 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAblation Studies for Novel Treatment Effect Estimation Models
Oct 21, 2024



Ablation studies are essential for understanding the contribution of individual components within complex models, yet their application in nonparametric treatment effect estimation remains limited. This paper emphasizes the importance of ablation studies by examining the Bayesian Causal Forest (BCF) model, particularly the inclusion of the estimated propensity score $\hat{\pi}(x_i)$ intended to mitigate regularization-induced confounding (RIC). Through a partial ablation study utilizing five synthetic data-generating processes with varying baseline and propensity score complexities, we demonstrate that excluding $\hat{\pi}(x_i)$ does not diminish the model's performance in estimating average and conditional average treatment effects or in uncertainty quantification. Moreover, omitting $\hat{\pi}(x_i)$ reduces computational time by approximately 21\%. These findings suggest that the BCF model's inherent flexibility suffices in adjusting for confounding without explicitly incorporating the propensity score. The study advocates for the routine use of ablation studies in treatment effect estimation to ensure model components are essential and to prevent unnecessary complexity.
fakenewsbr: A Fake News Detection Platform for Brazilian Portuguese
Sep 21, 2023



The proliferation of fake news has become a significant concern in recent times due to its potential to spread misinformation and manipulate public opinion. This paper presents a comprehensive study on detecting fake news in Brazilian Portuguese, focusing on journalistic-type news. We propose a machine learning-based approach that leverages natural language processing techniques, including TF-IDF and Word2Vec, to extract features from textual data. We evaluate the performance of various classification algorithms, such as logistic regression, support vector machine, random forest, AdaBoost, and LightGBM, on a dataset containing both true and fake news articles. The proposed approach achieves high accuracy and F1-Score, demonstrating its effectiveness in identifying fake news. Additionally, we developed a user-friendly web platform, fakenewsbr.com, to facilitate the verification of news articles' veracity. Our platform provides real-time analysis, allowing users to assess the likelihood of fake news articles. Through empirical analysis and comparative studies, we demonstrate the potential of our approach to contribute to the fight against the spread of fake news and promote more informed media consumption.
Random Machines Regression Approach: an ensemble support vector regression model with free kernel choice
Mar 27, 2020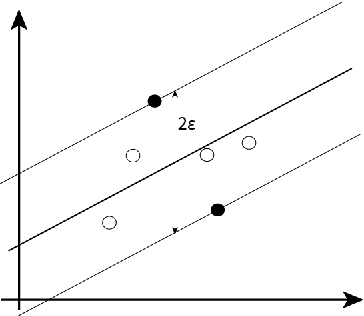
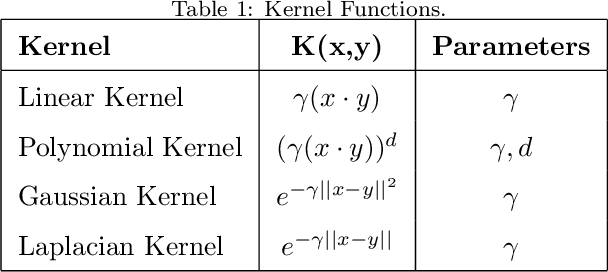
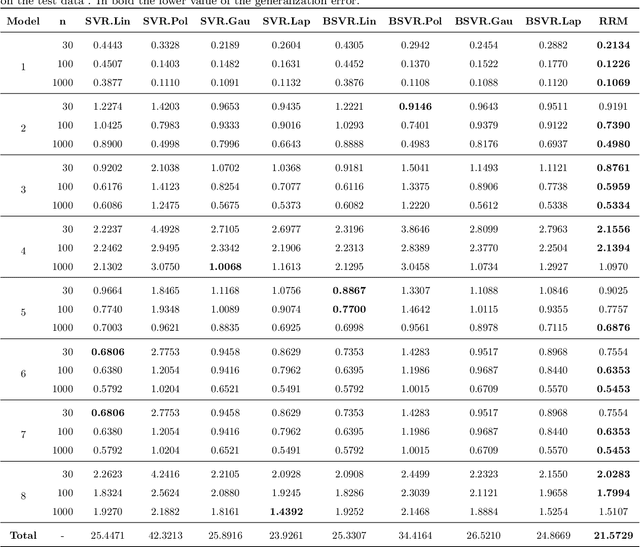
Machine learning techniques always aim to reduce the generalized prediction error. In order to reduce it, ensemble methods present a good approach combining several models that results in a greater forecasting capacity. The Random Machines already have been demonstrated as strong technique, i.e: high predictive power, to classification tasks, in this article we propose an procedure to use the bagged-weighted support vector model to regression problems. Simulation studies were realized over artificial datasets, and over real data benchmarks. The results exhibited a good performance of Regression Random Machines through lower generalization error without needing to choose the best kernel function during tuning process.
