 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRandom Machines Regression Approach: an ensemble support vector regression model with free kernel choice
Mar 27, 2020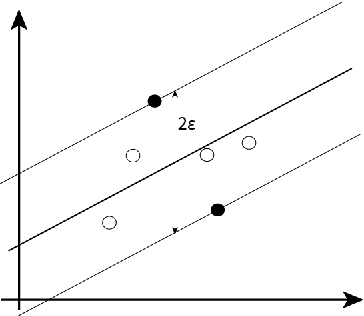
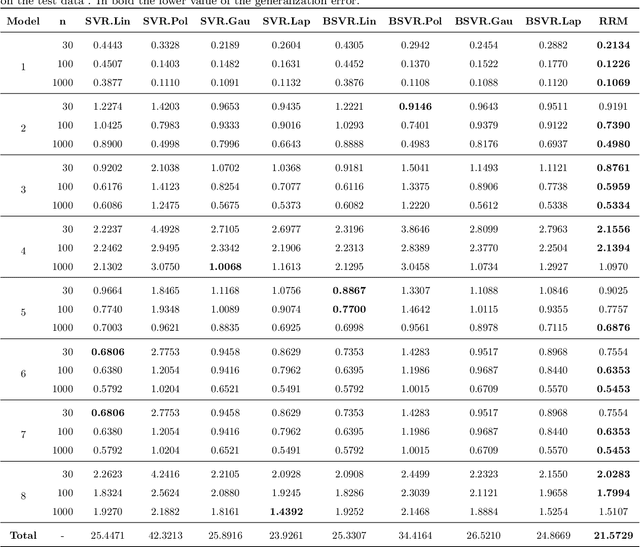
Machine learning techniques always aim to reduce the generalized prediction error. In order to reduce it, ensemble methods present a good approach combining several models that results in a greater forecasting capacity. The Random Machines already have been demonstrated as strong technique, i.e: high predictive power, to classification tasks, in this article we propose an procedure to use the bagged-weighted support vector model to regression problems. Simulation studies were realized over artificial datasets, and over real data benchmarks. The results exhibited a good performance of Regression Random Machines through lower generalization error without needing to choose the best kernel function during tuning process.
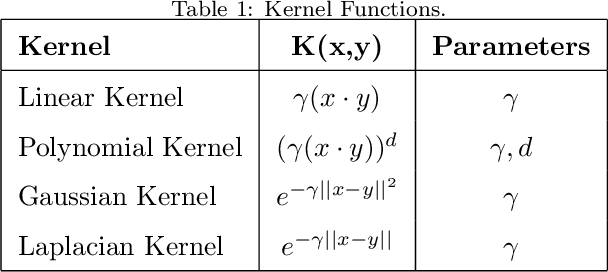
Random Machines: A bagged-weighted support vector model with free kernel choice
Nov 21, 2019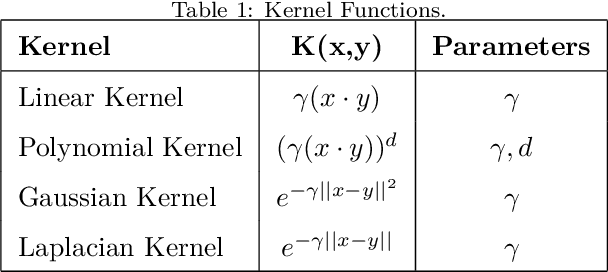
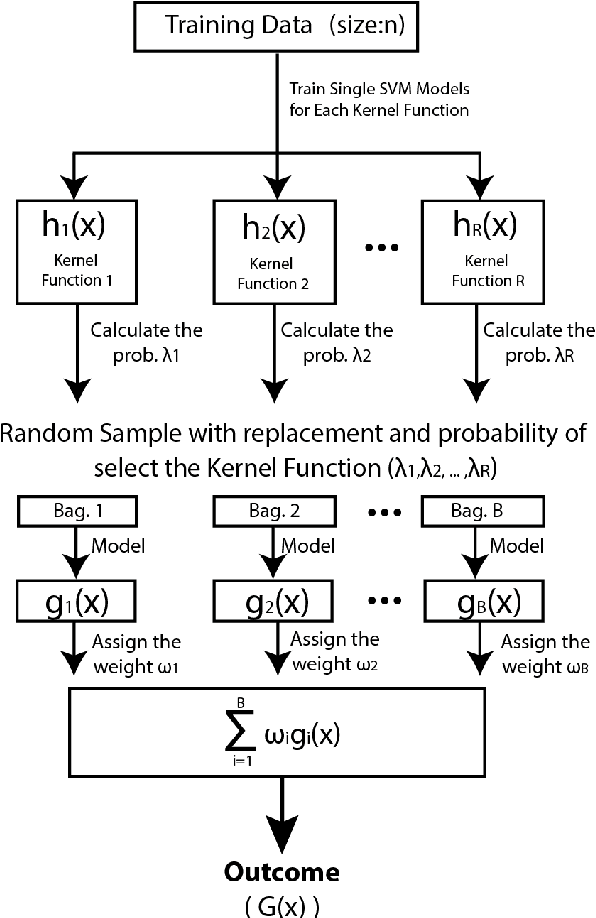
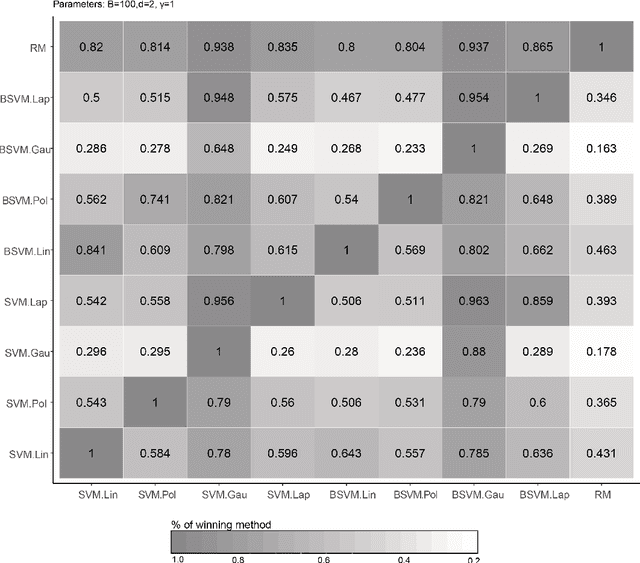
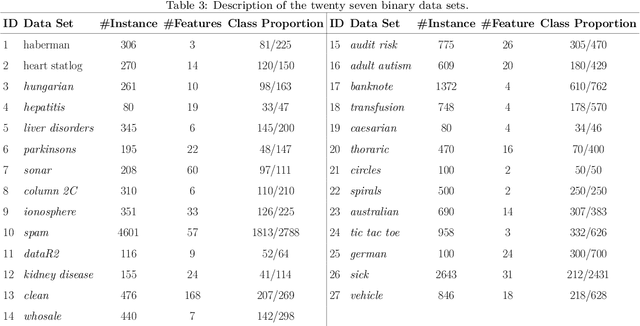
Improvement of statistical learning models in order to increase efficiency in solving classification or regression problems is still a goal pursued by the scientific community. In this way, the support vector machine model is one of the most successful and powerful algorithms for those tasks. However, its performance