 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForests for Differences: Robust Causal Inference Beyond Parametric DiD
May 14, 2025This paper introduces the Difference-in-Differences Bayesian Causal Forest (DiD-BCF), a novel non-parametric model addressing key challenges in DiD estimation, such as staggered adoption and heterogeneous treatment effects. DiD-BCF provides a unified framework for estimating Average (ATE), Group-Average (GATE), and Conditional Average Treatment Effects (CATE). A core innovation, its Parallel Trends Assumption (PTA)-based reparameterization, enhances estimation accuracy and stability in complex panel data settings. Extensive simulations demonstrate DiD-BCF's superior performance over established benchmarks, particularly under non-linearity, selection biases, and effect heterogeneity. Applied to U.S. minimum wage policy, the model uncovers significant conditional treatment effect heterogeneity related to county population, insights obscured by traditional methods. DiD-BCF offers a robust and versatile tool for more nuanced causal inference in modern DiD applications.
Advancing Causal Inference: A Nonparametric Approach to ATE and CATE Estimation with Continuous Treatments
Sep 10, 2024This paper introduces a generalized ps-BART model for the estimation of Average Treatment Effect (ATE) and Conditional Average Treatment Effect (CATE) in continuous treatments, addressing limitations of the Bayesian Causal Forest (BCF) model. The ps-BART model's nonparametric nature allows for flexibility in capturing nonlinear relationships between treatment and outcome variables. Across three distinct sets of Data Generating Processes (DGPs), the ps-BART model consistently outperforms the BCF model, particularly in highly nonlinear settings. The ps-BART model's robustness in uncertainty estimation and accuracy in both point-wise and probabilistic estimation demonstrate its utility for real-world applications. This research fills a crucial gap in causal inference literature, providing a tool better suited for nonlinear treatment-outcome relationships and opening avenues for further exploration in the domain of continuous treatment effect estimation.
K-Fold Causal BART for CATE Estimation
Sep 09, 2024This research aims to propose and evaluate a novel model named K-Fold Causal Bayesian Additive Regression Trees (K-Fold Causal BART) for improved estimation of Average Treatment Effects (ATE) and Conditional Average Treatment Effects (CATE). The study employs synthetic and semi-synthetic datasets, including the widely recognized Infant Health and Development Program (IHDP) benchmark dataset, to validate the model's performance. Despite promising results in synthetic scenarios, the IHDP dataset reveals that the proposed model is not state-of-the-art for ATE and CATE estimation. Nonetheless, the research provides several novel insights: 1. The ps-BART model is likely the preferred choice for CATE and ATE estimation due to better generalization compared to the other benchmark models - including the Bayesian Causal Forest (BCF) model, which is considered by many the current best model for CATE estimation, 2. The BCF model's performance deteriorates significantly with increasing treatment effect heterogeneity, while the ps-BART model remains robust, 3. Models tend to be overconfident in CATE uncertainty quantification when treatment effect heterogeneity is low, 4. A second K-Fold method is unnecessary for avoiding overfitting in CATE estimation, as it adds computational costs without improving performance, 5. Detailed analysis reveals the importance of understanding dataset characteristics and using nuanced evaluation methods, 6. The conclusion of Curth et al. (2021) that indirect strategies for CATE estimation are superior for the IHDP dataset is contradicted by the results of this research. These findings challenge existing assumptions and suggest directions for future research to enhance causal inference methodologies.
