Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndexing with WordNet synsets can improve Text Retrieval
Paper and Code
Aug 05, 1998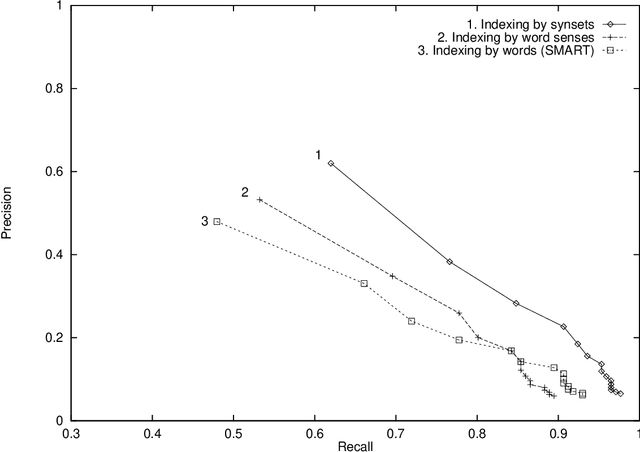
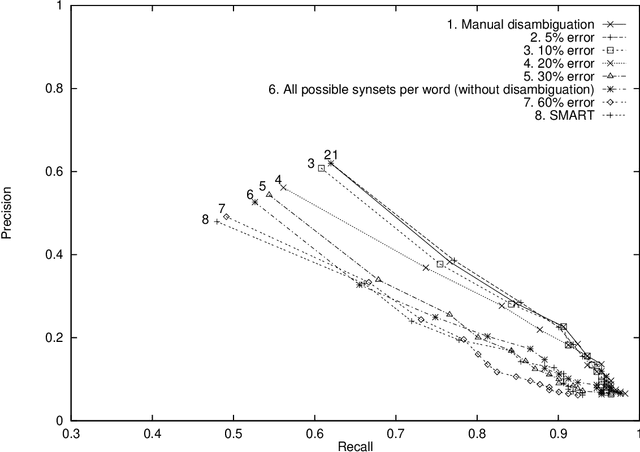
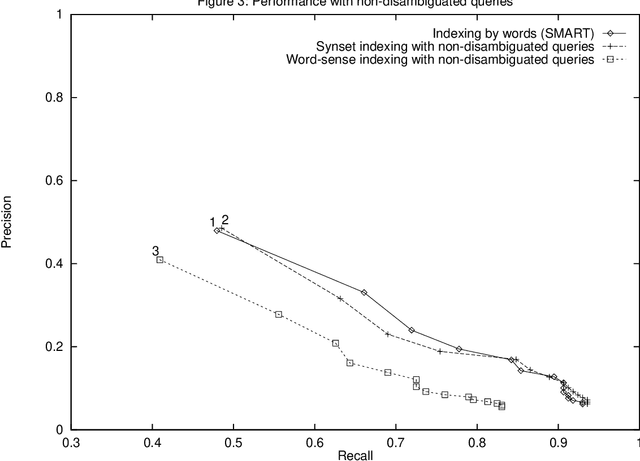
The classical, vector space model for text retrieval is shown to give better results (up to 29% better in our experiments) if WordNet synsets are chosen as the indexing space, instead of word forms. This result is obtained for a manually disambiguated test collection (of queries and documents) derived from the Semcor semantic concordance. The sensitivity of retrieval performance to (automatic) disambiguation errors when indexing documents is also measured. Finally, it is observed that if queries are not disambiguated, indexing by synsets performs (at best) only as good as standard word indexing.
* Proceedings of the COLING/ACL'98 Workshop on Usage of WordNet for
NLP, Montreal, 1998 * 7 pages, LaTeX2e, 3 eps figures, uses epsfig, colacl.sty
View paper on