 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreserving Task-Relevant Information Under Linear Concept Removal
Jun 12, 2025



Modern neural networks often encode unwanted concepts alongside task-relevant information, leading to fairness and interpretability concerns. Existing post-hoc approaches can remove undesired concepts but often degrade useful signals. We introduce SPLICE-Simultaneous Projection for LInear concept removal and Covariance prEservation-which eliminates sensitive concepts from representations while exactly preserving their covariance with a target label. SPLICE achieves this via an oblique projection that "splices out" the unwanted direction yet protects important label correlations. Theoretically, it is the unique solution that removes linear concept predictability and maintains target covariance with minimal embedding distortion. Empirically, SPLICE outperforms baselines on benchmarks such as Bias in Bios and Winobias, removing protected attributes while minimally damaging main-task information.
Auditing a Dutch Public Sector Risk Profiling Algorithm Using an Unsupervised Bias Detection Tool
Feb 03, 2025Algorithms are increasingly used to automate or aid human decisions, yet recent research shows that these algorithms may exhibit bias across legally protected demographic groups. However, data on these groups may be unavailable to organizations or external auditors due to privacy legislation. This paper studies bias detection using an unsupervised clustering tool when data on demographic groups are unavailable. We collaborate with the Dutch Executive Agency for Education to audit an algorithm that was used to assign risk scores to college students at the national level in the Netherlands between 2012-2023. Our audit covers more than 250,000 students from the whole country. The unsupervised clustering tool highlights known disparities between students with a non-European migration background and Dutch origin. Our contributions are three-fold: (1) we assess bias in a real-world, large-scale and high-stakes decision-making process by a governmental organization; (2) we use simulation studies to highlight potential pitfalls of using the unsupervised clustering tool to detect true bias when demographic group data are unavailable and provide recommendations for valid inferences; (3) we provide the unsupervised clustering tool in an open-source library. Our work serves as a starting point for a deliberative assessment by human experts to evaluate potential discrimination in algorithmic-supported decision-making processes.
Optimizing importance weighting in the presence of sub-population shifts
Oct 18, 2024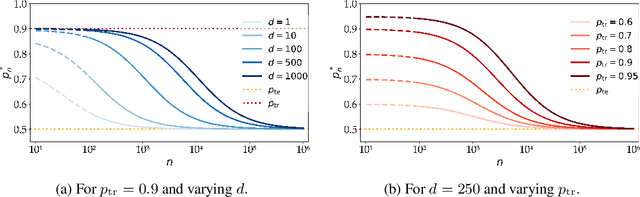
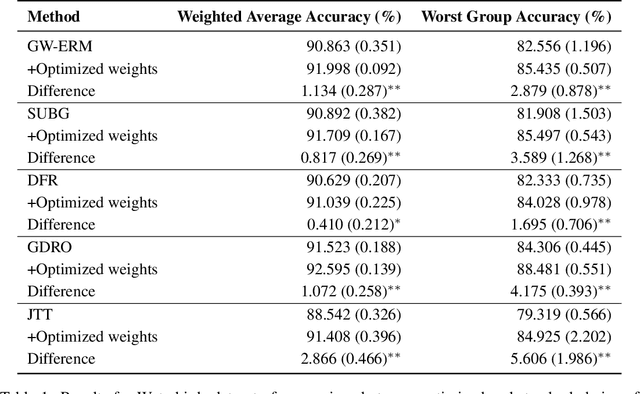
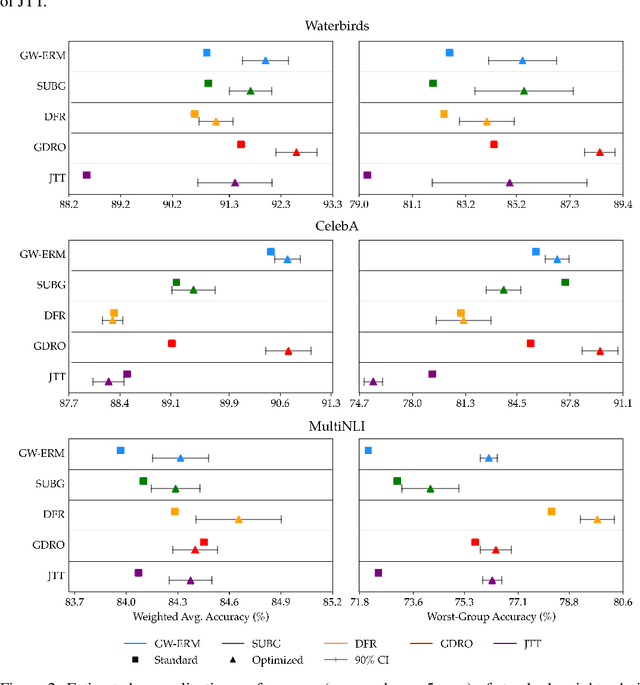
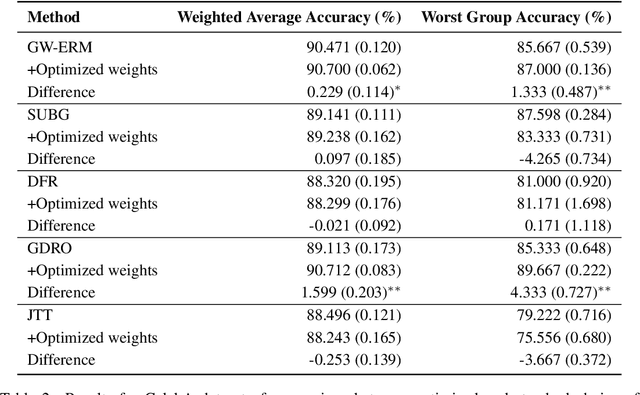
A distribution shift between the training and test data can severely harm performance of machine learning models. Importance weighting addresses this issue by assigning different weights to data points during training. We argue that existing heuristics for determining the weights are suboptimal, as they neglect the increase of the variance of the estimated model due to the finite sample size of the training data. We interpret the optimal weights in terms of a bias-variance trade-off, and propose a bi-level optimization procedure in which the weights and model parameters are optimized simultaneously. We apply this optimization to existing importance weighting techniques for last-layer retraining of deep neural networks in the presence of sub-population shifts and show empirically that optimizing weights significantly improves generalization performance.
Removing Spurious Concepts from Neural Network Representations via Joint Subspace Estimation
Oct 18, 2023

