 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombining Evaluation Metrics via the Unanimous Improvement Ratio and its Application to Clustering Tasks
Jan 18, 2014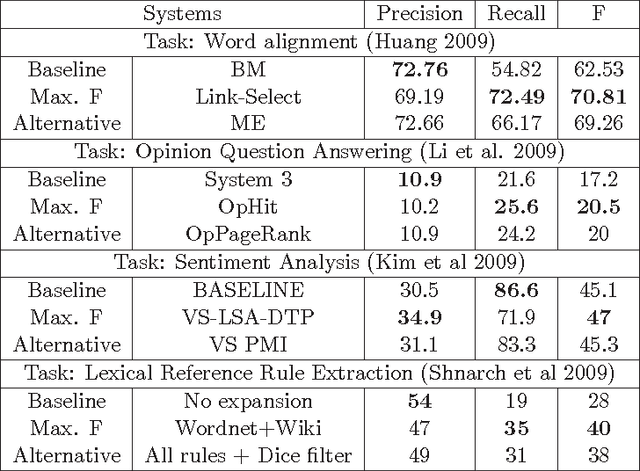
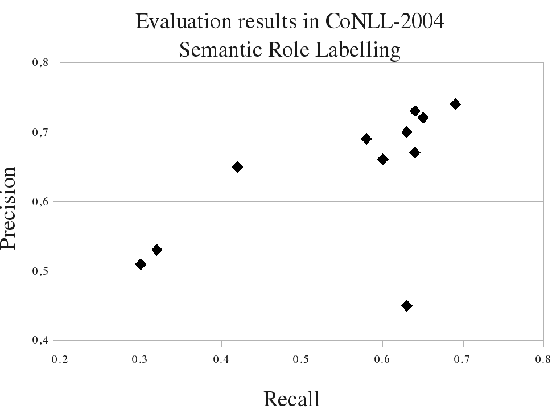
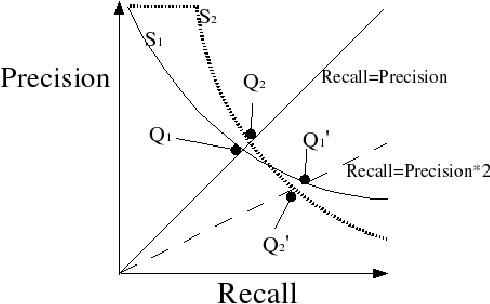
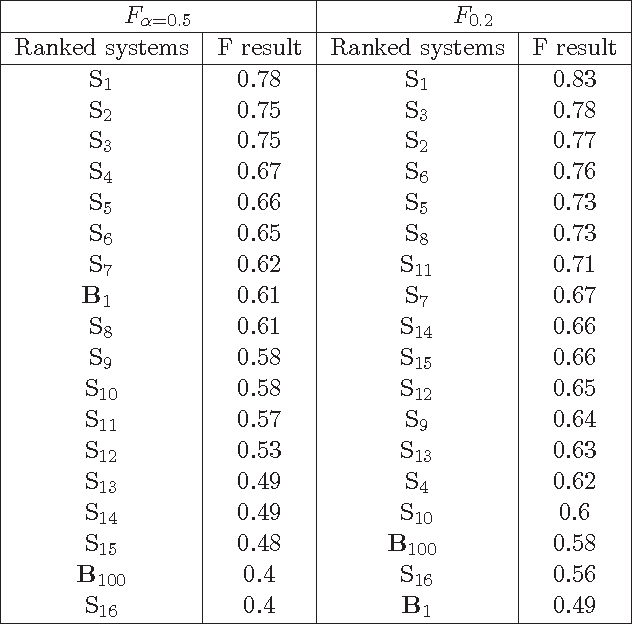
Many Artificial Intelligence tasks cannot be evaluated with a single quality criterion and some sort of weighted combination is needed to provide system rankings. A problem of weighted combination measures is that slight changes in the relative weights may produce substantial changes in the system rankings. This paper introduces the Unanimous Improvement Ratio (UIR), a measure that complements standard metric combination criteria (such as van Rijsbergen's F-measure) and indicates how robust the measured differences are to changes in the relative weights of the individual metrics. UIR is meant to elucidate whether a perceived difference between two systems is an artifact of how individual metrics are weighted. Besides discussing the theoretical foundations of UIR, this paper presents empirical results that confirm the validity and usefulness of the metric for the Text Clustering problem, where there is a tradeoff between precision and recall based metrics and results are particularly sensitive to the weighting scheme used to combine them. Remarkably, our experiments show that UIR can be used as a predictor of how well differences between systems measured on a given test bed will also hold in a different test bed.
