 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnveil Sources of Uncertainty: Feature Contribution to Conformal Prediction Intervals
May 19, 2025



Cooperative game theory methods, notably Shapley values, have significantly enhanced machine learning (ML) interpretability. However, existing explainable AI (XAI) frameworks mainly attribute average model predictions, overlooking predictive uncertainty. This work addresses that gap by proposing a novel, model-agnostic uncertainty attribution (UA) method grounded in conformal prediction (CP). By defining cooperative games where CP interval properties-such as width and bounds-serve as value functions, we systematically attribute predictive uncertainty to input features. Extending beyond the traditional Shapley values, we use the richer class of Harsanyi allocations, and in particular the proportional Shapley values, which distribute attribution proportionally to feature importance. We propose a Monte Carlo approximation method with robust statistical guarantees to address computational feasibility, significantly improving runtime efficiency. Our comprehensive experiments on synthetic benchmarks and real-world datasets demonstrate the practical utility and interpretative depth of our approach. By combining cooperative game theory and conformal prediction, we offer a rigorous, flexible toolkit for understanding and communicating predictive uncertainty in high-stakes ML applications.
Optimal Transport on Categorical Data for Counterfactuals using Compositional Data and Dirichlet Transport
Jan 26, 2025Recently, optimal transport-based approaches have gained attention for deriving counterfactuals, e.g., to quantify algorithmic discrimination. However, in the general multivariate setting, these methods are often opaque and difficult to interpret. To address this, alternative methodologies have been proposed, using causal graphs combined with iterative quantile regressions (Ple\v{c}ko and Meinshausen (2020)) or sequential transport (Fernandes Machado et al. (2025)) to examine fairness at the individual level, often referred to as ``counterfactual fairness.'' Despite these advancements, transporting categorical variables remains a significant challenge in practical applications with real datasets. In this paper, we propose a novel approach to address this issue. Our method involves (1) converting categorical variables into compositional data and (2) transporting these compositions within the probabilistic simplex of $\mathbb{R}^d$. We demonstrate the applicability and effectiveness of this approach through an illustration on real-world data, and discuss limitations.
Probabilistic Scores of Classifiers, Calibration is not Enough
Aug 06, 2024In binary classification tasks, accurate representation of probabilistic predictions is essential for various real-world applications such as predicting payment defaults or assessing medical risks. The model must then be well-calibrated to ensure alignment between predicted probabilities and actual outcomes. However, when score heterogeneity deviates from the underlying data probability distribution, traditional calibration metrics lose reliability, failing to align score distribution with actual probabilities. In this study, we highlight approaches that prioritize optimizing the alignment between predicted scores and true probability distributions over minimizing traditional performance or calibration metrics. When employing tree-based models such as Random Forest and XGBoost, our analysis emphasizes the flexibility these models offer in tuning hyperparameters to minimize the Kullback-Leibler (KL) divergence between predicted and true distributions. Through extensive empirical analysis across 10 UCI datasets and simulations, we demonstrate that optimizing tree-based models based on KL divergence yields superior alignment between predicted scores and actual probabilities without significant performance loss. In real-world scenarios, the reference probability is determined a priori as a Beta distribution estimated through maximum likelihood. Conversely, minimizing traditional calibration metrics may lead to suboptimal results, characterized by notable performance declines and inferior KL values. Our findings reveal limitations in traditional calibration metrics, which could undermine the reliability of predictive models for critical decision-making.
Sequential Conditional Transport on Probabilistic Graphs for Interpretable Counterfactual Fairness
Aug 06, 2024In this paper, we link two existing approaches to derive counterfactuals: adaptations based on a causal graph, as suggested in Ple\v{c}ko and Meinshausen (2020) and optimal transport, as in De Lara et al. (2024). We extend "Knothe's rearrangement" Bonnotte (2013) and "triangular transport" Zech and Marzouk (2022a) to probabilistic graphical models, and use this counterfactual approach, referred to as sequential transport, to discuss individual fairness. After establishing the theoretical foundations of the proposed method, we demonstrate its application through numerical experiments on both synthetic and real datasets.
From Uncertainty to Precision: Enhancing Binary Classifier Performance through Calibration
Feb 12, 2024



