 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReimagining Social Robots as Recommender Systems: Foundations, Framework, and Applications
Jan 27, 2026Personalization in social robots refers to the ability of the robot to meet the needs and/or preferences of an individual user. Existing approaches typically rely on large language models (LLMs) to generate context-aware responses based on user metadata and historical interactions or on adaptive methods such as reinforcement learning (RL) to learn from users' immediate reactions in real time. However, these approaches fall short of comprehensively capturing user preferences-including long-term, short-term, and fine-grained aspects-, and of using them to rank and select actions, proactively personalize interactions, and ensure ethically responsible adaptations. To address the limitations, we propose drawing on recommender systems (RSs), which specialize in modeling user preferences and providing personalized recommendations. To ensure the integration of RS techniques is well-grounded and seamless throughout the social robot pipeline, we (i) align the paradigms underlying social robots and RSs, (ii) identify key techniques that can enhance personalization in social robots, and (iii) design them as modular, plug-and-play components. This work not only establishes a framework for integrating RS techniques into social robots but also opens a pathway for deep collaboration between the RS and HRI communities, accelerating innovation in both fields.
Interactive Disambiguation for Behavior Tree Execution
Mar 10, 2022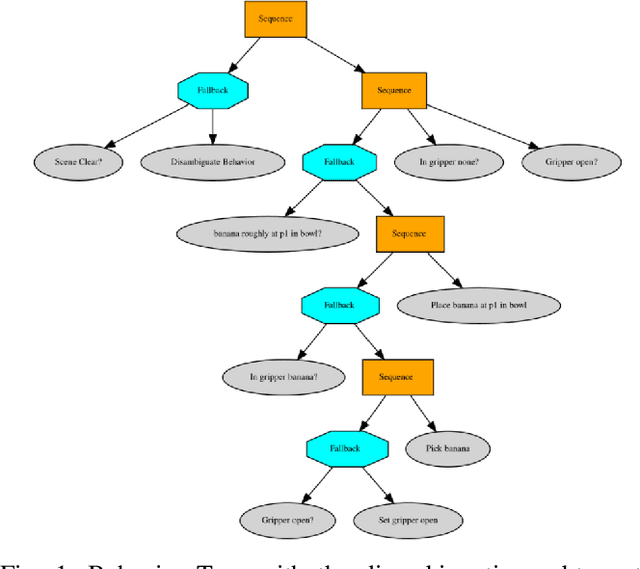
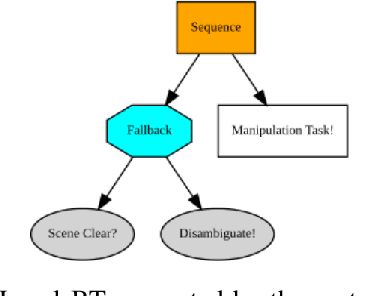

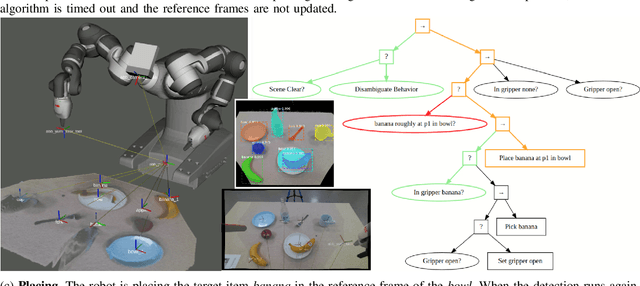
In recent years, robots are used in an increasing variety of tasks, especially by small- and medium- sized enterprises. These tasks are usually fast-changing, they have a collaborative scenario and happen in unpredictable environments with possible ambiguities. It is important to have methods capable of generating robot programs easily, that are made as general as possible by handling uncertainties. We present a system that integrates a method to learn Behavior Trees (BTs) from demonstration for pick and place tasks, with a framework that uses verbal interaction to ask follow-up clarification questions to resolve ambiguities. During the execution of a task, the system asks for user input when there is need to disambiguate an object in the scene, when the targets of the task are objects of a same type that are present in multiple instances. The integrated system is demonstrated on different scenarios of a pick and place task, with increasing level of ambiguities. The code used for this paper is made publicly available.
Open Challenges on Generating Referring Expressions for Human-Robot Interaction
Apr 19, 2021
Effective verbal communication is crucial in human-robot collaboration. When a robot helps its human partner to complete a task with verbal instructions, referring expressions are commonly employed during the interaction. Despite many studies on generating referring expressions, crucial open challenges still remain for effective interaction. In this work, we discuss some of these challenges (i.e., using contextual information, taking users' perspectives, and handling misinterpretations in an autonomous manner).
