 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecomposing Direct and Indirect Biases in Linear Models under Demographic Parity Constraint
Nov 14, 2025Linear models are widely used in high-stakes decision-making due to their simplicity and interpretability. Yet when fairness constraints such as demographic parity are introduced, their effects on model coefficients, and thus on how predictive bias is distributed across features, remain opaque. Existing approaches on linear models often rely on strong and unrealistic assumptions, or overlook the explicit role of the sensitive attribute, limiting their practical utility for fairness assessment. We extend the work of (Chzhen and Schreuder, 2022) and (Fukuchi and Sakuma, 2023) by proposing a post-processing framework that can be applied on top of any linear model to decompose the resulting bias into direct (sensitive-attribute) and indirect (correlated-features) components. Our method analytically characterizes how demographic parity reshapes each model coefficient, including those of both sensitive and non-sensitive features. This enables a transparent, feature-level interpretation of fairness interventions and reveals how bias may persist or shift through correlated variables. Our framework requires no retraining and provides actionable insights for model auditing and mitigation. Experiments on both synthetic and real-world datasets demonstrate that our method captures fairness dynamics missed by prior work, offering a practical and interpretable tool for responsible deployment of linear models.
EquiPy: Sequential Fairness using Optimal Transport in Python
Mar 12, 2025Algorithmic fairness has received considerable attention due to the failures of various predictive AI systems that have been found to be unfairly biased against subgroups of the population. Many approaches have been proposed to mitigate such biases in predictive systems, however, they often struggle to provide accurate estimates and transparent correction mechanisms in the case where multiple sensitive variables, such as a combination of gender and race, are involved. This paper introduces a new open source Python package, EquiPy, which provides a easy-to-use and model agnostic toolbox for efficiently achieving fairness across multiple sensitive variables. It also offers comprehensive graphic utilities to enable the user to interpret the influence of each sensitive variable within a global context. EquiPy makes use of theoretical results that allow the complexity arising from the use of multiple variables to be broken down into easier-to-solve sub-problems. We demonstrate the ease of use for both mitigation and interpretation on publicly available data derived from the US Census and provide sample code for its use.
Probabilistic Scores of Classifiers, Calibration is not Enough
Aug 06, 2024In binary classification tasks, accurate representation of probabilistic predictions is essential for various real-world applications such as predicting payment defaults or assessing medical risks. The model must then be well-calibrated to ensure alignment between predicted probabilities and actual outcomes. However, when score heterogeneity deviates from the underlying data probability distribution, traditional calibration metrics lose reliability, failing to align score distribution with actual probabilities. In this study, we highlight approaches that prioritize optimizing the alignment between predicted scores and true probability distributions over minimizing traditional performance or calibration metrics. When employing tree-based models such as Random Forest and XGBoost, our analysis emphasizes the flexibility these models offer in tuning hyperparameters to minimize the Kullback-Leibler (KL) divergence between predicted and true distributions. Through extensive empirical analysis across 10 UCI datasets and simulations, we demonstrate that optimizing tree-based models based on KL divergence yields superior alignment between predicted scores and actual probabilities without significant performance loss. In real-world scenarios, the reference probability is determined a priori as a Beta distribution estimated through maximum likelihood. Conversely, minimizing traditional calibration metrics may lead to suboptimal results, characterized by notable performance declines and inferior KL values. Our findings reveal limitations in traditional calibration metrics, which could undermine the reliability of predictive models for critical decision-making.
From Uncertainty to Precision: Enhancing Binary Classifier Performance through Calibration
Feb 12, 2024



The assessment of binary classifier performance traditionally centers on discriminative ability using metrics, such as accuracy. However, these metrics often disregard the model's inherent uncertainty, especially when dealing with sensitive decision-making domains, such as finance or healthcare. Given that model-predicted scores are commonly seen as event probabilities, calibration is crucial for accurate interpretation. In our study, we analyze the sensitivity of various calibration measures to score distortions and introduce a refined metric, the Local Calibration Score. Comparing recalibration methods, we advocate for local regressions, emphasizing their dual role as effective recalibration tools and facilitators of smoother visualizations. We apply these findings in a real-world scenario using Random Forest classifier and regressor to predict credit default while simultaneously measuring calibration during performance optimization.
