 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombining Evaluation Metrics via the Unanimous Improvement Ratio and its Application to Clustering Tasks
Paper and Code
Jan 18, 2014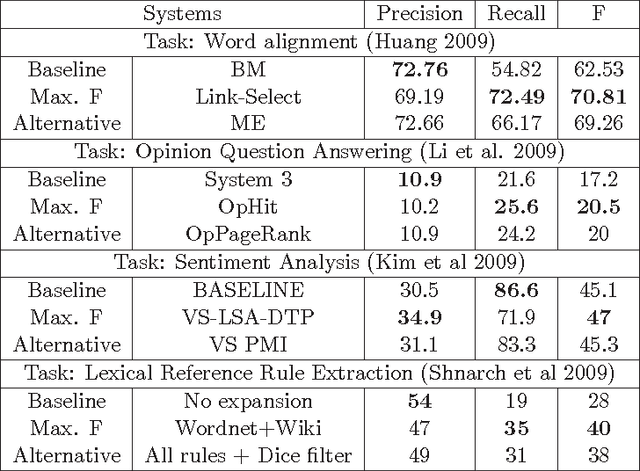
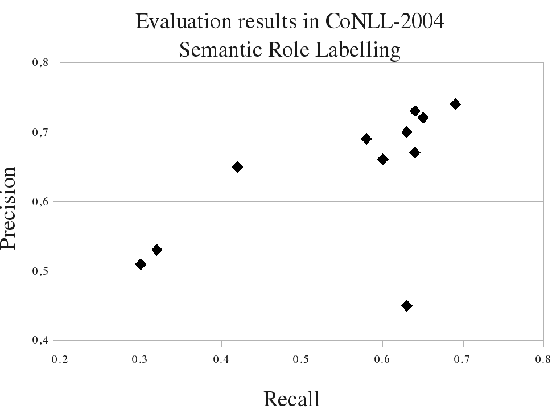
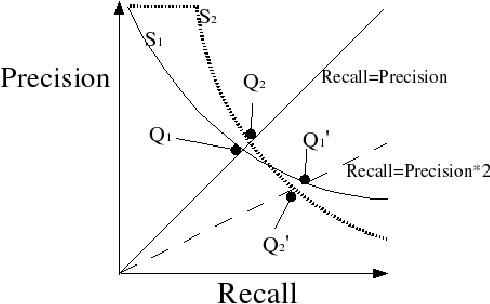
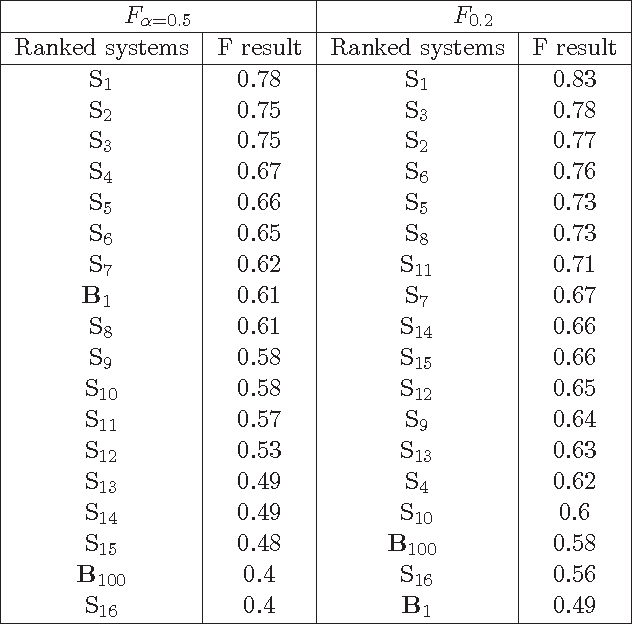
Many Artificial Intelligence tasks cannot be evaluated with a single quality criterion and some sort of weighted combination is needed to provide system rankings. A problem of weighted combination measures is that slight changes in the relative weights may produce substantial changes in the system rankings. This paper introduces the Unanimous Improvement Ratio (UIR), a measure that complements standard metric combination criteria (such as van Rijsbergen's F-measure) and indicates how robust the measured differences are to changes in the relative weights of the individual metrics. UIR is meant to elucidate whether a perceived difference between two systems is an artifact of how individual metrics are weighted. Besides discussing the theoretical foundations of UIR, this paper presents empirical results that confirm the validity and usefulness of the metric for the Text Clustering problem, where there is a tradeoff between precision and recall based metrics and results are particularly sensitive to the weighting scheme used to combine them. Remarkably, our experiments show that UIR can be used as a predictor of how well differences between systems measured on a given test bed will also hold in a different test bed.