 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Effectiveness Metric for Ordinal Classification: Formal Properties and Experimental Results
Jun 01, 2020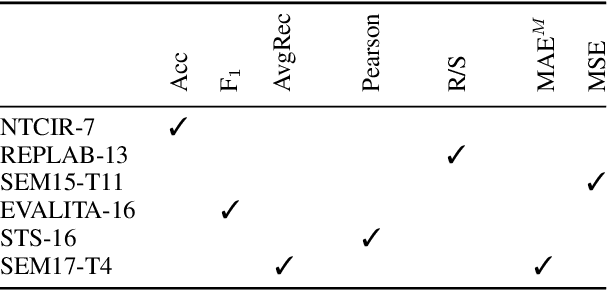

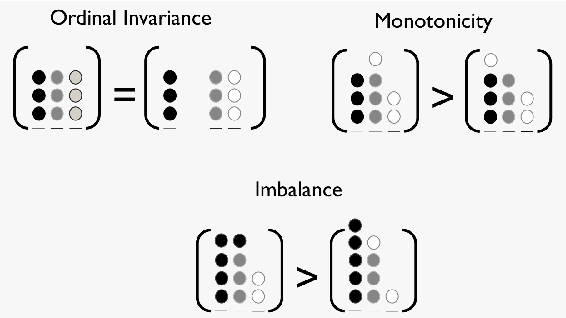
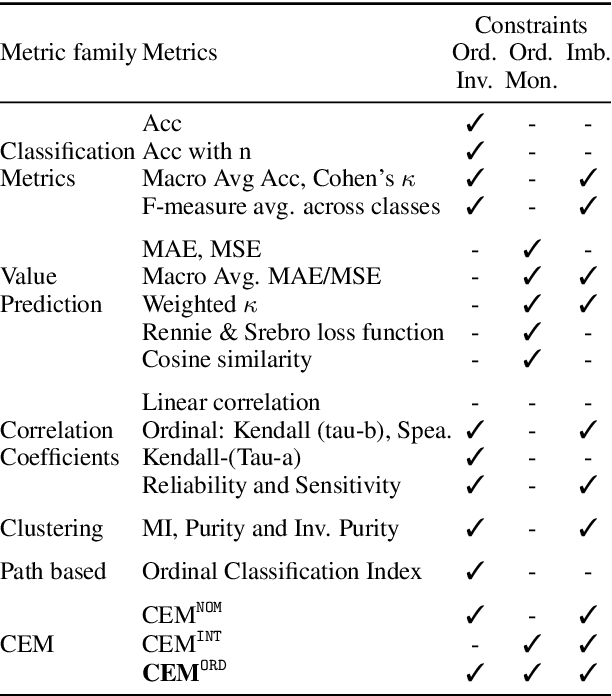
In Ordinal Classification tasks, items have to be assigned to classes that have a relative ordering, such as positive, neutral, negative in sentiment analysis. Remarkably, the most popular evaluation metrics for ordinal classification tasks either ignore relevant information (for instance, precision/recall on each of the classes ignores their relative ordering) or assume additional information (for instance, Mean Average Error assumes absolute distances between classes). In this paper we propose a new metric for Ordinal Classification, Closeness Evaluation Measure, that is rooted on Measurement Theory and Information Theory. Our theoretical analysis and experimental results over both synthetic data and data from NLP shared tasks indicate that the proposed metric captures quality aspects from different traditional tasks simultaneously. In addition, it generalizes some popular classification (nominal scale) and error minimization (interval scale) metrics, depending on the measurement scale in which it is instantiated.
