 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Formal Semantics for Capabilities and Skills: Model Context Protocol in Manufacturing
Jun 12, 2025Explicit modeling of capabilities and skills -- whether based on ontologies, Asset Administration Shells, or other technologies -- requires considerable manual effort and often results in representations that are not easily accessible to Large Language Models (LLMs). In this work-in-progress paper, we present an alternative approach based on the recently introduced Model Context Protocol (MCP). MCP allows systems to expose functionality through a standardized interface that is directly consumable by LLM-based agents. We conduct a prototypical evaluation on a laboratory-scale manufacturing system, where resource functions are made available via MCP. A general-purpose LLM is then tasked with planning and executing a multi-step process, including constraint handling and the invocation of resource functions via MCP. The results indicate that such an approach can enable flexible industrial automation without relying on explicit semantic models. This work lays the basis for further exploration of external tool integration in LLM-driven production systems.
Automated Validation of Textual Constraints Against AutomationML via LLMs and SHACL
Jun 12, 2025AutomationML (AML) enables standardized data exchange in engineering, yet existing recommendations for proper AML modeling are typically formulated as informal and textual constraints. These constraints cannot be validated automatically within AML itself. This work-in-progress paper introduces a pipeline to formalize and verify such constraints. First, AML models are mapped to OWL ontologies via RML and SPARQL. In addition, a Large Language Model translates textual rules into SHACL constraints, which are then validated against the previously generated AML ontology. Finally, SHACL validation results are automatically interpreted in natural language. The approach is demonstrated on a sample AML recommendation. Results show that even complex modeling rules can be semi-automatically checked -- without requiring users to understand formal methods or ontology technologies.
Integrating AI Planning Semantics into SysML System Models for Automated PDDL File Generation
Jun 07, 2025This paper presents a SysML profile that enables the direct integration of planning semantics based on the Planning Domain Definition Language (PDDL) into system models. Reusable stereotypes are defined for key PDDL concepts such as types, predicates, functions and actions, while formal OCL constraints ensure syntactic consistency. The profile was derived from the Backus-Naur Form (BNF) definition of PDDL 3.1 to align with SysML modeling practices. A case study from aircraft manufacturing demonstrates the application of the profile: a robotic system with interchangeable end effectors is modeled and enriched to generate both domain and problem descriptions in PDDL format. These are used as input to a PDDL solver to derive optimized execution plans. The approach supports automated and model-based generation of planning descriptions and provides a reusable bridge between system modeling and AI planning in engineering design.
Capability-Driven Skill Generation with LLMs: A RAG-Based Approach for Reusing Existing Libraries and Interfaces
May 06, 2025



Modern automation systems increasingly rely on modular architectures, with capabilities and skills as one solution approach. Capabilities define the functions of resources in a machine-readable form and skills provide the concrete implementations that realize those capabilities. However, the development of a skill implementation conforming to a corresponding capability remains a time-consuming and challenging task. In this paper, we present a method that treats capabilities as contracts for skill implementations and leverages large language models to generate executable code based on natural language user input. A key feature of our approach is the integration of existing software libraries and interface technologies, enabling the generation of skill implementations across different target languages. We introduce a framework that allows users to incorporate their own libraries and resource interfaces into the code generation process through a retrieval-augmented generation architecture. The proposed method is evaluated using an autonomous mobile robot controlled via Python and ROS 2, demonstrating the feasibility and flexibility of the approach.
Leveraging LLM Agents and Digital Twins for Fault Handling in Process Plants
May 04, 2025Advances in Automation and Artificial Intelligence continue to enhance the autonomy of process plants in handling various operational scenarios. However, certain tasks, such as fault handling, remain challenging, as they rely heavily on human expertise. This highlights the need for systematic, knowledge-based methods. To address this gap, we propose a methodological framework that integrates Large Language Model (LLM) agents with a Digital Twin environment. The LLM agents continuously interpret system states and initiate control actions, including responses to unexpected faults, with the goal of returning the system to normal operation. In this context, the Digital Twin acts both as a structured repository of plant-specific engineering knowledge for agent prompting and as a simulation platform for the systematic validation and verification of the generated corrective control actions. The evaluation using a mixing module of a process plant demonstrates that the proposed framework is capable not only of autonomously controlling the mixing module, but also of generating effective corrective actions to mitigate a pipe clogging with only a few reprompts.
