 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoMeSci- A 5 Star Open Data Gold Standard Knowledge Graph of Software Mentions in Scientific Articles
Aug 20, 2021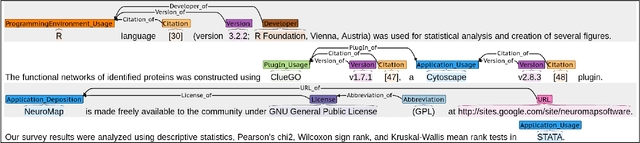
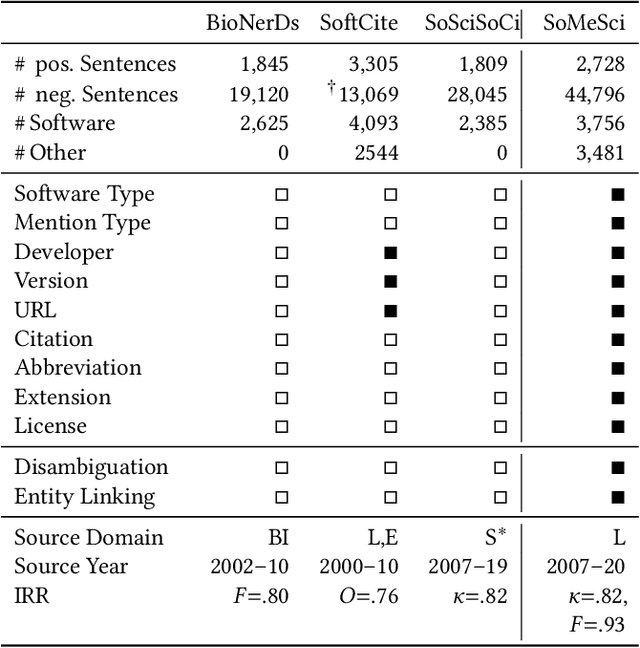
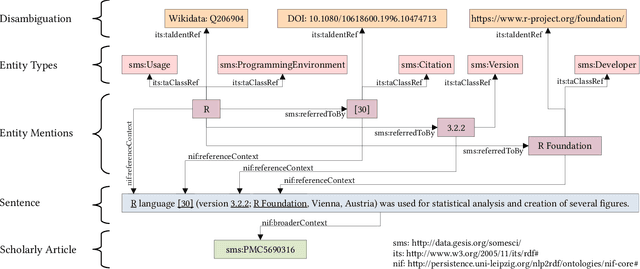

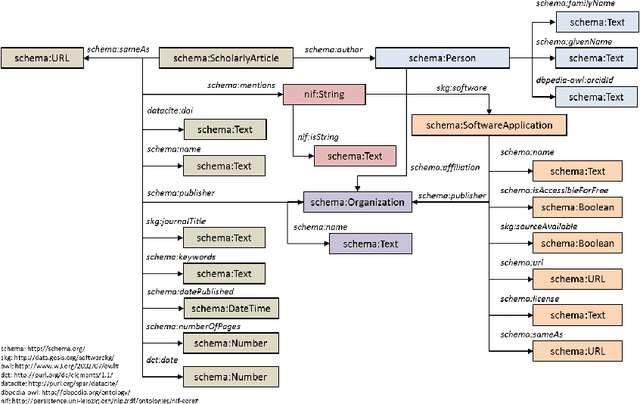
Knowledge about software used in scientific investigations is important for several reasons, for instance, to enable an understanding of provenance and methods involved in data handling. However, software is usually not formally cited, but rather mentioned informally within the scholarly description of the investigation, raising the need for automatic information extraction and disambiguation. Given the lack of reliable ground truth data, we present SoMeSci (Software Mentions in Science) a gold standard knowledge graph of software mentions in scientific articles. It contains high quality annotations (IRR: $\kappa{=}.82$) of 3756 software mentions in 1367 PubMed Central articles. Besides the plain mention of the software, we also provide relation labels for additional information, such as the version, the developer, a URL or citations. Moreover, we distinguish between different types, such as application, plugin or programming environment, as well as different types of mentions, such as usage or creation. To the best of our knowledge, SoMeSci is the most comprehensive corpus about software mentions in scientific articles, providing training samples for Named Entity Recognition, Relation Extraction, Entity Disambiguation, and Entity Linking. Finally, we sketch potential use cases and provide baseline results.
Investigating Software Usage in the Social Sciences: A Knowledge Graph Approach
Mar 24, 2020

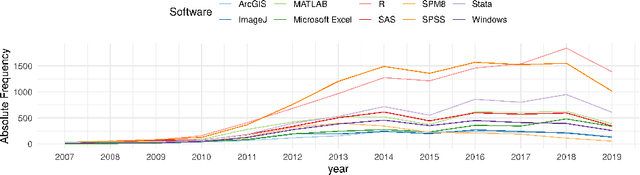
Knowledge about the software used in scientific investigations is necessary for different reasons, including provenance of the results, measuring software impact to attribute developers, and bibliometric software citation analysis in general. Additionally, providing information about whether and how the software and the source code are available allows an assessment about the state and role of open source software in science in general. While such analyses can be done manually, large scale analyses require the application of automated methods of information extraction and linking. In this paper, we present SoftwareKG - a knowledge graph that contains information about software mentions from more than 51,000 scientific articles from the social sciences. A silver standard corpus, created by a distant and weak supervision approach, and a gold standard corpus, created by manual annotation, were used to train an LSTM based neural network to identify software mentions in scientific articles. The model achieves a recognition rate of .82 F-score in exact matches. As a result, we identified more than 133,000 software mentions. For entity disambiguation, we used the public domain knowledge base DBpedia. Furthermore, we linked the entities of the knowledge graph to other knowledge bases such as the Microsoft Academic Knowledge Graph, the Software Ontology, and Wikidata. Finally, we illustrate, how SoftwareKG can be used to assess the role of software in the social sciences.