Learning to Generate Unambiguous Spatial Referring Expressions for Real-World Environments
Apr 15, 2019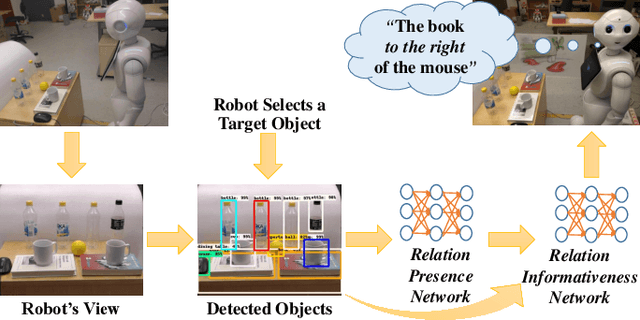


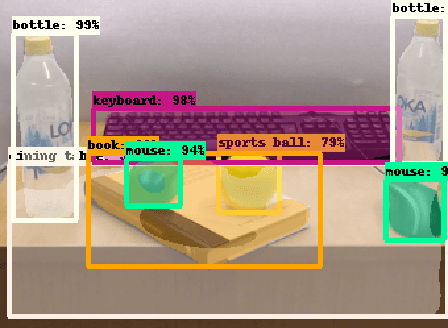
Referring to objects in a natural and unambiguous manner is crucial for effective human-robot interaction. Previous research on learning-based referring expressions has focused primarily on comprehension tasks, while generating referring expressions is still mostly limited to rule-based methods. In this work, we propose a two-stage approach that relies on deep learning for estimating spatial relations to describe an object naturally and unambiguously with a referring expression. We evaluate our method in ambiguous environments (e.g., environments that include very similar objects with similar relationships) relative to a state-of-the-art algorithm. We show that our method generates referring expressions that people find to be more accurate ($\sim$30% better) and would prefer to use ($\sim$32% more often).
CINet: A Learning Based Approach to Incremental Context Modeling in Robots
Jul 29, 2018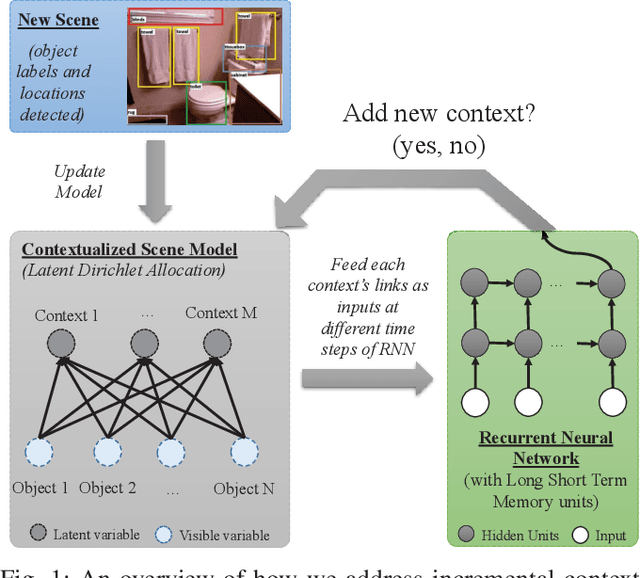

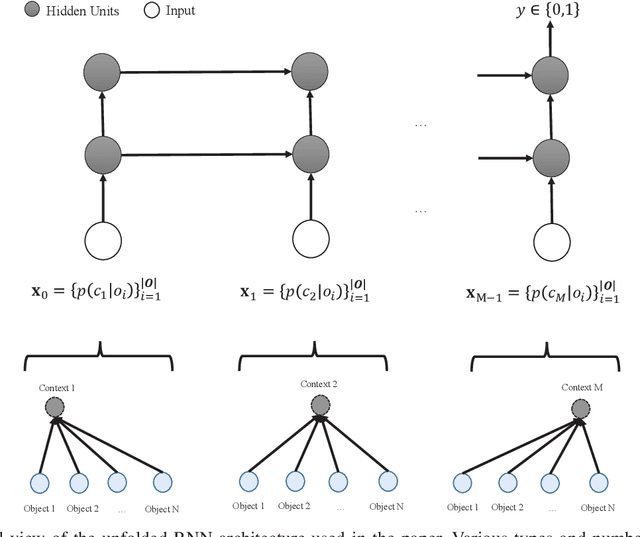
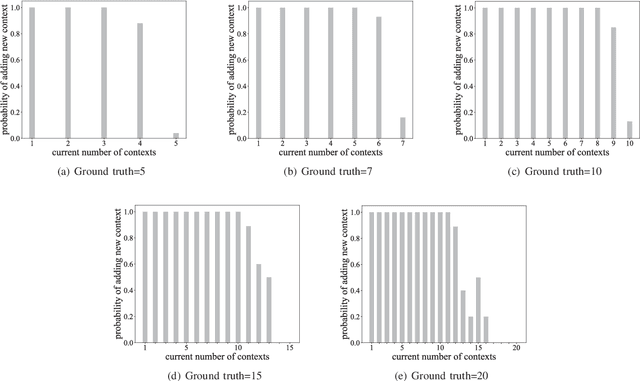
There have been several attempts at modeling context in robots. However, either these attempts assume a fixed number of contexts or use a rule-based approach to determine when to increment the number of contexts. In this paper, we pose the task of when to increment as a learning problem, which we solve using a Recurrent Neural Network. We show that the network successfully (with 98\% testing accuracy) learns to predict when to increment, and demonstrate, in a scene modeling problem (where the correct number of contexts is not known), that the robot increments the number of contexts in an expected manner (i.e., the entropy of the system is reduced). We also present how the incremental model can be used for various scene reasoning tasks.