Multi-level Product Category Prediction through Text Classification
Mar 03, 2024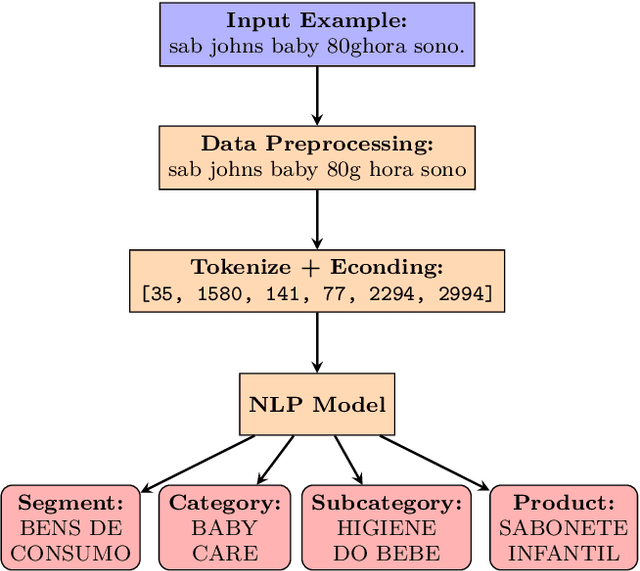
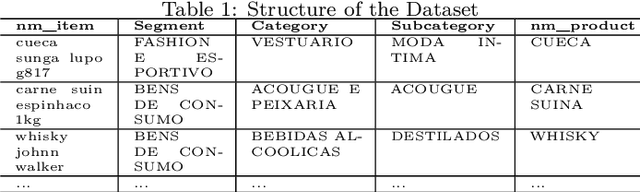
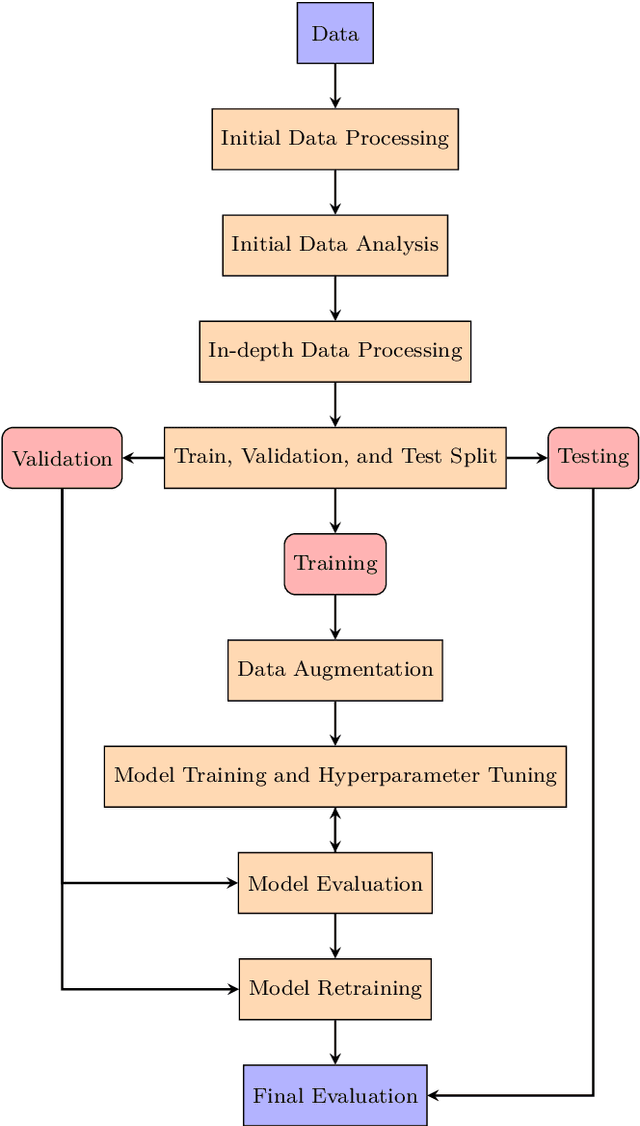
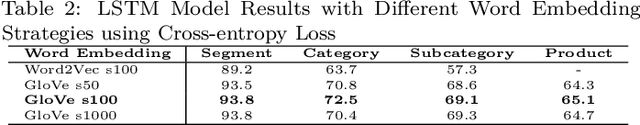
This article investigates applying advanced machine learning models, specifically LSTM and BERT, for text classification to predict multiple categories in the retail sector. The study demonstrates how applying data augmentation techniques and the focal loss function can significantly enhance accuracy in classifying products into multiple categories using a robust Brazilian retail dataset. The LSTM model, enriched with Brazilian word embedding, and BERT, known for its effectiveness in understanding complex contexts, were adapted and optimized for this specific task. The results showed that the BERT model, with an F1 Macro Score of up to $99\%$ for segments, $96\%$ for categories and subcategories and $93\%$ for name products, outperformed LSTM in more detailed categories. However, LSTM also achieved high performance, especially after applying data augmentation and focal loss techniques. These results underscore the effectiveness of NLP techniques in retail and highlight the importance of the careful selection of modelling and preprocessing strategies. This work contributes significantly to the field of NLP in retail, providing valuable insights for future research and practical applications.
