 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn overview of active learning methods for insurance with fairness appreciation
Paper and Code
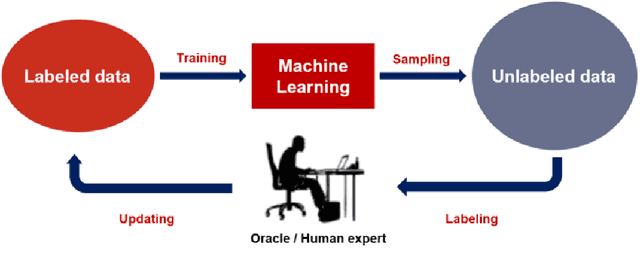
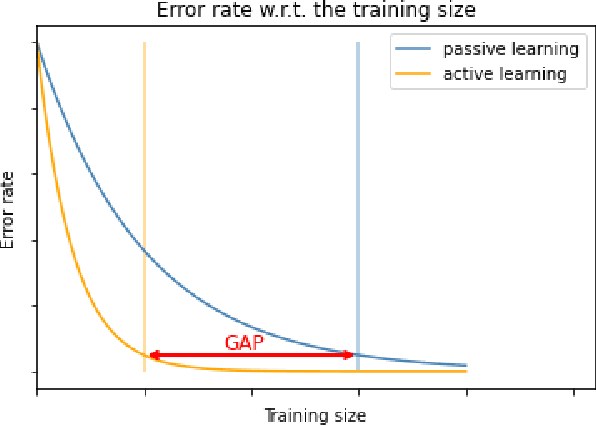
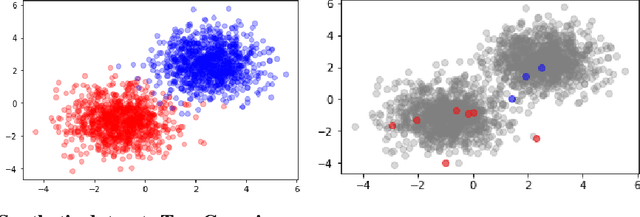
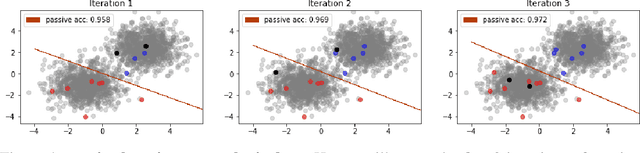
This paper addresses and solves some challenges in the adoption of machine learning in insurance with the democratization of model deployment. The first challenge is reducing the labelling effort (hence focusing on the data quality) with the help of active learning, a feedback loop between the model inference and an oracle: as in insurance the unlabeled data is usually abundant, active learning can become a significant asset in reducing the labelling cost. For that purpose, this paper sketches out various classical active learning methodologies before studying their empirical impact on both synthetic and real datasets. Another key challenge in insurance is the fairness issue in model inferences. We will introduce and integrate a post-processing fairness for multi-class tasks in this active learning framework to solve these two issues. Finally numerical experiments on unfair datasets highlight that the proposed setup presents a good compromise between model precision and fairness.