Combining Evaluation Metrics via the Unanimous Improvement Ratio and its Application to Clustering Tasks
Jan 18, 2014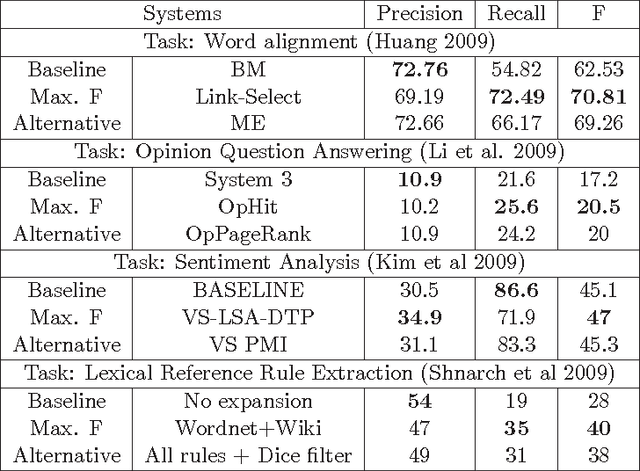
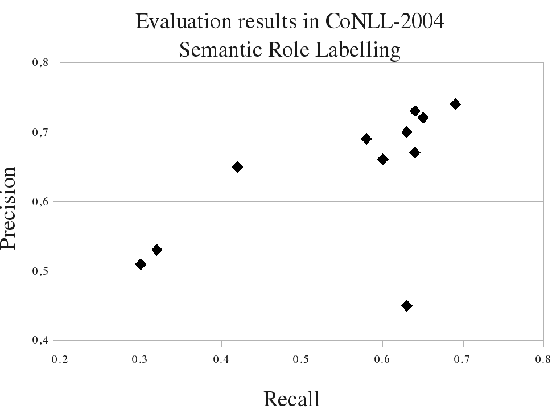
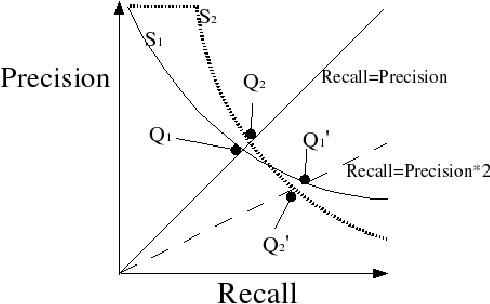
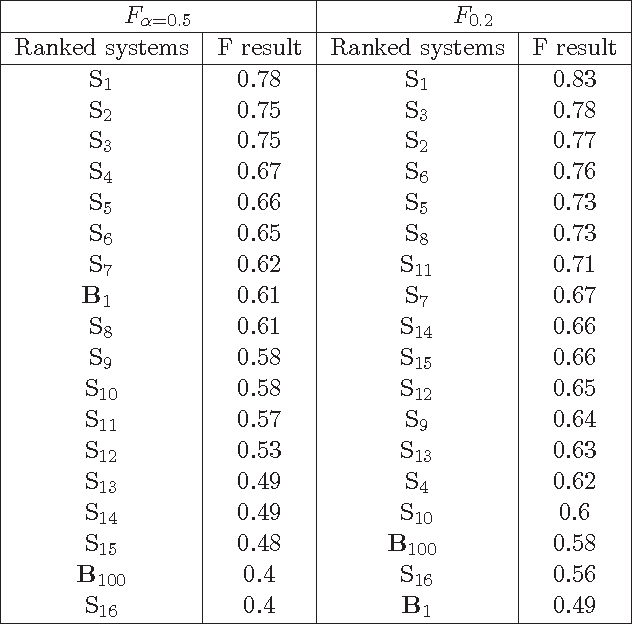
Many Artificial Intelligence tasks cannot be evaluated with a single quality criterion and some sort of weighted combination is needed to provide system rankings. A problem of weighted combination measures is that slight changes in the relative weights may produce substantial changes in the system rankings. This paper introduces the Unanimous Improvement Ratio (UIR), a measure that complements standard metric combination criteria (such as van Rijsbergen's F-measure) and indicates how robust the measured differences are to changes in the relative weights of the individual metrics. UIR is meant to elucidate whether a perceived difference between two systems is an artifact of how individual metrics are weighted. Besides discussing the theoretical foundations of UIR, this paper presents empirical results that confirm the validity and usefulness of the metric for the Text Clustering problem, where there is a tradeoff between precision and recall based metrics and results are particularly sensitive to the weighting scheme used to combine them. Remarkably, our experiments show that UIR can be used as a predictor of how well differences between systems measured on a given test bed will also hold in a different test bed.
Towards Real-Time Summarization of Scheduled Events from Twitter Streams
Apr 17, 2012

This paper explores the real-time summarization of scheduled events such as soccer games from torrential flows of Twitter streams. We propose and evaluate an approach that substantially shrinks the stream of tweets in real-time, and consists of two steps: (i) sub-event detection, which determines if something new has occurred, and (ii) tweet selection, which picks a representative tweet to describe each sub-event. We compare the summaries generated in three languages for all the soccer games in "Copa America 2011" to reference live reports offered by Yahoo! Sports journalists. We show that simple text analysis methods which do not involve external knowledge lead to summaries that cover 84% of the sub-events on average, and 100% of key types of sub-events (such as goals in soccer). Our approach should be straightforwardly applicable to other kinds of scheduled events such as other sports, award ceremonies, keynote talks, TV shows, etc.