Feature Selection Approach with Missing Values Conducted for Statistical Learning: A Case Study of Entrepreneurship Survival Dataset
Oct 02, 2018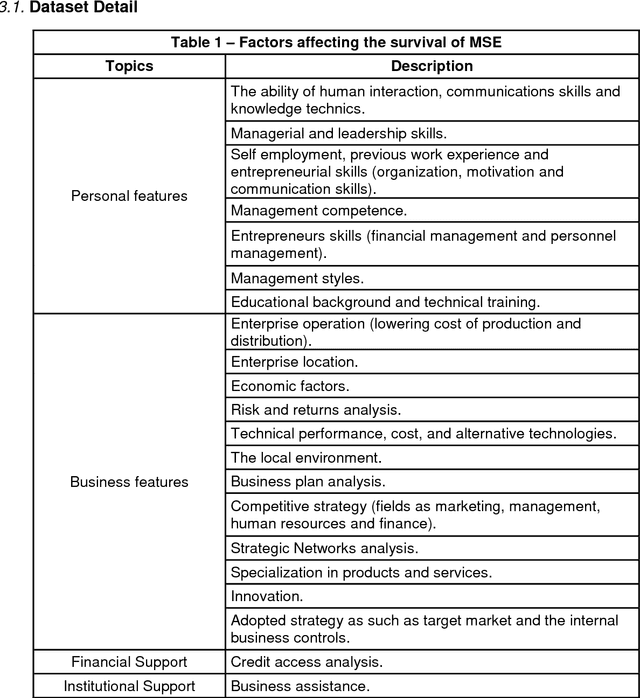
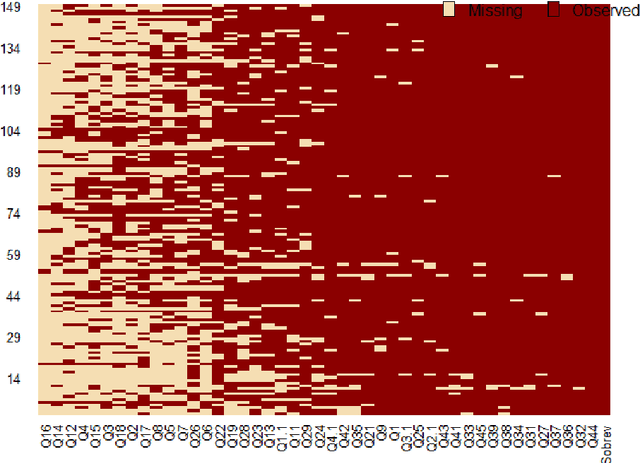
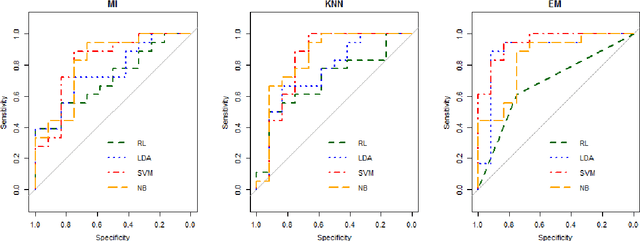
In this article, we investigate the features which enhanced discriminate the survival in the micro and small business (MSE) using the approach of data mining with feature selection. According to the complexity of the data set, we proposed a comparison of three data imputation methods such as mean imputation (MI), k-nearest neighbor (KNN) and expectation maximization (EM) using mutually the selection of variables technique, whereby t-test, then through the data mining process using logistic regression classification methods, naive Bayes algorithm, linear discriminant analysis and support vector machine hence comparing their respective performances. The experimental results will be spread in developing a model to predict the MSE survival, providing a better understanding in the topic once it is a significant part of the Brazilian' GPA and macroeconomy.