Automatic Mapping of AutomationML Files to Ontologies for Graph Queries and Validation
Apr 30, 2025



AutomationML has seen widespread adoption as an open data exchange format in the automation domain. It is an open and vendor neutral standard based on the extensible markup language XML. However, AutomationML extends XML with additional semantics, that limit the applicability of common XML-tools for applications like querying or data validation. This article provides practitioners with 1) an up-to-date ontology of the concepts in the AutomationML-standard, as well as 2) a declarative mapping to automatically transform any AutomationML model into RDF triples. Together, these artifacts allow practitioners an easy integration of AutomationML information into industrial knowledge graphs. A study on examples from the automation domain concludes that transforming AutomationML to OWL opens up new powerful ways for querying and validation that are impossible without transformation.
Model-based Workflow for the Automated Generation of PDDL Descriptions
Aug 15, 2024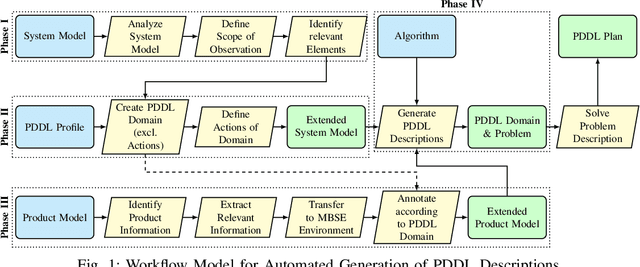
Manually creating Planning Domain Definition Language (PDDL) descriptions is difficult, error-prone, and requires extensive expert knowledge. However, this knowledge is already embedded in engineering models and can be reused. Therefore, this contribution presents a comprehensive workflow for the automated generation of PDDL descriptions from integrated system and product models. The proposed workflow leverages Model-Based Systems Engineering (MBSE) to organize and manage system and product information, translating it automatically into PDDL syntax for planning purposes. By connecting system and product models with planning aspects, it ensures that changes in these models are quickly reflected in updated PDDL descriptions, facilitating efficient and adaptable planning processes. The workflow is validated within a use case from aircraft assembly.
Chatbot-Based Ontology Interaction Using Large Language Models and Domain-Specific Standards
Jul 22, 2024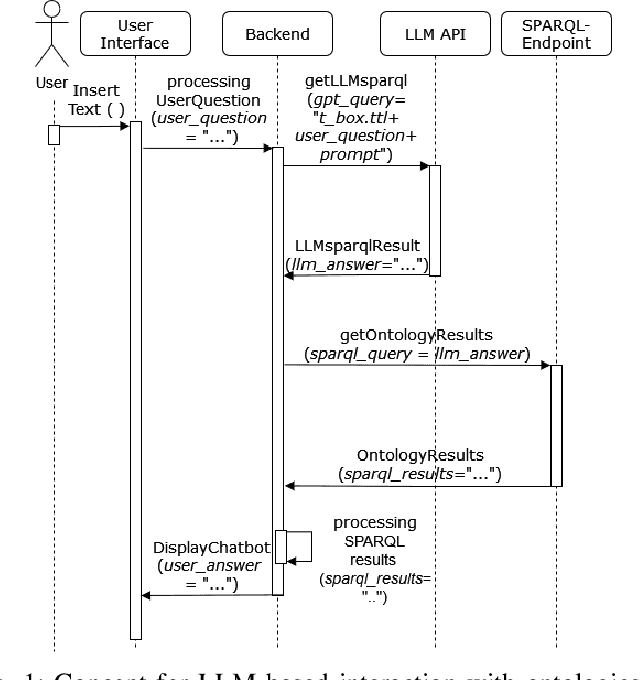

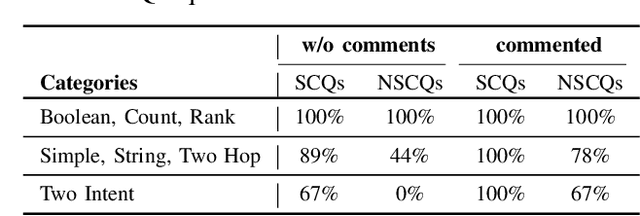
The following contribution introduces a concept that employs Large Language Models (LLMs) and a chatbot interface to enhance SPARQL query generation for ontologies, thereby facilitating intuitive access to formalized knowledge. Utilizing natural language inputs, the system converts user inquiries into accurate SPARQL queries that strictly query the factual content of the ontology, effectively preventing misinformation or fabrication by the LLM. To enhance the quality and precision of outcomes, additional textual information from established domain-specific standards is integrated into the ontology for precise descriptions of its concepts and relationships. An experimental study assesses the accuracy of generated SPARQL queries, revealing significant benefits of using LLMs for querying ontologies and highlighting areas for future research.
