 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWord Sense Disambiguation Using English-Spanish Aligned Phrases over Comparable Corpora
Paper and Code
Oct 29, 2009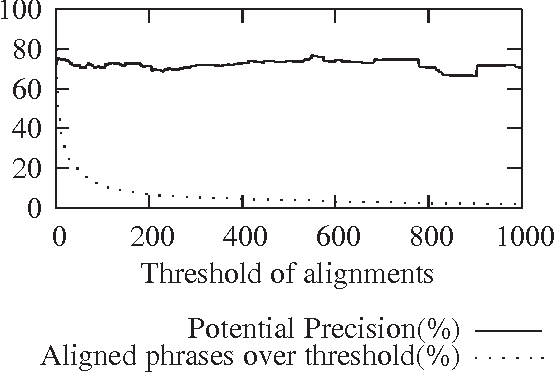
In this paper we describe a WSD experiment based on bilingual English-Spanish comparable corpora in which individual noun phrases have been identified and aligned with their respective counterparts in the other language. The evaluation of the experiment has been carried out against SemCor. We show that, with the alignment algorithm employed, potential precision is high (74.3%), however the coverage of the method is low (2.7%), due to alignments being far less frequent than we expected. Contrary to our intuition, precision does not rise consistently with the number of alignments. The coverage is low due to several factors; there are important domain differences, and English and Spanish are too close languages for this approach to be able to discriminate efficiently between senses, rendering it unsuitable for WSD, although the method may prove more productive in machine translation.