 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbabilistic Scores of Classifiers, Calibration is not Enough
Aug 06, 2024In binary classification tasks, accurate representation of probabilistic predictions is essential for various real-world applications such as predicting payment defaults or assessing medical risks. The model must then be well-calibrated to ensure alignment between predicted probabilities and actual outcomes. However, when score heterogeneity deviates from the underlying data probability distribution, traditional calibration metrics lose reliability, failing to align score distribution with actual probabilities. In this study, we highlight approaches that prioritize optimizing the alignment between predicted scores and true probability distributions over minimizing traditional performance or calibration metrics. When employing tree-based models such as Random Forest and XGBoost, our analysis emphasizes the flexibility these models offer in tuning hyperparameters to minimize the Kullback-Leibler (KL) divergence between predicted and true distributions. Through extensive empirical analysis across 10 UCI datasets and simulations, we demonstrate that optimizing tree-based models based on KL divergence yields superior alignment between predicted scores and actual probabilities without significant performance loss. In real-world scenarios, the reference probability is determined a priori as a Beta distribution estimated through maximum likelihood. Conversely, minimizing traditional calibration metrics may lead to suboptimal results, characterized by notable performance declines and inferior KL values. Our findings reveal limitations in traditional calibration metrics, which could undermine the reliability of predictive models for critical decision-making.
From Uncertainty to Precision: Enhancing Binary Classifier Performance through Calibration
Feb 12, 2024



