 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-level Product Category Prediction through Text Classification
Paper and Code
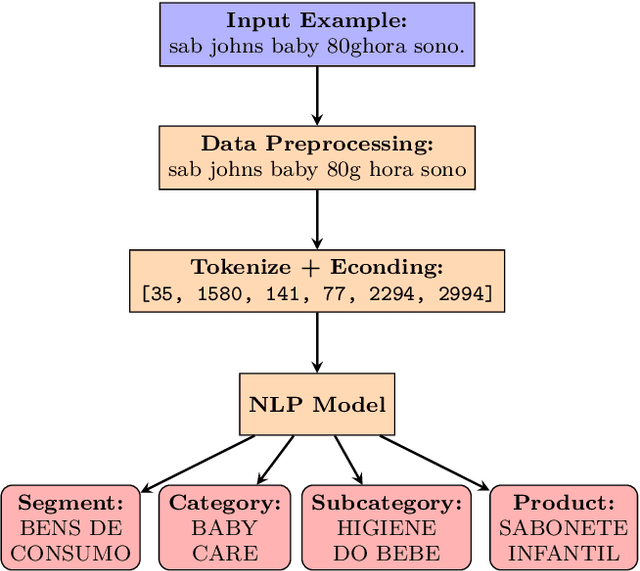
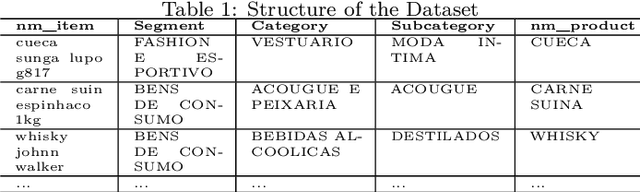
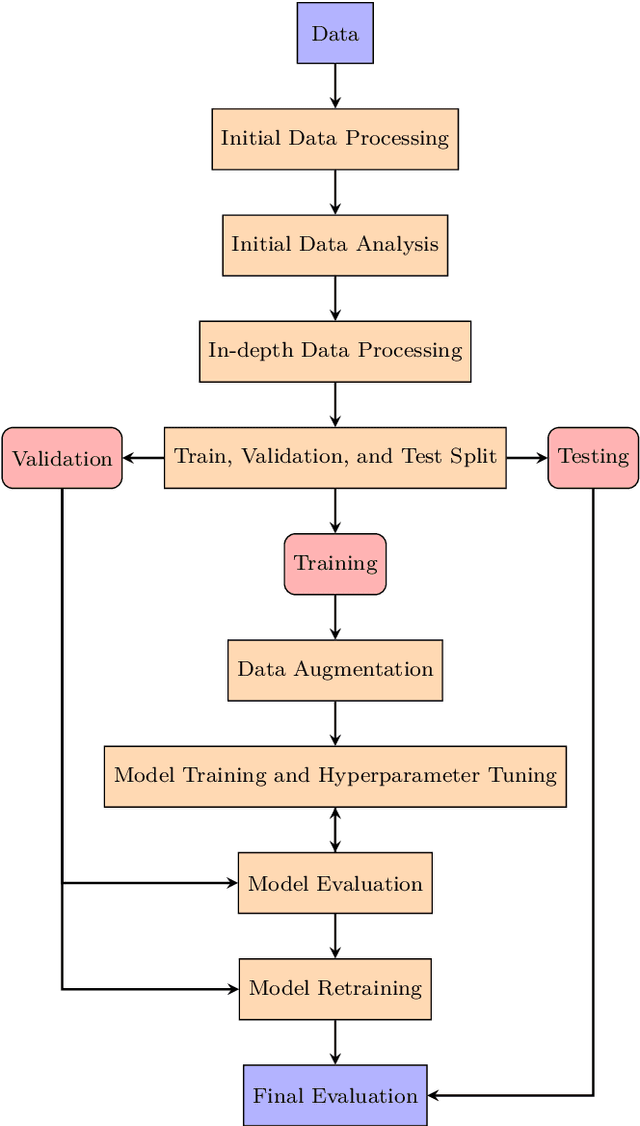
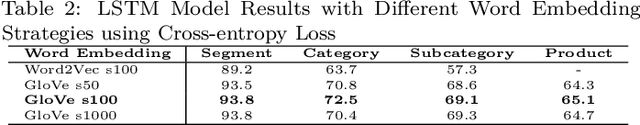
This article investigates applying advanced machine learning models, specifically LSTM and BERT, for text classification to predict multiple categories in the retail sector. The study demonstrates how applying data augmentation techniques and the focal loss function can significantly enhance accuracy in classifying products into multiple categories using a robust Brazilian retail dataset. The LSTM model, enriched with Brazilian word embedding, and BERT, known for its effectiveness in understanding complex contexts, were adapted and optimized for this specific task. The results showed that the BERT model, with an F1 Macro Score of up to $99\%$ for segments, $96\%$ for categories and subcategories and $93\%$ for name products, outperformed LSTM in more detailed categories. However, LSTM also achieved high performance, especially after applying data augmentation and focal loss techniques. These results underscore the effectiveness of NLP techniques in retail and highlight the importance of the careful selection of modelling and preprocessing strategies. This work contributes significantly to the field of NLP in retail, providing valuable insights for future research and practical applications.