Geospatial Disparities: A Case Study on Real Estate Prices in Paris
Jan 29, 2024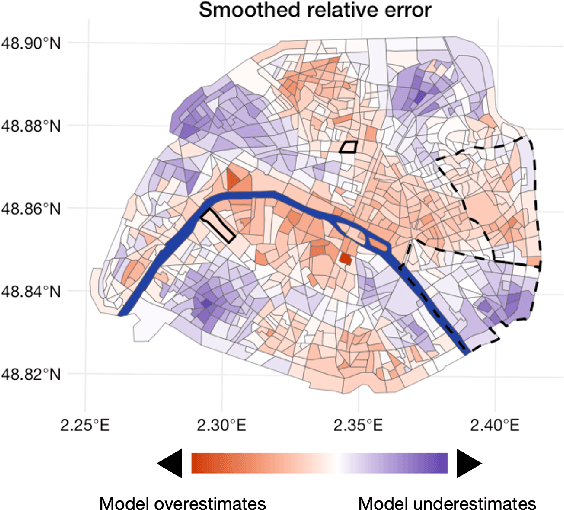

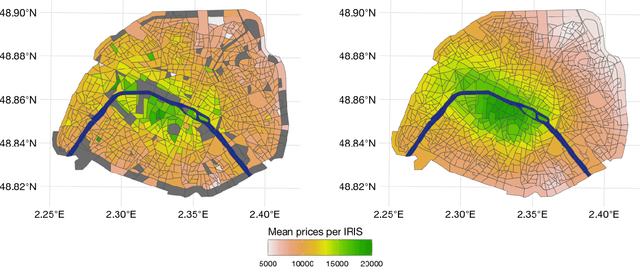
Driven by an increasing prevalence of trackers, ever more IoT sensors, and the declining cost of computing power, geospatial information has come to play a pivotal role in contemporary predictive models. While enhancing prognostic performance, geospatial data also has the potential to perpetuate many historical socio-economic patterns, raising concerns about a resurgence of biases and exclusionary practices, with their disproportionate impacts on society. Addressing this, our paper emphasizes the crucial need to identify and rectify such biases and calibration errors in predictive models, particularly as algorithms become more intricate and less interpretable. The increasing granularity of geospatial information further introduces ethical concerns, as choosing different geographical scales may exacerbate disparities akin to redlining and exclusionary zoning. To address these issues, we propose a toolkit for identifying and mitigating biases arising from geospatial data. Extending classical fairness definitions, we incorporate an ordinal regression case with spatial attributes, deviating from the binary classification focus. This extension allows us to gauge disparities stemming from data aggregation levels and advocates for a less interfering correction approach. Illustrating our methodology using a Parisian real estate dataset, we showcase practical applications and scrutinize the implications of choosing geographical aggregation levels for fairness and calibration measures.
A Sequentially Fair Mechanism for Multiple Sensitive Attributes
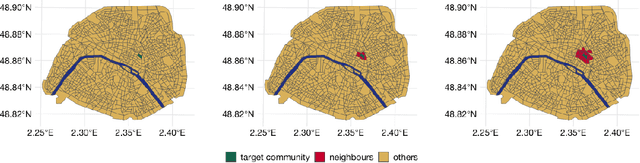
Sep 12, 2023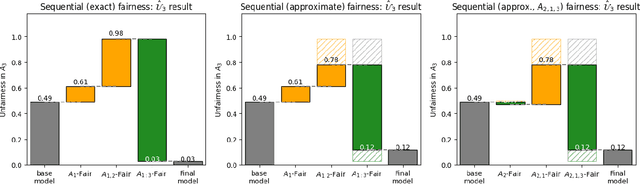
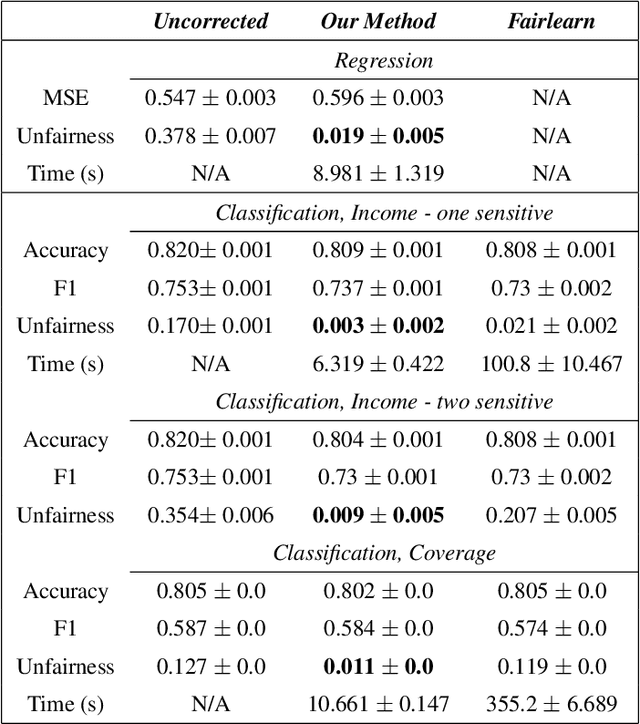
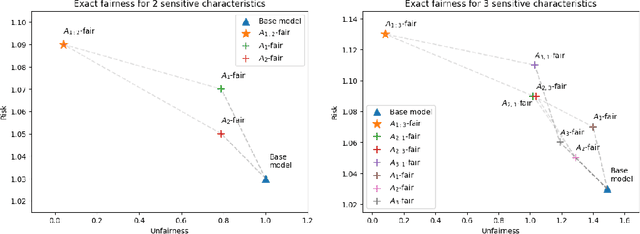
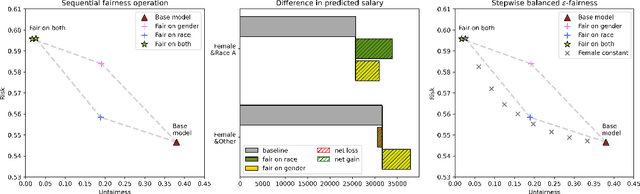
In the standard use case of Algorithmic Fairness, the goal is to eliminate the relationship between a sensitive variable and a corresponding score. Throughout recent years, the scientific community has developed a host of definitions and tools to solve this task, which work well in many practical applications. However, the applicability and effectivity of these tools and definitions becomes less straightfoward in the case of multiple sensitive attributes. To tackle this issue, we propose a sequential framework, which allows to progressively achieve fairness across a set of