 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing importance weighting in the presence of sub-population shifts
Oct 18, 2024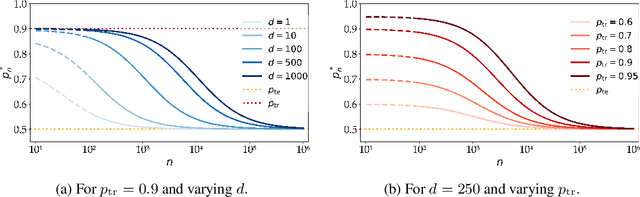
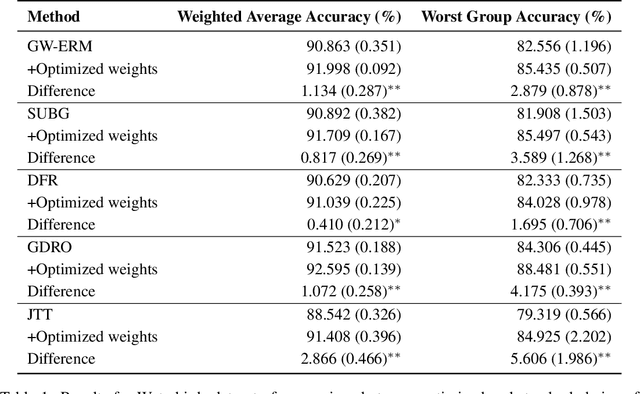
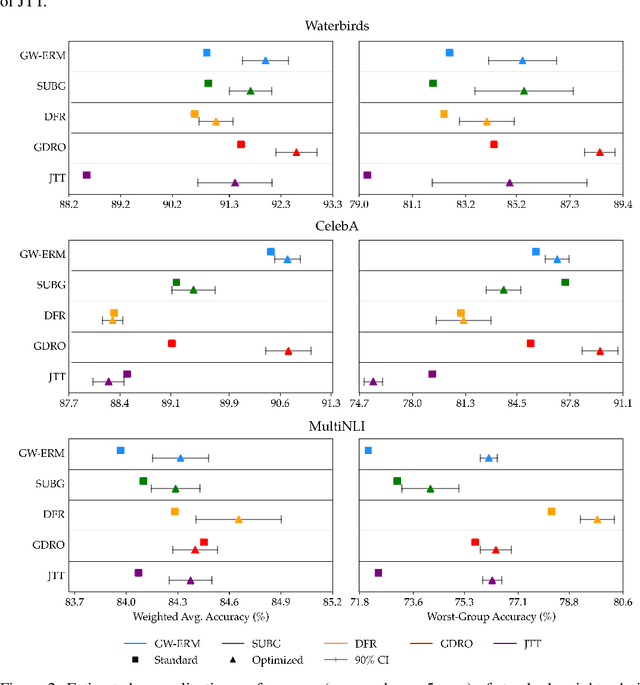
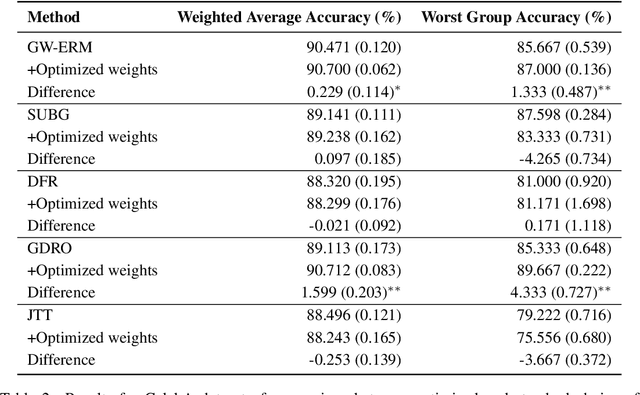
A distribution shift between the training and test data can severely harm performance of machine learning models. Importance weighting addresses this issue by assigning different weights to data points during training. We argue that existing heuristics for determining the weights are suboptimal, as they neglect the increase of the variance of the estimated model due to the finite sample size of the training data. We interpret the optimal weights in terms of a bias-variance trade-off, and propose a bi-level optimization procedure in which the weights and model parameters are optimized simultaneously. We apply this optimization to existing importance weighting techniques for last-layer retraining of deep neural networks in the presence of sub-population shifts and show empirically that optimizing weights significantly improves generalization performance.
Removing Spurious Concepts from Neural Network Representations via Joint Subspace Estimation
Oct 18, 2023

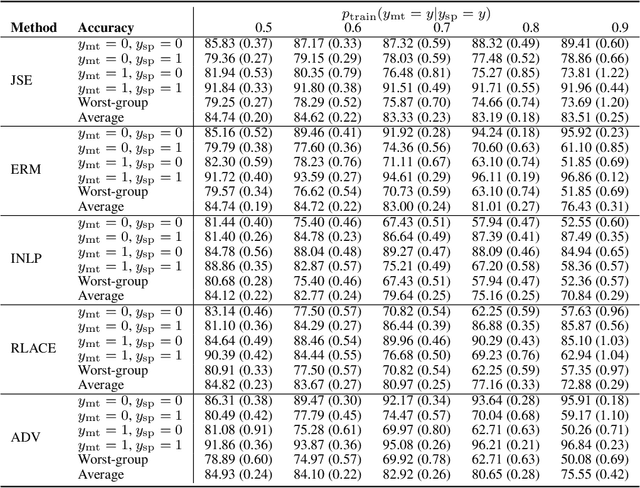

Out-of-distribution generalization in neural networks is often hampered by spurious correlations. A common strategy is to mitigate this by removing spurious concepts from the neural network representation of the data. Existing concept-removal methods tend to be overzealous by inadvertently eliminating features associated with the main task of the model, thereby harming model performance. We propose an iterative algorithm that separates spurious from main-task concepts by jointly identifying two low-dimensional orthogonal subspaces in the neural network representation. We evaluate the algorithm on benchmark datasets for computer vision (Waterbirds, CelebA) and natural language processing (MultiNLI), and show that it outperforms existing concept removal methods