Random Machines: A bagged-weighted support vector model with free kernel choice
Nov 21, 2019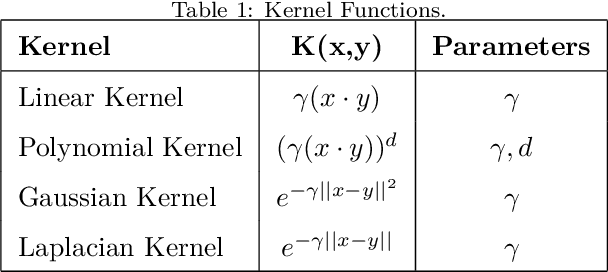
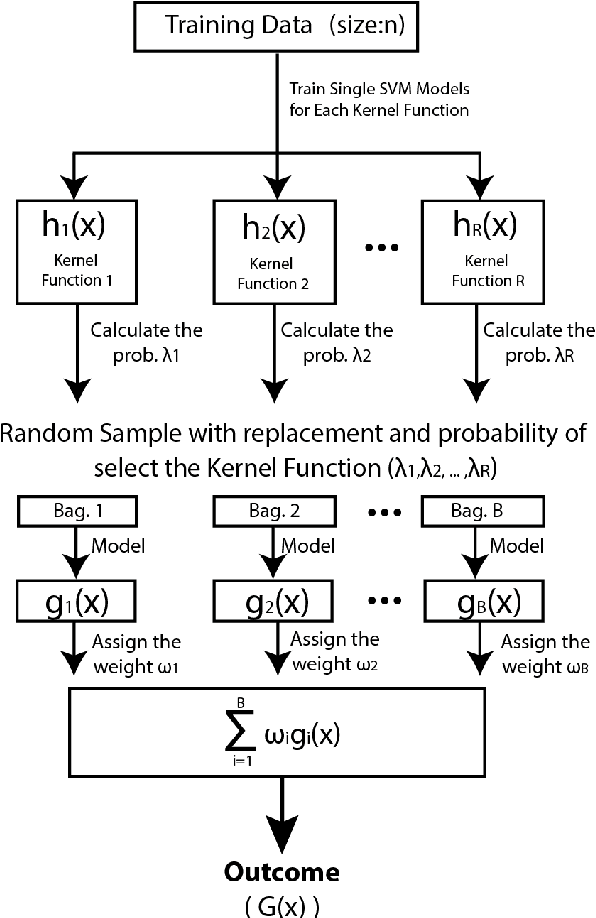
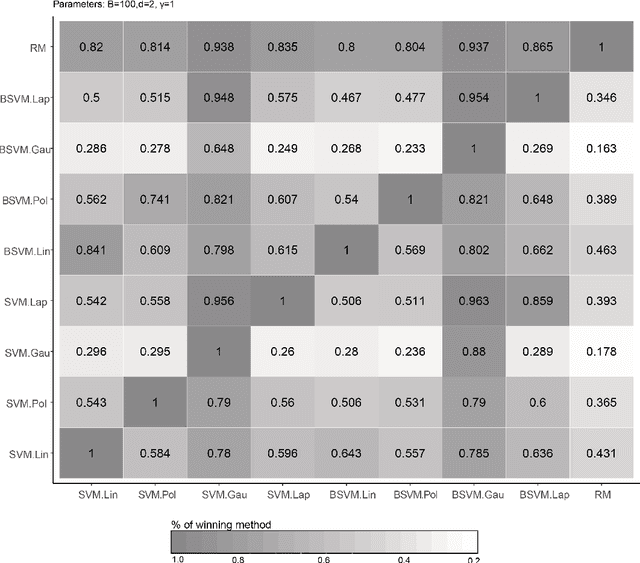
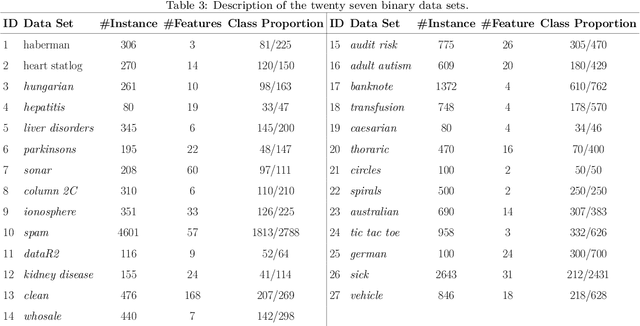
Improvement of statistical learning models in order to increase efficiency in solving classification or regression problems is still a goal pursued by the scientific community. In this way, the support vector machine model is one of the most successful and powerful algorithms for those tasks. However, its performance depends directly from the choice of the kernel function and their hyperparameters. The traditional choice of them, actually, can be computationally expensive to do the kernel choice and the tuning processes. In this article, it is proposed a novel framework to deal with the kernel function selection called Random Machines. The results improved accuracy and reduced computational time. The data study was performed in simulated data and over 27 real benchmarking datasets.