The assessment of binary classifier performance traditionally centers on discriminative ability using metrics, such as accuracy. However, these metrics often disregard the model's inherent uncertainty, especially when dealing with sensitive decision-making domains, such as finance or healthcare. Given that model-predicted scores are commonly seen as event probabilities, calibration is crucial for accurate interpretation. In our study, we analyze the sensitivity of various calibration measures to score distortions and introduce a refined metric, the Local Calibration Score. Comparing recalibration methods, we advocate for local regressions, emphasizing their dual role as effective recalibration tools and facilitators of smoother visualizations. We apply these findings in a real-world scenario using Random Forest classifier and regressor to predict credit default while simultaneously measuring calibration during performance optimization.
Geospatial Disparities: A Case Study on Real Estate Prices in Paris
Jan 29, 2024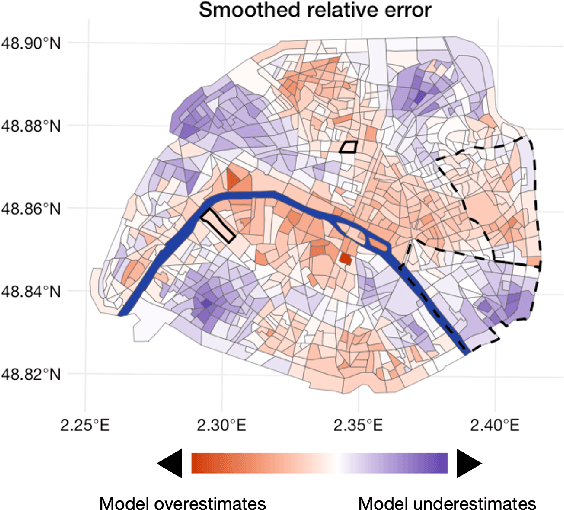

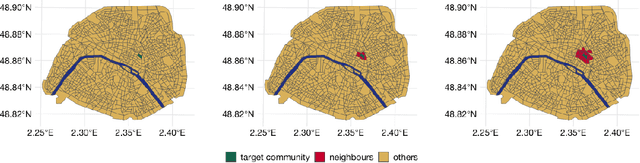
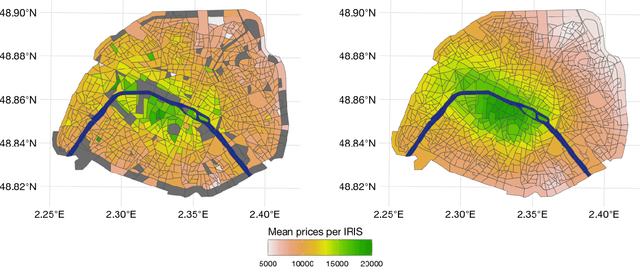
Driven by an increasing prevalence of trackers, ever more IoT sensors, and the declining cost of computing power, geospatial information has come to play a pivotal role in contemporary predictive models. While enhancing prognostic performance, geospatial data also has the potential to perpetuate many historical socio-economic patterns, raising concerns about a resurgence of biases and exclusionary practices, with their disproportionate impacts on society. Addressing this, our paper emphasizes the crucial need to identify and rectify such biases and calibration errors in predictive models, particularly as algorithms become more intricate and less interpretable. The increasing granularity of geospatial information further introduces ethical concerns, as choosing different geographical scales may exacerbate disparities akin to redlining and exclusionary zoning. To address these issues, we propose a toolkit for identifying and mitigating biases arising from geospatial data. Extending classical fairness definitions, we incorporate an ordinal regression case with spatial attributes, deviating from the binary classification focus. This extension allows us to gauge disparities stemming from data aggregation levels and advocates for a less interfering correction approach. Illustrating our methodology using a Parisian real estate dataset, we showcase practical applications and scrutinize the implications of choosing geographical aggregation levels for fairness and calibration measures.