 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWord Sense Disambiguation Using English-Spanish Aligned Phrases over Comparable Corpora
Oct 29, 2009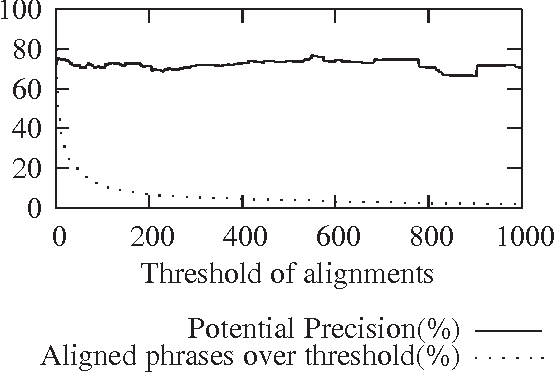
In this paper we describe a WSD experiment based on bilingual English-Spanish comparable corpora in which individual noun phrases have been identified and aligned with their respective counterparts in the other language. The evaluation of the experiment has been carried out against SemCor. We show that, with the alignment algorithm employed, potential precision is high (74.3%), however the coverage of the method is low (2.7%), due to alignments being far less frequent than we expected. Contrary to our intuition, precision does not rise consistently with the number of alignments. The coverage is low due to several factors; there are important domain differences, and English and Spanish are too close languages for this approach to be able to discriminate efficiently between senses, rendering it unsuitable for WSD, although the method may prove more productive in machine translation.
Word Sense Disambiguation Based on Mutual Information and Syntactic Patterns
Oct 28, 2009



This paper describes a hybrid system for WSD, presented to the English all-words and lexical-sample tasks, that relies on two different unsupervised approaches. The first one selects the senses according to mutual information proximity between a context word a variant of the sense. The second heuristic analyzes the examples of use in the glosses of the senses so that simple syntactic patterns are inferred. This patterns are matched against the disambiguation contexts. We show that the first heuristic obtains a precision and recall of .58 and .35 respectively in the all words task while the second obtains .80 and .25. The high precision obtained recommends deeper research of the techniques. Results for the lexical sample task are also provided.
* latex2e, 5 pages, appeared in SENSEVAL-3, Barcelona 2004
The Uned systems at Senseval-2
Oct 28, 2009

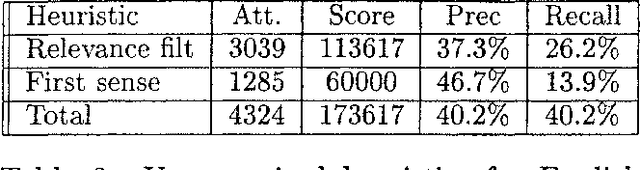
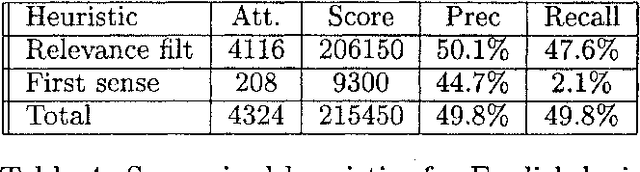
We have participated in the SENSEVAL-2 English tasks (all words and lexical sample) with an unsupervised system based on mutual information measured over a large corpus (277 million words) and some additional heuristics. A supervised extension of the system was also presented to the lexical sample task. Our system scored first among unsupervised systems in both tasks: 56.9% recall in all words, 40.2% in lexical sample. This is slightly worse than the first sense heuristic for all words and 3.6% better for the lexical sample, a strong indication that unsupervised Word Sense Disambiguation remains being a strong challenge.
* latex2e, 5 pages, appeared in SENSEVAL-2, held with ACL-02
The Role of Conceptual Relations in Word Sense Disambiguation
Jul 03, 2001


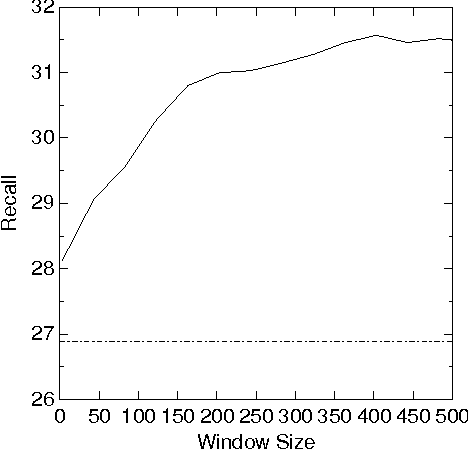
We explore many ways of using conceptual distance measures in Word Sense Disambiguation, starting with the Agirre-Rigau conceptual density measure. We use a generalized form of this measure, introducing many (parameterized) refinements and performing an exhaustive evaluation of all meaningful combinations. We finally obtain a 42% improvement over the original algorithm, and show that measures of conceptual distance are not worse indicators for sense disambiguation than measures based on word-coocurrence (exemplified by the Lesk algorithm). Our results, however, reinforce the idea that only a combination of different sources of knowledge might eventually lead to accurate word sense disambiguation.