 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatistical Foundations of LLM-based A/B Testing: A Surrogacy Framework for Human Causal Inference
Jun 18, 2026Organizations and researchers show increasing interest in using large language models (LLMs) in place of human participants in A/B tests, in the hope of experimenting faster and at lower cost. We study when a treatment effect estimated on LLM outcomes can recover the effect that would have been measured on the human population of interest. Distributional equivalence between LLM and human outcomes would make any standard estimator valid but is unrealistic. We therefore develop a statistical framework that adapts surrogate endpoint theory to LLMs, showing that calibrating LLM outcomes to human outcomes identifies the average treatment effect under surrogacy and comparability conditions that are jointly weaker than distributional equivalence. We present a falsification test for surrogacy and a bound on the worst-case bias from limited overlap between the LLM and human samples. We further show that the stochasticity inherent to LLMs can weaken surrogacy for identification while also introducing bias and variance during estimation, but that using an average over multiple LLM draws per unit as the surrogate mitigates these issues. Simulations validate the results, and an empirical application to A/B tests on Upworthy headlines shows that raw LLM predictions recover only 39\% of the human treatment effect while nonparametric calibration closes the gap. A central takeaway is that A/B testing on LLMs yields correct results only by assumption, whereas A/B testing on humans is correct by design, and that the required assumptions are hardest to justify precisely where A/B testing on LLMs promises the greatest benefit. We discuss the role of LLM choice, prompting, and temperature as design variables, the compounded challenge posed by long-term outcomes, and how to size human pilot studies for validation.
Logging Policy Design for Off-Policy Evaluation
May 14, 2026Off-policy evaluation (OPE) estimates the value of a target treatment policy (e.g., a recommender system) using data collected by a different logging policy. It enables high-stakes experimentation without live deployment, yet in practice accuracy depends heavily on the logging policy used to collect data for computing the estimate. We study how to design logging policies that minimize OPE error for given target policies. We characterize a fundamental reward-coverage tradeoff: concentrating probability mass on high-reward actions reduces variance but risks missing signal on actions the target policy may take. We propose a unifying framework for logging policy design and derive optimal policies in canonical informational regimes where the target policy and reward distribution are (i) known, (ii) unknown, and (iii) partially known through priors or noisy estimates at logging time. Our results provide actionable guidance for firms choosing among multiple candidate recommendation systems. We demonstrate the importance of treatment selection when gathering data for OPE, and describe theoretically optimal approaches when this is a firm's primary objective. We also distill practical design principles for selecting logging policies when operational constraints prevent implementing the theoretical optimum.
Detecting and Mitigating Group Bias in Heterogeneous Treatment Effects
Feb 23, 2026Heterogeneous treatment effects (HTEs) are increasingly estimated using machine learning models that produce highly personalized predictions of treatment effects. In practice, however, predicted treatment effects are rarely interpreted, reported, or audited at the individual level but, instead, are often aggregated to broader subgroups, such as demographic segments, risk strata, or markets. We show that such aggregation can induce systematic bias of the group-level causal effect: even when models for predicting the individual-level conditional average treatment effect (CATE) are correctly specified and trained on data from randomized experiments, aggregating the predicted CATEs up to the group level does not, in general, recover the corresponding group average treatment effect (GATE). We develop a unified statistical framework to detect and mitigate this form of group bias in randomized experiments. We first define group bias as the discrepancy between the model-implied and experimentally identified GATEs, derive an asymptotically normal estimator, and then provide a simple-to-implement statistical test. For mitigation, we propose a shrinkage-based bias-correction, and show that the theoretically optimal and empirically feasible solutions have closed-form expressions. The framework is fully general, imposes minimal assumptions, and only requires computing sample moments. We analyze the economic implications of mitigating detected group bias for profit-maximizing personalized targeting, thereby characterizing when bias correction alters targeting decisions and profits, and the trade-offs involved. Applications to large-scale experimental data at major digital platforms validate our theoretical results and demonstrate empirical performance.
Auditing a Dutch Public Sector Risk Profiling Algorithm Using an Unsupervised Bias Detection Tool
Feb 03, 2025Algorithms are increasingly used to automate or aid human decisions, yet recent research shows that these algorithms may exhibit bias across legally protected demographic groups. However, data on these groups may be unavailable to organizations or external auditors due to privacy legislation. This paper studies bias detection using an unsupervised clustering tool when data on demographic groups are unavailable. We collaborate with the Dutch Executive Agency for Education to audit an algorithm that was used to assign risk scores to college students at the national level in the Netherlands between 2012-2023. Our audit covers more than 250,000 students from the whole country. The unsupervised clustering tool highlights known disparities between students with a non-European migration background and Dutch origin. Our contributions are three-fold: (1) we assess bias in a real-world, large-scale and high-stakes decision-making process by a governmental organization; (2) we use simulation studies to highlight potential pitfalls of using the unsupervised clustering tool to detect true bias when demographic group data are unavailable and provide recommendations for valid inferences; (3) we provide the unsupervised clustering tool in an open-source library. Our work serves as a starting point for a deliberative assessment by human experts to evaluate potential discrimination in algorithmic-supported decision-making processes.