A Deep Incremental Boltzmann Machine for Modeling Context in Robots
Mar 02, 2018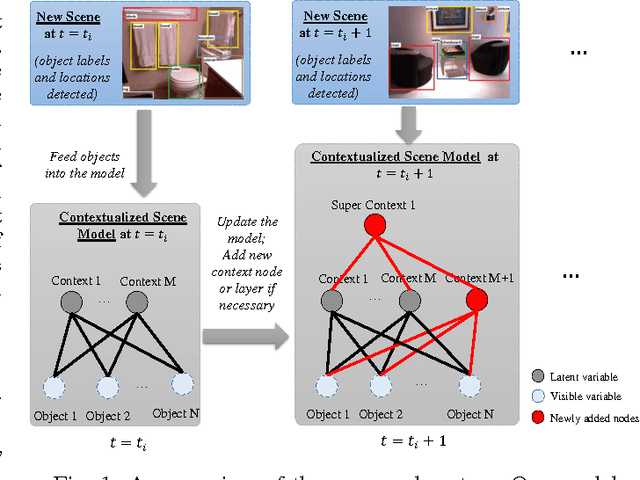
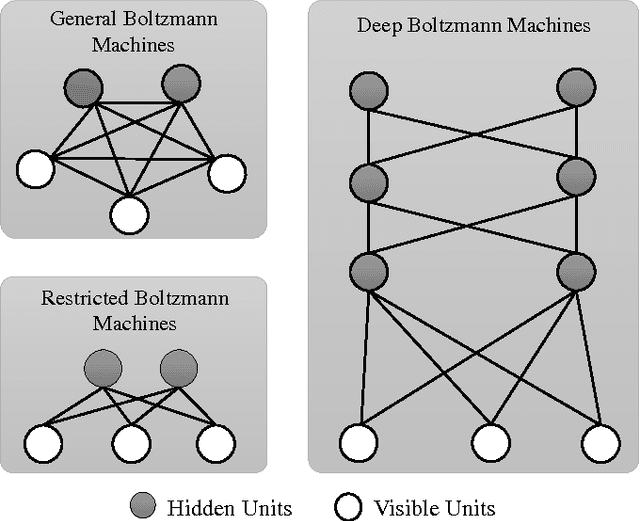
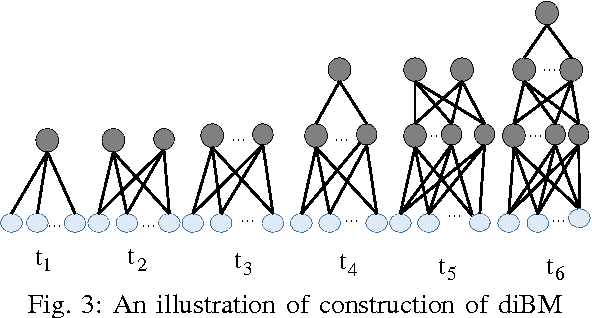
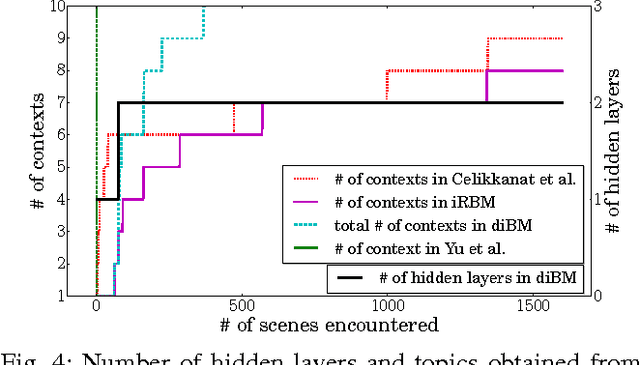
Context is an essential capability for robots that are to be as adaptive as possible in challenging environments. Although there are many context modeling efforts, they assume a fixed structure and number of contexts. In this paper, we propose an incremental deep model that extends Restricted Boltzmann Machines. Our model gets one scene at a time, and gradually extends the contextual model when necessary, either by adding a new context or a new context layer to form a hierarchy. We show on a scene classification benchmark that our method converges to a good estimate of the contexts of the scenes, and performs better or on-par on several tasks compared to other incremental models or non-incremental models.