Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Margins and Derandomisation in PAC-Bayes
Paper and Code
Jul 08, 2021

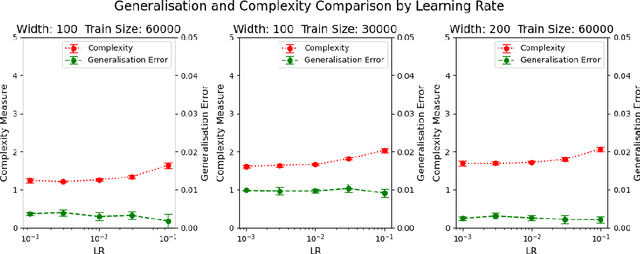

We develop a framework for derandomising PAC-Bayesian generalisation bounds achieving a margin on training data, relating this process to the concentration-of-measure phenomenon. We apply these tools to linear prediction, single-hidden-layer neural networks with an unusual erf activation function, and deep ReLU networks, obtaining new bounds. The approach is also extended to the idea of "partial-derandomisation" where only some layers are derandomised and the others are stochastic. This allows empirical evaluation of single-hidden-layer networks on more complex datasets, and helps bridge the gap between generalisation bounds for non-stochastic deep networks and those for randomised deep networks as generally examined in PAC-Bayes.
View paper on