EventChat: Implementation and user-centric evaluation of a large language model-driven conversational recommender system for exploring leisure events in an SME context
Jul 05, 2024



Large language models (LLMs) present an enormous evolution in the strategic potential of conversational recommender systems (CRS). Yet to date, research has predominantly focused upon technical frameworks to implement LLM-driven CRS, rather than end-user evaluations or strategic implications for firms, particularly from the perspective of a small to medium enterprises (SME) that makeup the bedrock of the global economy. In the current paper, we detail the design of an LLM-driven CRS in an SME setting, and its subsequent performance in the field using both objective system metrics and subjective user evaluations. While doing so, we additionally outline a short-form revised ResQue model for evaluating LLM-driven CRS, enabling replicability in a rapidly evolving field. Our results reveal good system performance from a user experience perspective (85.5% recommendation accuracy) but underscore latency, cost, and quality issues challenging business viability. Notably, with a median cost of $0.04 per interaction and a latency of 5.7s, cost-effectiveness and response time emerge as crucial areas for achieving a more user-friendly and economically viable LLM-driven CRS for SME settings. One major driver of these costs is the use of an advanced LLM as a ranker within the retrieval-augmented generation (RAG) technique. Our results additionally indicate that relying solely on approaches such as Prompt-based learning with ChatGPT as the underlying LLM makes it challenging to achieve satisfying quality in a production environment. Strategic considerations for SMEs deploying an LLM-driven CRS are outlined, particularly considering trade-offs in the current technical landscape.
Learning Optimal Dynamic Treatment Regimes Using Causal Tree Methods in Medicine
Apr 14, 2022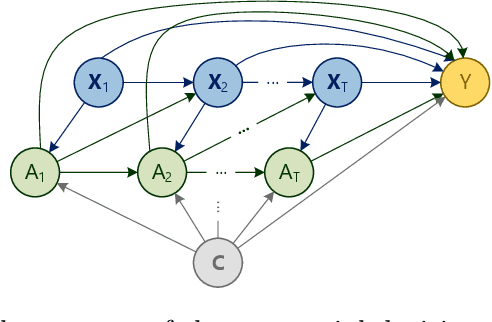
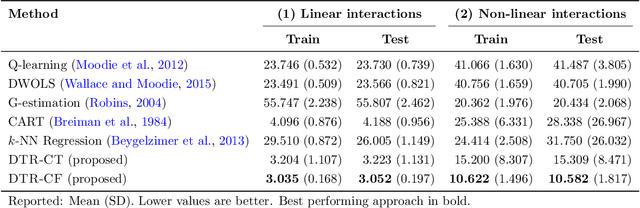
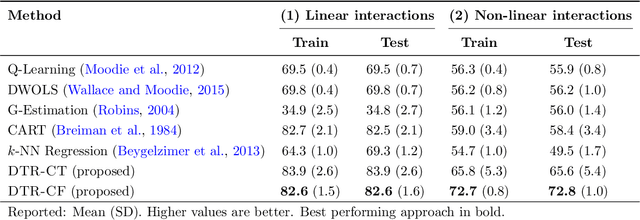
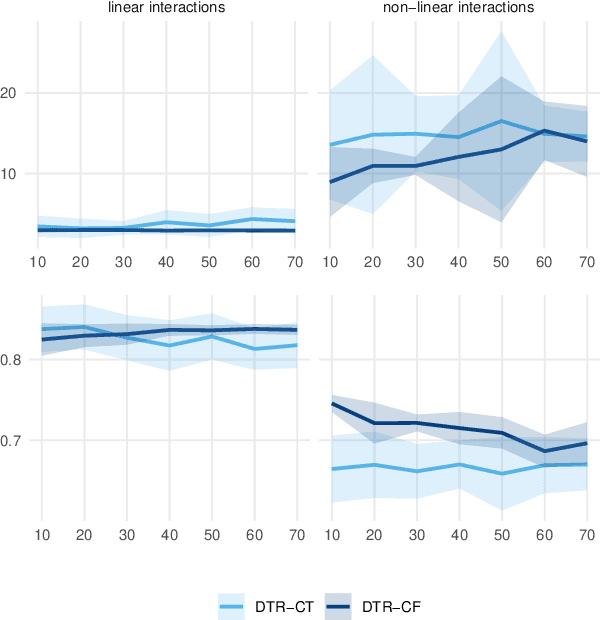
Dynamic treatment regimes (DTRs) are used in medicine to tailor sequential treatment decisions to patients by considering patient heterogeneity. Common methods for learning optimal DTRs, however, have shortcomings: they are typically based on outcome prediction and not treatment effect estimation, or they use linear models that are restrictive for patient data from modern electronic health records. To address these shortcomings, we develop two novel methods for learning optimal DTRs that effectively handle complex patient data. We call our methods DTR-CT and DTR-CF. Our methods are based on a data-driven estimation of heterogeneous treatment effects using causal tree methods, specifically causal trees and causal forests, that learn non-linear relationships, control for time-varying confounding, are doubly robust, and explainable. To the best of our knowledge, our paper is the first that adapts causal tree methods for learning optimal DTRs. We evaluate our proposed methods using synthetic data and then apply them to real-world data from intensive care units. Our methods outperform state-of-the-art baselines in terms of cumulative regret and percentage of optimal decisions by a considerable margin. Our work improves treatment recommendations from electronic health record and is thus of direct relevance for personalized medicine.