Integrating Ontology Design with the CRISP-DM in the context of Cyber-Physical Systems Maintenance
Jul 09, 2024



In the following contribution, a method is introduced that integrates domain expert-centric ontology design with the Cross-Industry Standard Process for Data Mining (CRISP-DM). This approach aims to efficiently build an application-specific ontology tailored to the corrective maintenance of Cyber-Physical Systems (CPS). The proposed method is divided into three phases. In phase one, ontology requirements are systematically specified, defining the relevant knowledge scope. Accordingly, CPS life cycle data is contextualized in phase two using domain-specific ontological artifacts. This formalized domain knowledge is then utilized in the CRISP-DM to efficiently extract new insights from the data. Finally, the newly developed data-driven model is employed to populate and expand the ontology. Thus, information extracted from this model is semantically annotated and aligned with the existing ontology in phase three. The applicability of this method has been evaluated in an anomaly detection case study for a modular process plant.
A Formal Model for Artificial Intelligence Applications in Automation Systems
Jul 03, 2024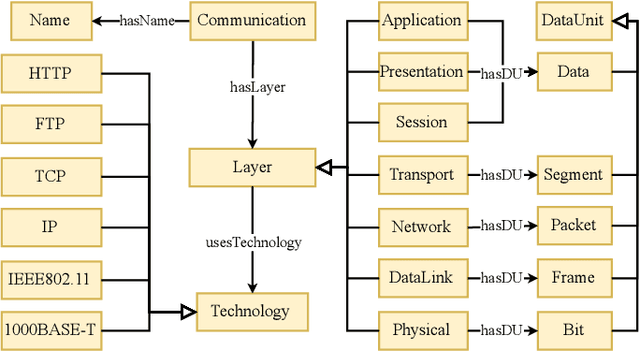
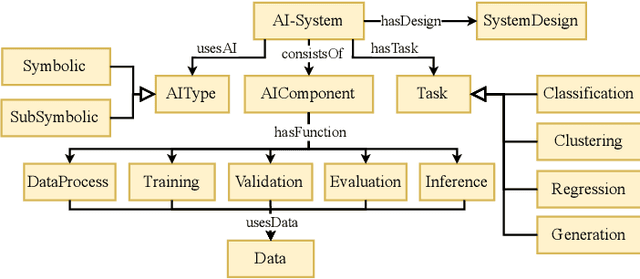
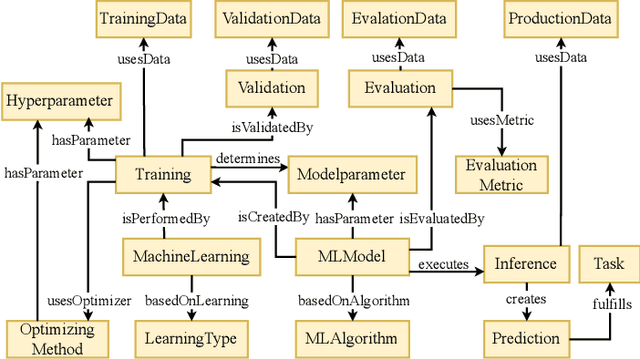
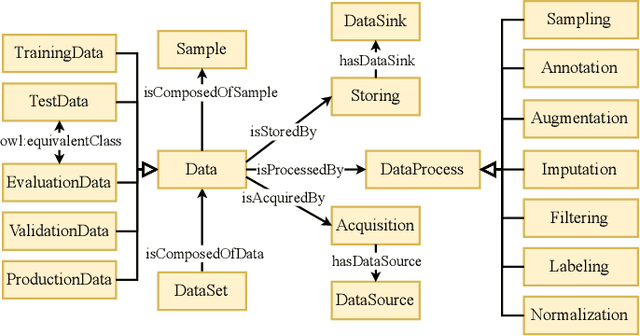
The integration of Artificial Intelligence (AI) into automation systems has the potential to enhance efficiency and to address currently unsolved existing technical challenges. However, the industry-wide adoption of AI is hindered by the lack of standardized documentation for the complex compositions of automation systems, AI software, production hardware, and their interdependencies. This paper proposes a formal model using standards and ontologies to provide clear and structured documentation of AI applications in automation systems. The proposed information model for artificial intelligence in automation systems (AIAS) utilizes ontology design patterns to map and link various aspects of automation systems and AI software. Validated through a practical example, the model demonstrates its effectiveness in improving documentation practices and aiding the sustainable implementation of AI in industrial settings.