The Uned systems at Senseval-2
Oct 28, 2009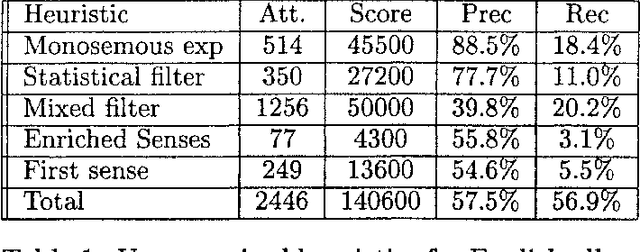

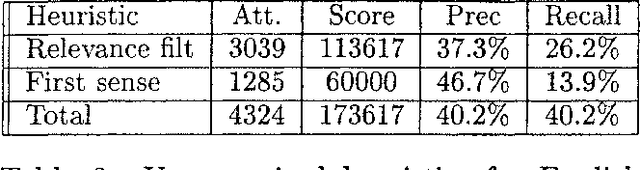
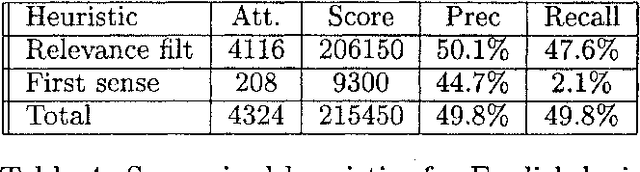
We have participated in the SENSEVAL-2 English tasks (all words and lexical sample) with an unsupervised system based on mutual information measured over a large corpus (277 million words) and some additional heuristics. A supervised extension of the system was also presented to the lexical sample task. Our system scored first among unsupervised systems in both tasks: 56.9% recall in all words, 40.2% in lexical sample. This is slightly worse than the first sense heuristic for all words and 3.6% better for the lexical sample, a strong indication that unsupervised Word Sense Disambiguation remains being a strong challenge.
* latex2e, 5 pages, appeared in SENSEVAL-2, held with ACL-02
The Role of Conceptual Relations in Word Sense Disambiguation
Jul 03, 2001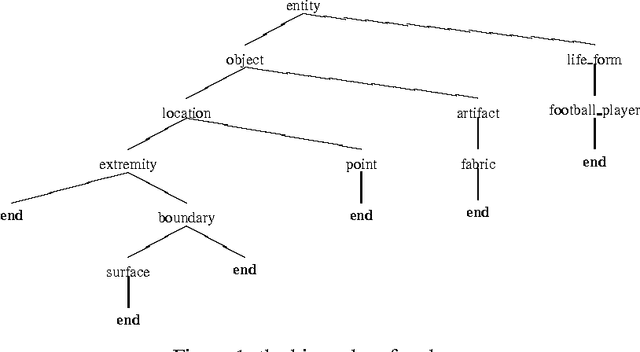


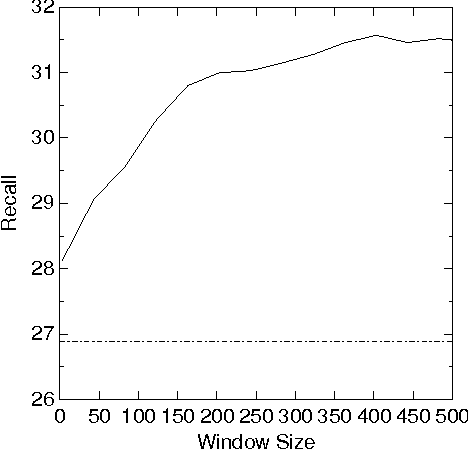
We explore many ways of using conceptual distance measures in Word Sense Disambiguation, starting with the Agirre-Rigau conceptual density measure. We use a generalized form of this measure, introducing many (parameterized) refinements and performing an exhaustive evaluation of all meaningful combinations. We finally obtain a 42% improvement over the original algorithm, and show that measures of conceptual distance are not worse indicators for sense disambiguation than measures based on word-coocurrence (exemplified by the Lesk algorithm). Our results, however, reinforce the idea that only a combination of different sources of knowledge might eventually lead to accurate word sense disambiguation.
