 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoftED: Metrics for Soft Evaluation of Time Series Event Detection
Apr 02, 2023



Time series event detection methods are evaluated mainly by standard classification metrics that focus solely on detection accuracy. However, inaccuracy in detecting an event can often result from its preceding or delayed effects reflected in neighboring detections. These detections are valuable to trigger necessary actions or help mitigate unwelcome consequences. In this context, current metrics are insufficient and inadequate for the context of event detection. There is a demand for metrics that incorporate both the concept of time and temporal tolerance for neighboring detections. This paper introduces SoftED metrics, a new set of metrics designed for soft evaluating event detection methods. They enable the evaluation of both detection accuracy and the degree to which their detections represent events. They improved event detection evaluation by associating events and their representative detections, incorporating temporal tolerance in over 36\% of experiments compared to the usual classification metrics. SoftED metrics were validated by domain specialists that indicated their contribution to detection evaluation and method selection.
A Distributed Collaborative Filtering Algorithm Using Multiple Data Sources
Jul 16, 2018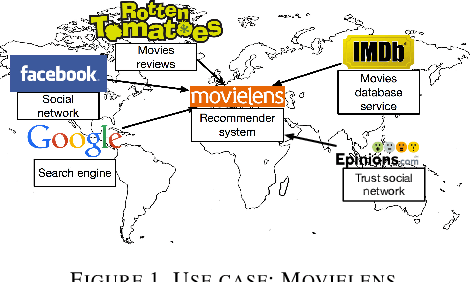
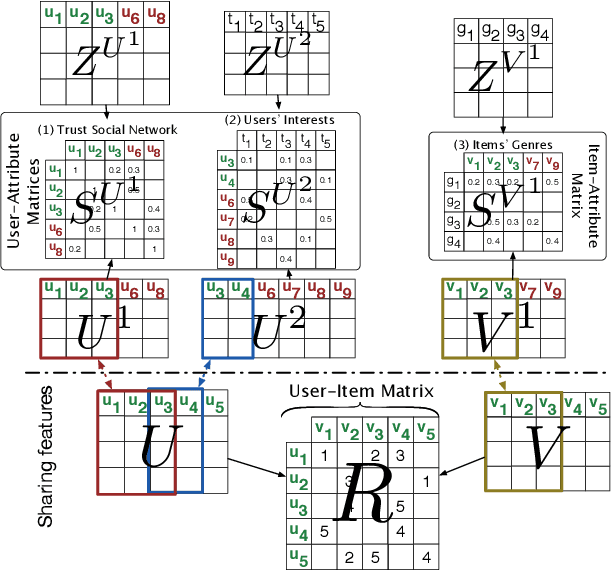
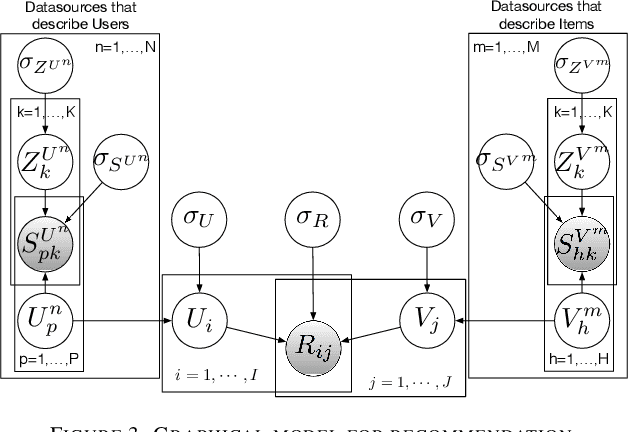
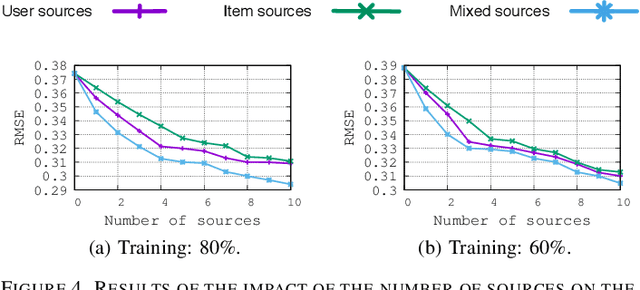
Collaborative Filtering (CF) is one of the most commonly used recommendation methods. CF consists in predicting whether, or how much, a user will like (or dislike) an item by leveraging the knowledge of the user's preferences as well as that of other users. In practice, users interact and express their opinion on only a small subset of items, which makes the corresponding user-item rating matrix very sparse. Such data sparsity yields two main problems for recommender systems: (1) the lack of data to effectively model users' preferences, and (2) the lack of data to effectively model item characteristics. However, there are often many other data sources that are available to a recommender system provider, which can describe user interests and item characteristics (e.g., users' social network, tags associated to items, etc.). These valuable data sources may supply useful information to enhance a recommendation system in modeling users' preferences and item characteristics more accurately and thus, hopefully, to make recommenders more precise. For various reasons, these data sources may be managed by clusters of different data centers, thus requiring the development of distributed solutions. In this paper, we propose a new distributed collaborative filtering algorithm, which exploits and combines multiple and diverse data sources to improve recommendation quality. Our experimental evaluation using real datasets shows the effectiveness of our algorithm compared to state-of-the-art recommendation algorithms.