 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMD-FUSE: Learning and Combining Kernels for Two-Sample Testing Without Data Splitting
Jun 14, 2023We propose novel statistics which maximise the power of a two-sample test based on the Maximum Mean Discrepancy (MMD), by adapting over the set of kernels used in defining it. For finite sets, this reduces to combining (normalised) MMD values under each of these kernels via a weighted soft maximum. Exponential concentration bounds are proved for our proposed statistics under the null and alternative. We further show how these kernels can be chosen in a data-dependent but permutation-independent way, in a well-calibrated test, avoiding data splitting. This technique applies more broadly to general permutation-based MMD testing, and includes the use of deep kernels with features learnt using unsupervised models such as auto-encoders. We highlight the applicability of our MMD-FUSE test on both synthetic low-dimensional and real-world high-dimensional data, and compare its performance in terms of power against current state-of-the-art kernel tests.
Tighter PAC-Bayes Generalisation Bounds by Leveraging Example Difficulty
Oct 20, 2022
We introduce a modified version of the excess risk, which can be used to obtain tighter, fast-rate PAC-Bayesian generalisation bounds. This modified excess risk leverages information about the relative hardness of data examples to reduce the variance of its empirical counterpart, tightening the bound. We combine this with a new bound for $[-1, 1]$-valued (and potentially non-independent) signed losses, which is more favourable when they empirically have low variance around $0$. The primary new technical tool is a novel result for sequences of interdependent random vectors which may be of independent interest. We empirically evaluate these new bounds on a number of real-world datasets.
A Note on the Efficient Evaluation of PAC-Bayes Bounds
Sep 12, 2022When utilising PAC-Bayes theory for risk certification, it is usually necessary to estimate and bound the Gibbs risk of the PAC-Bayes posterior. Many works in the literature employ a method for this which requires a large number of passes of the dataset, incurring high computational cost. This manuscript presents a very general alternative which makes computational savings on the order of the dataset size.
On Margins and Generalisation for Voting Classifiers
Jun 09, 2022

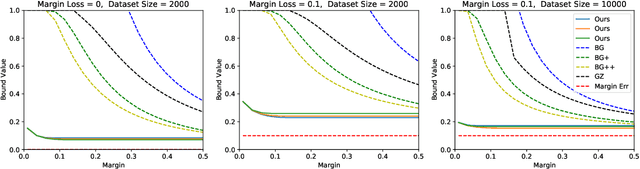
We study the generalisation properties of majority voting on finite ensembles of classifiers, proving margin-based generalisation bounds via the PAC-Bayes theory. These provide state-of-the-art guarantees on a number of classification tasks. Our central results leverage the Dirichlet posteriors studied recently by Zantedeschi et al. [2021] for training voting classifiers; in contrast to that work our bounds apply to non-randomised votes via the use of margins. Our contributions add perspective to the debate on the "margins theory" proposed by Schapire et al. [1998] for the generalisation of ensemble classifiers.
Non-Vacuous Generalisation Bounds for Shallow Neural Networks
Feb 04, 2022
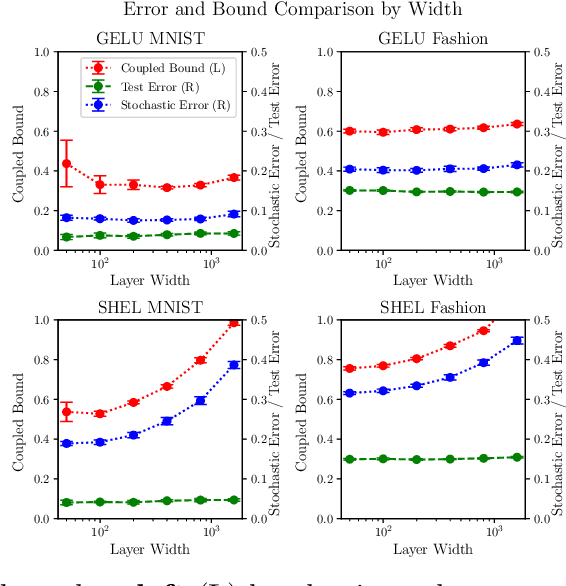


We focus on a specific class of shallow neural networks with a single hidden layer, namely those with $L_2$-normalised data and either a sigmoid-shaped Gaussian error function ("erf") activation or a Gaussian Error Linear Unit (GELU) activation. For these networks, we derive new generalisation bounds through the PAC-Bayesian theory; unlike most existing such bounds they apply to neural networks with deterministic rather than randomised parameters. Our bounds are empirically non-vacuous when the network is trained with vanilla stochastic gradient descent on MNIST and Fashion-MNIST.
On Margins and Derandomisation in PAC-Bayes
Jul 08, 2021

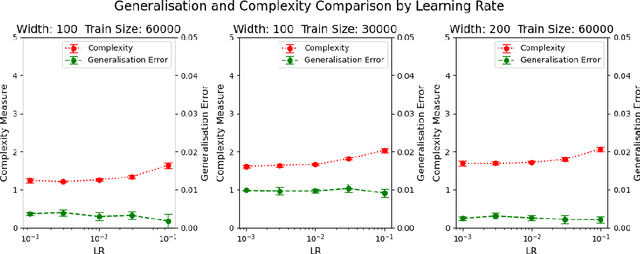

We develop a framework for derandomising PAC-Bayesian generalisation bounds achieving a margin on training data, relating this process to the concentration-of-measure phenomenon. We apply these tools to linear prediction, single-hidden-layer neural networks with an unusual erf activation function, and deep ReLU networks, obtaining new bounds. The approach is also extended to the idea of "partial-derandomisation" where only some layers are derandomised and the others are stochastic. This allows empirical evaluation of single-hidden-layer networks on more complex datasets, and helps bridge the gap between generalisation bounds for non-stochastic deep networks and those for randomised deep networks as generally examined in PAC-Bayes.
Differentiable PAC-Bayes Objectives with Partially Aggregated Neural Networks
Jun 22, 2020

We make three related contributions motivated by the challenge of training stochastic neural networks, particularly in a PAC-Bayesian setting: (1) we show how averaging over an ensemble of stochastic neural networks enables a new class of \emph{partially-aggregated} estimators; (2) we show that these lead to provably lower-variance gradient estimates for non-differentiable signed-output networks; (3) we reformulate a PAC-Bayesian bound for these networks to derive a directly optimisable, differentiable objective and a generalisation guarantee, without using a surrogate loss or loosening the bound. This bound is twice as tight as that of Letarte et al. (2019) on a similar network type. We show empirically that these innovations make training easier and lead to competitive guarantees.