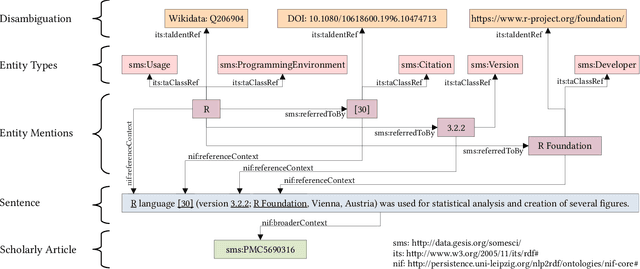

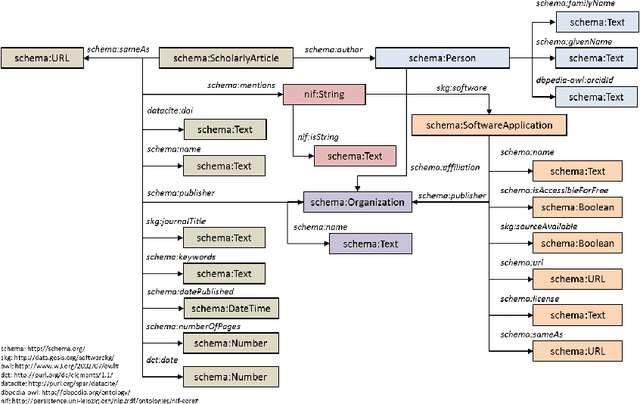
Knowledge about software used in scientific investigations is important for several reasons, for instance, to enable an understanding of provenance and methods involved in data handling. However, software is usually not formally cited, but rather mentioned informally within the scholarly description of the investigation, raising the need for automatic information extraction and disambiguation. Given the lack of reliable ground truth data, we present SoMeSci (Software Mentions in Science) a gold standard knowledge graph of software mentions in scientific articles. It contains high quality annotations (IRR: $\kappa{=}.82$) of 3756 software mentions in 1367 PubMed Central articles. Besides the plain mention of the software, we also provide relation labels for additional information, such as the version, the developer, a URL or citations. Moreover, we distinguish between different types, such as application, plugin or programming environment, as well as different types of mentions, such as usage or creation. To the best of our knowledge, SoMeSci is the most comprehensive corpus about software mentions in scientific articles, providing training samples for Named Entity Recognition, Relation Extraction, Entity Disambiguation, and Entity Linking. Finally, we sketch potential use cases and provide baseline results.
Investigating Software Usage in the Social Sciences: A Knowledge Graph Approach
Mar 24, 2020

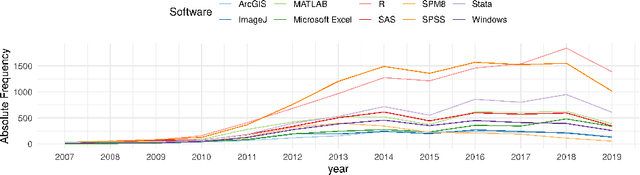
Knowledge about the software used in scientific investigations is necessary for different reasons, including provenance of the results, measuring software impact to attribute developers, and bibliometric software citation analysis in general. Additionally, providing information about whether and how the software and the source code are available allows an assessment about the state and role of open source software in science in general. While such analyses can be done manually, large scale analyses require the application of automated methods of information extraction and linking. In this paper, we present SoftwareKG - a knowledge graph that contains information about software mentions from more than 51,000 scientific articles from the social sciences. A silver standard corpus, created by a distant and weak supervision approach, and a gold standard corpus, created by manual annotation, were used to train an LSTM based neural network to identify software mentions in scientific articles. The model achieves a recognition rate of .82 F-score in exact matches. As a result, we identified more than 133,000 software mentions. For entity disambiguation, we used the public domain knowledge base DBpedia. Furthermore, we linked the entities of the knowledge graph to other knowledge bases such as the Microsoft Academic Knowledge Graph, the Software Ontology, and Wikidata. Finally, we illustrate, how SoftwareKG can be used to assess the role of software in the social sciences.
State-Space Abstractions for Probabilistic Inference: A Systematic Review
Apr 23, 2018