sensitive features. We accomplish this by leveraging multi-marginal Wasserstein barycenters, which extends the standard notion of Strong Demographic Parity to the case with multiple sensitive characteristics. This method also provides a closed-form solution for the optimal, sequentially fair predictor, permitting a clear interpretation of inter-sensitive feature correlations. Our approach seamlessly extends to approximate fairness, enveloping a framework accommodating the trade-off between risk and unfairness. This extension permits a targeted prioritization of fairness improvements for a specific attribute within a set of sensitive attributes, allowing for a case specific adaptation. A data-driven estimation procedure for the derived solution is developed, and comprehensive numerical experiments are conducted on both synthetic and real datasets. Our empirical findings decisively underscore the practical efficacy of our post-processing approach in fostering fair decision-making.
Addressing Fairness and Explainability in Image Classification Using Optimal Transport
Aug 22, 2023Algorithmic Fairness and the explainability of potentially unfair outcomes are crucial for establishing trust and accountability of Artificial Intelligence systems in domains such as healthcare and policing. Though significant advances have been made in each of the fields separately, achieving explainability in fairness applications remains challenging, particularly so in domains where deep neural networks are used. At the same time, ethical data-mining has become ever more relevant, as it has been shown countless times that fairness-unaware algorithms result in biased outcomes. Current approaches focus on mitigating biases in the outcomes of the model, but few attempts have been made to try to explain \emph{why} a model is biased. To bridge this gap, we propose a comprehensive approach that leverages optimal transport theory to uncover the causes and implications of biased regions in images, which easily extends to tabular data as well. Through the use of Wasserstein barycenters, we obtain scores that are independent of a sensitive variable but keep their marginal orderings. This step ensures predictive accuracy but also helps us to recover the regions most associated with the generation of the biases. Our findings hold significant implications for the development of trustworthy and unbiased AI systems, fostering transparency, accountability, and fairness in critical decision-making scenarios across diverse domains.