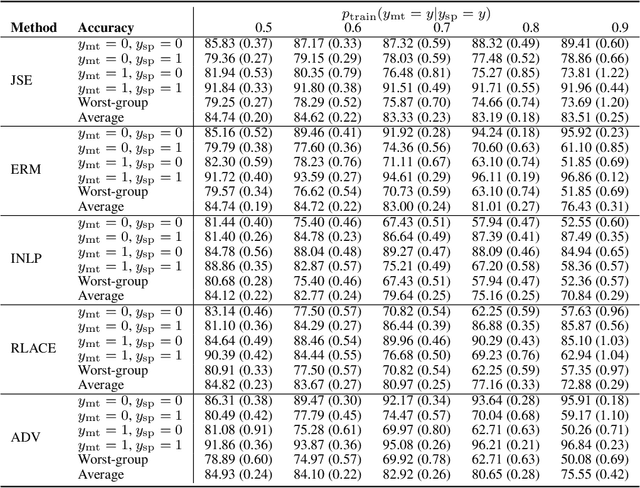

Out-of-distribution generalization in neural networks is often hampered by spurious correlations. A common strategy is to mitigate this by removing spurious concepts from the neural network representation of the data. Existing concept-removal methods tend to be overzealous by inadvertently eliminating features associated with the main task of the model, thereby harming model performance. We propose an iterative algorithm that separates spurious from main-task concepts by jointly identifying two low-dimensional orthogonal subspaces in the neural network representation. We evaluate the algorithm on benchmark datasets for computer vision (Waterbirds, CelebA) and natural language processing (MultiNLI), and show that it outperforms existing concept removal methods