Indexing with WordNet synsets can improve Text Retrieval
Aug 05, 1998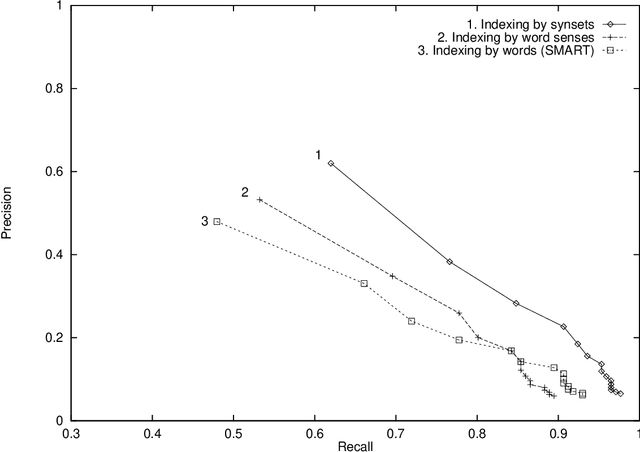
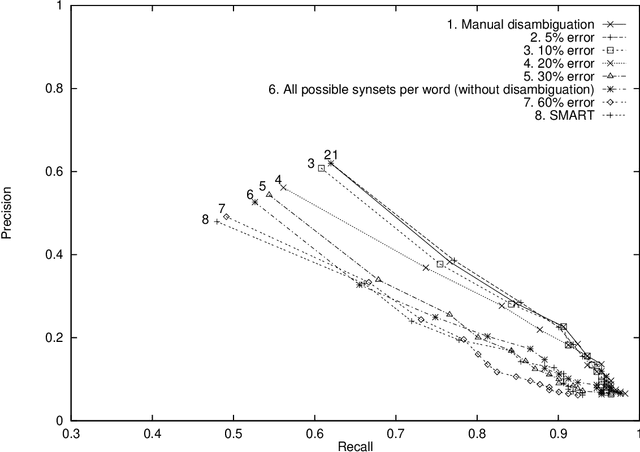
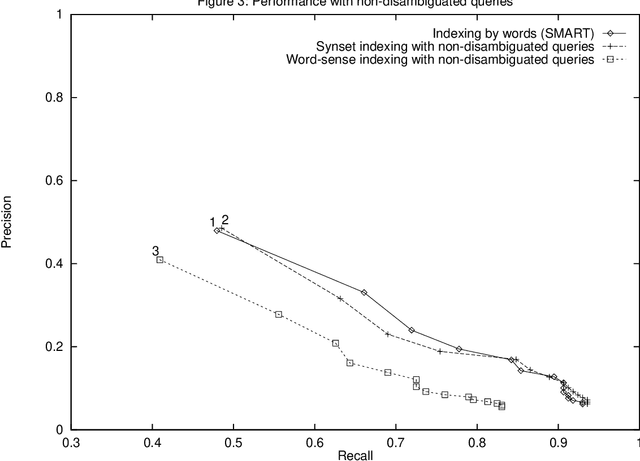
The classical, vector space model for text retrieval is shown to give better results (up to 29% better in our experiments) if WordNet synsets are chosen as the indexing space, instead of word forms. This result is obtained for a manually disambiguated test collection (of queries and documents) derived from the Semcor semantic concordance. The sensitivity of retrieval performance to (automatic) disambiguation errors when indexing documents is also measured. Finally, it is observed that if queries are not disambiguated, indexing by synsets performs (at best) only as good as standard word indexing.
* 7 pages, LaTeX2e, 3 eps figures, uses epsfig, colacl.sty