Mitigating Discrimination in Insurance with Wasserstein Barycenters
Jun 22, 2023The insurance industry is heavily reliant on predictions of risks based on characteristics of potential customers. Although the use of said models is common, researchers have long pointed out that such practices perpetuate discrimination based on sensitive features such as gender or race. Given that such discrimination can often be attributed to historical data biases, an elimination or at least mitigation is desirable. With the shift from more traditional models to machine-learning based predictions, calls for greater mitigation have grown anew, as simply excluding sensitive variables in the pricing process can be shown to be ineffective. In this article, we first investigate why predictions are a necessity within the industry and why correcting biases is not as straightforward as simply identifying a sensitive variable. We then propose to ease the biases through the use of Wasserstein barycenters instead of simple scaling. To demonstrate the effects and effectiveness of the approach we employ it on real data and discuss its implications.
Fairness in Multi-Task Learning via Wasserstein Barycenters
Jun 16, 2023Algorithmic Fairness is an established field in machine learning that aims to reduce biases in data. Recent advances have proposed various methods to ensure fairness in a univariate environment, where the goal is to de-bias a single task. However, extending fairness to a multi-task setting, where more than one objective is optimised using a shared representation, remains underexplored. To bridge this gap, we develop a method that extends the definition of \textit{Strong Demographic Parity} to multi-task learning using multi-marginal Wasserstein barycenters. Our approach provides a closed form solution for the optimal fair multi-task predictor including both regression and binary classification tasks. We develop a data-driven estimation procedure for the solution and run numerical experiments on both synthetic and real datasets. The empirical results highlight the practical value of our post-processing methodology in promoting fair decision-making.
An overview of active learning methods for insurance with fairness appreciation
Dec 17, 2021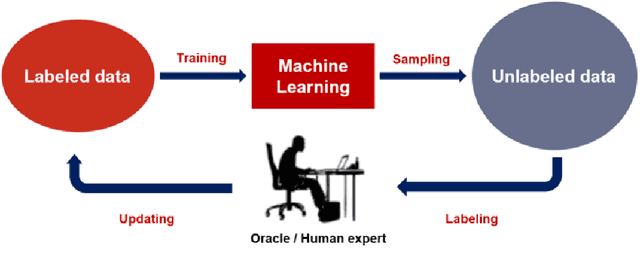
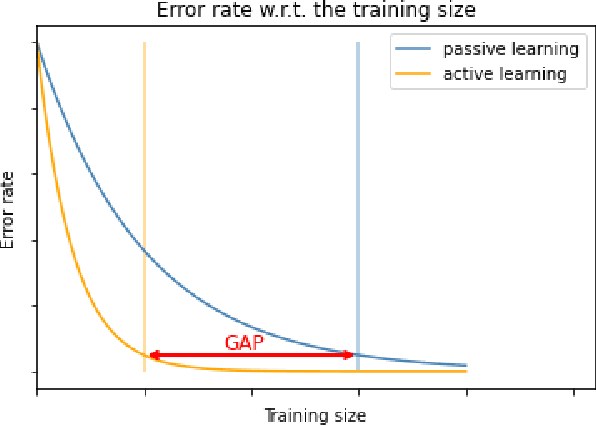
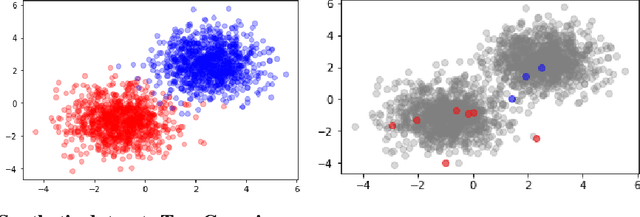
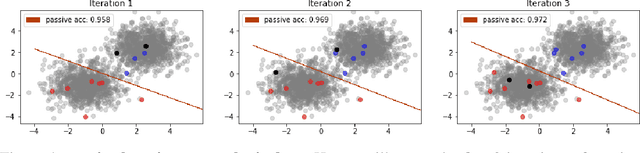
This paper addresses and solves some challenges in the adoption of machine learning in insurance with the democratization of model deployment. The first challenge is reducing the labelling effort (hence focusing on the data quality) with the help of active learning, a feedback loop between the model inference and an oracle: as in insurance the unlabeled data is usually abundant, active learning can become a significant asset in reducing the labelling cost. For that purpose, this paper sketches out various classical active learning methodologies before studying their empirical impact on both synthetic and real datasets. Another key challenge in insurance is the fairness issue in model inferences. We will introduce and integrate a post-processing fairness for multi-class tasks in this active learning framework to solve these two issues. Finally numerical experiments on unfair datasets highlight that the proposed setup presents a good compromise between model precision and fairness.