The assessment of binary classifier performance traditionally centers on discriminative ability using metrics, such as accuracy. However, these metrics often disregard the model's inherent uncertainty, especially when dealing with sensitive decision-making domains, such as finance or healthcare. Given that model-predicted scores are commonly seen as event probabilities, calibration is crucial for accurate interpretation. In our study, we analyze the sensitivity of various calibration measures to score distortions and introduce a refined metric, the Local Calibration Score. Comparing recalibration methods, we advocate for local regressions, emphasizing their dual role as effective recalibration tools and facilitators of smoother visualizations. We apply these findings in a real-world scenario using Random Forest classifier and regressor to predict credit default while simultaneously measuring calibration during performance optimization.
GAM(L)A: An econometric model for interpretable Machine Learning
Mar 17, 2022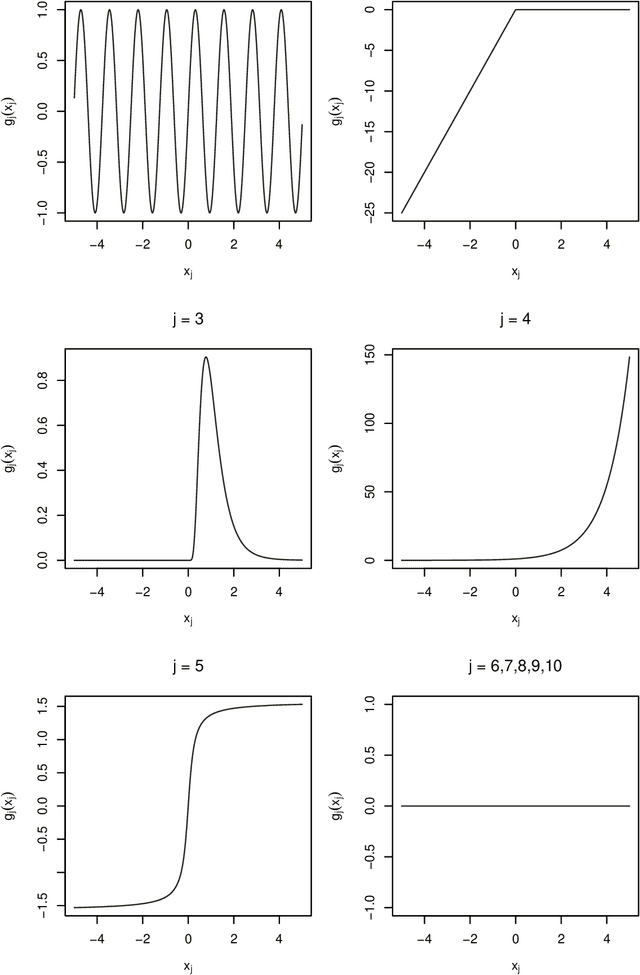
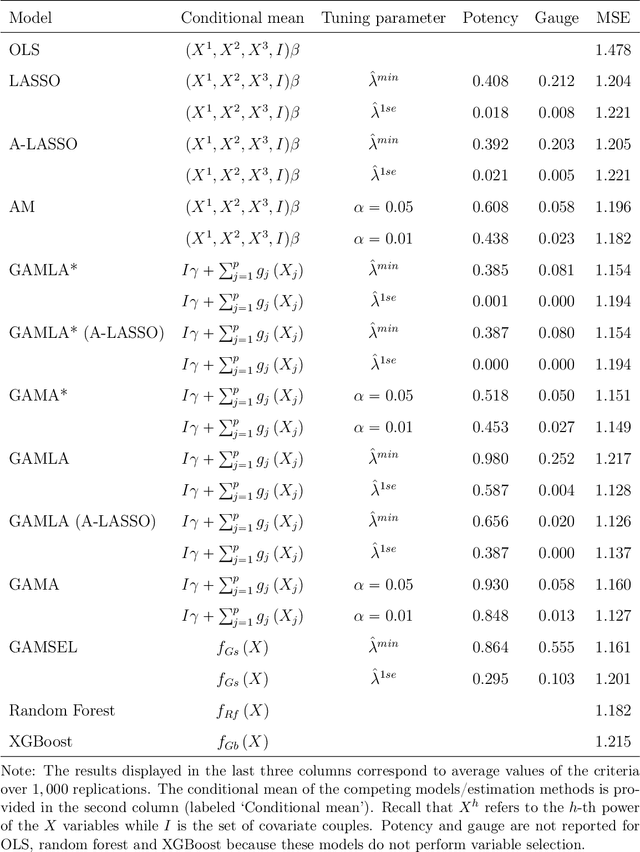
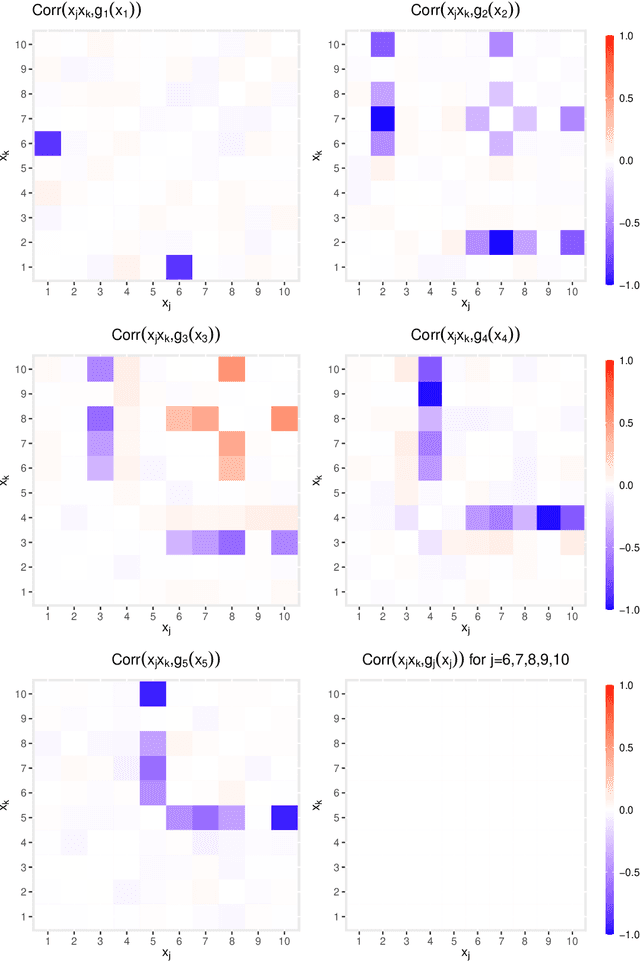
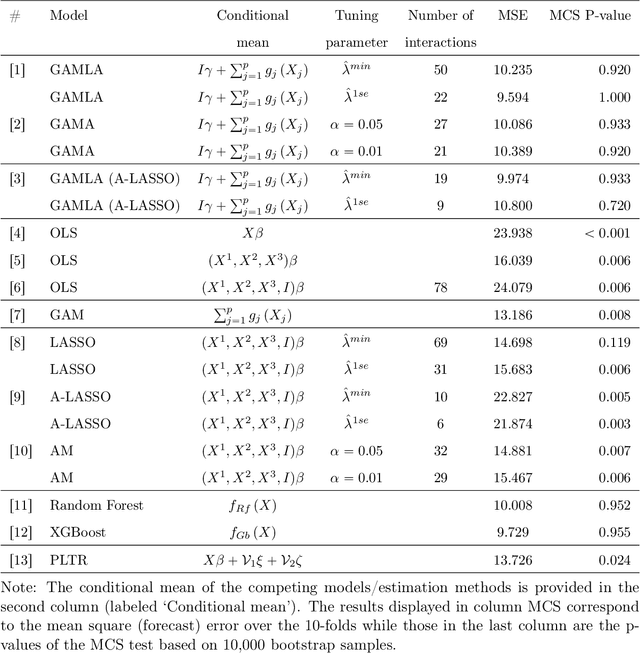
Despite their high predictive performance, random forest and gradient boosting are often considered as black boxes or uninterpretable models which has raised concerns from practitioners and regulators. As an alternative, we propose in this paper to use partial linear models that are inherently interpretable. Specifically, this article introduces GAM-lasso (GAMLA) and GAM-autometrics (GAMA), denoted as GAM(L)A in short. GAM(L)A combines parametric and non-parametric functions to accurately capture linearities and non-linearities prevailing between dependent and explanatory variables, and a variable selection procedure to control for overfitting issues. Estimation relies on a two-step procedure building upon the double residual method. We illustrate the predictive performance and interpretability of GAM(L)A on a regression and a classification problem. The results show that GAM(L)A outperforms parametric models augmented by quadratic, cubic and interaction effects. Moreover, the results also suggest that the performance of GAM(L)A is not significantly different from that of random forest and gradient boosting.