 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeospatial Disparities: A Case Study on Real Estate Prices in Paris
Paper and Code
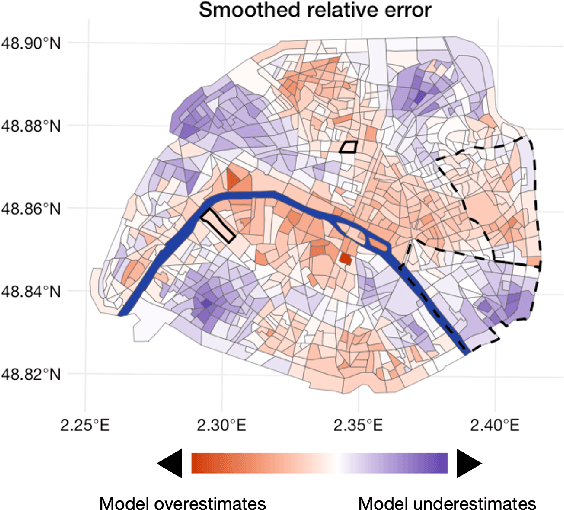

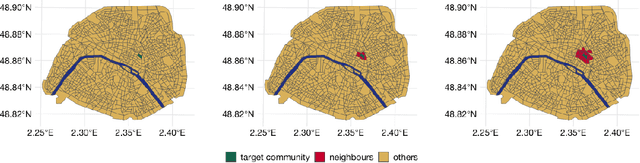
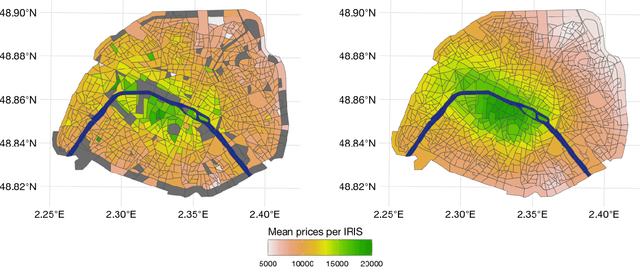
Driven by an increasing prevalence of trackers, ever more IoT sensors, and the declining cost of computing power, geospatial information has come to play a pivotal role in contemporary predictive models. While enhancing prognostic performance, geospatial data also has the potential to perpetuate many historical socio-economic patterns, raising concerns about a resurgence of biases and exclusionary practices, with their disproportionate impacts on society. Addressing this, our paper emphasizes the crucial need to identify and rectify such biases and calibration errors in predictive models, particularly as algorithms become more intricate and less interpretable. The increasing granularity of geospatial information further introduces ethical concerns, as choosing different geographical scales may exacerbate disparities akin to redlining and exclusionary zoning. To address these issues, we propose a toolkit for identifying and mitigating biases arising from geospatial data. Extending classical fairness definitions, we incorporate an ordinal regression case with spatial attributes, deviating from the binary classification focus. This extension allows us to gauge disparities stemming from data aggregation levels and advocates for a less interfering correction approach. Illustrating our methodology using a Parisian real estate dataset, we showcase practical applications and scrutinize the implications of choosing geographical aggregation levels for fairness and calibration measures.