depends directly from the choice of the kernel function and their hyperparameters. The traditional choice of them, actually, can be computationally expensive to do the kernel choice and the tuning processes. In this article, it is proposed a novel framework to deal with the kernel function selection called Random Machines. The results improved accuracy and reduced computational time. The data study was performed in simulated data and over 27 real benchmarking datasets.
Feature Selection Approach with Missing Values Conducted for Statistical Learning: A Case Study of Entrepreneurship Survival Dataset
Oct 02, 2018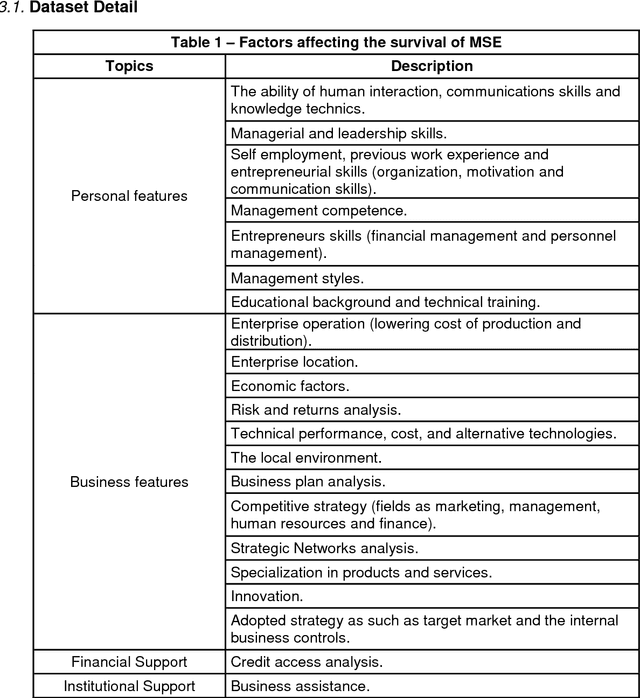
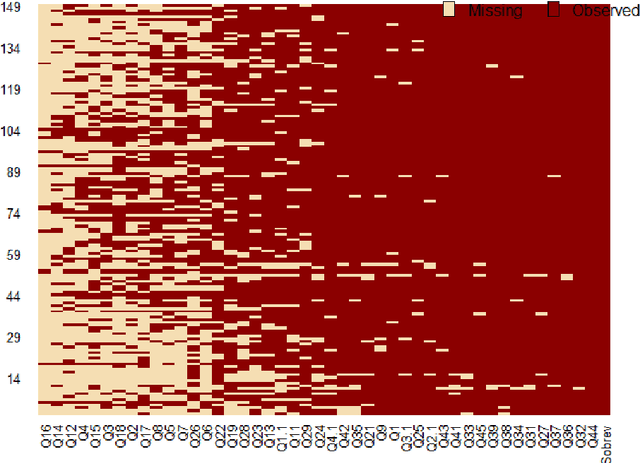
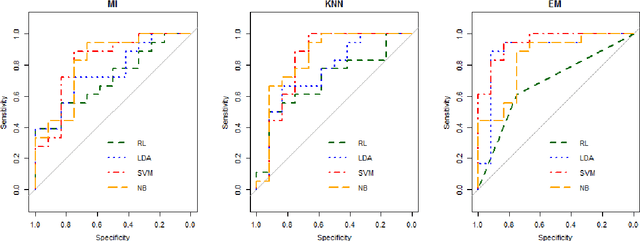
In this article, we investigate the features which enhanced discriminate the survival in the micro and small business (MSE) using the approach of data mining with feature selection. According to the complexity of the data set, we proposed a comparison of three data imputation methods such as mean imputation (MI), k-nearest neighbor (KNN) and expectation maximization (EM) using mutually the selection of variables technique, whereby t-test, then through the data mining process using logistic regression classification methods, naive Bayes algorithm, linear discriminant analysis and support vector machine hence comparing their respective performances. The experimental results will be spread in developing a model to predict the MSE survival, providing a better understanding in the topic once it is a significant part of the Brazilian' GPA and macroeconomy.