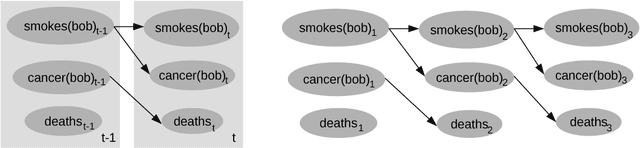

Tasks such as social network analysis, human behavior recognition, or modeling biochemical reactions, can be solved elegantly by using the probabilistic inference framework. However, standard probabilistic inference algorithms work at a propositional level, and thus cannot capture the symmetries and redundancies that are present in these tasks. Algorithms that exploit those symmetries have been devised in different research fields, for example by the lifted inference-, multiple object tracking-, and modeling and simulation-communities. The common idea, that we call state space abstraction, is to perform inference over compact representations of sets of symmetric states. Although they are concerned with a similar topic, the relationship between these approaches has not been investigated systematically. This survey provides the following contributions. We perform a systematic literature review to outline the state of the art in probabilistic inference methods exploiting symmetries. From an initial set of more than 4,000 papers, we identify 116 relevant papers. Furthermore, we provide new high-level categories that classify the approaches, based on the problem classes the different approaches can solve. Researchers from different fields that are confronted with a state space explosion problem in a probabilistic system can use this classification to identify possible solutions. Finally, based on this conceptualization, we identify potentials for future research, as some relevant application domains are not addressed by current approaches.
Sequential Lifted Bayesian Filtering in Multiset Rewriting Systems
Aug 14, 2017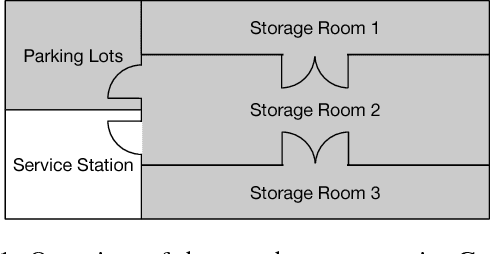
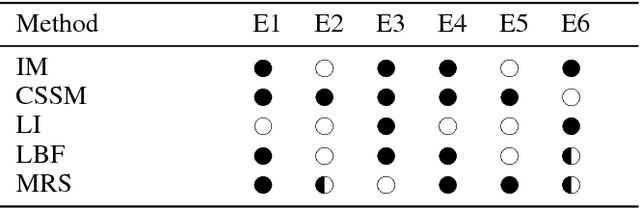
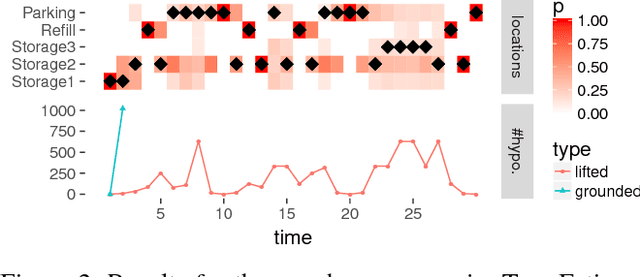
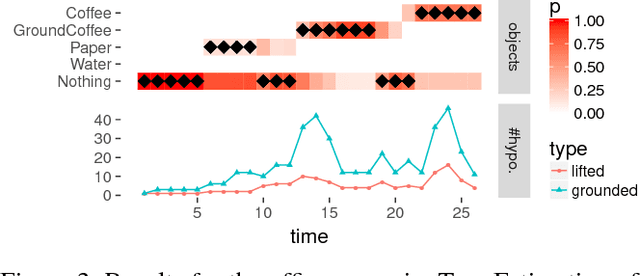
Bayesian Filtering for plan and activity recognition is challenging for scenarios that contain many observation equivalent entities (i.e. entities that produce the same observations). This is due to the combinatorial explosion in the number of hypotheses that need to be tracked. However, this class of problems exhibits a certain symmetry that can be exploited for state space representation and inference. We analyze current state of the art methods and find that none of them completely fits the requirements arising in this problem class. We sketch a novel inference algorithm that provides a solution by incorporating concepts from Lifted Inference algorithms, Probabilistic Multiset Rewriting Systems, and Computational State Space Models. Two experiments confirm that this novel algorithm has the potential to perform efficient probabilistic inference on this problem class.