 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Breath Phase and Continuous Adventitious Sound Detection in Lung and Tracheal Sound Using Mixed Set Training and Domain Adaptation
Jul 09, 2021

Previously, we established a lung sound database, HF_Lung_V2 and proposed convolutional bidirectional gated recurrent unit (CNN-BiGRU) models with adequate ability for inhalation, exhalation, continuous adventitious sound (CAS), and discontinuous adventitious sound detection in the lung sound. In this study, we proceeded to build a tracheal sound database, HF_Tracheal_V1, containing 11107 of 15-second tracheal sound recordings, 23087 inhalation labels, 16728 exhalation labels, and 6874 CAS labels. The tracheal sound in HF_Tracheal_V1 and the lung sound in HF_Lung_V2 were either combined or used alone to train the CNN-BiGRU models for respective lung and tracheal sound analysis. Different training strategies were investigated and compared: (1) using full training (training from scratch) to train the lung sound models using lung sound alone and train the tracheal sound models using tracheal sound alone, (2) using a mixed set that contains both the lung and tracheal sound to train the models, and (3) using domain adaptation that finetuned the pre-trained lung sound models with the tracheal sound data and vice versa. Results showed that the models trained only by lung sound performed poorly in the tracheal sound analysis and vice versa. However, the mixed set training and domain adaptation can improve the performance of exhalation and CAS detection in the lung sound, and inhalation, exhalation, and CAS detection in the tracheal sound compared to positive controls (lung models trained only by lung sound and vice versa). Especially, a model derived from the mixed set training prevails in the situation of killing two birds with one stone.
Multi-path Convolutional Neural Networks Efficiently Improve Feature Extraction in Continuous Adventitious Lung Sound Detection
Jul 09, 2021


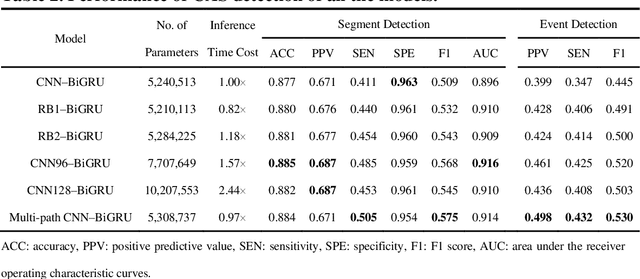
We previously established a large lung sound database, HF_Lung_V2 (Lung_V2). We trained convolutional-bidirectional gated recurrent unit (CNN-BiGRU) networks for detecting inhalation, exhalation, continuous adventitious sound (CAS) and discontinuous adventitious sound at the recording level on the basis of Lung_V2. However, the performance of CAS detection was poor due to many reasons, one of which is the highly diversified CAS patterns. To make the original CNN-BiGRU model learn the CAS patterns more effectively and not cause too much computing burden, three strategies involving minimal modifications of the network architecture of the CNN layers were investigated: (1) making the CNN layers a bit deeper by using the residual blocks, (2) making the CNN layers a bit wider by increasing the number of CNN kernels, and (3) separating the feature input into multiple paths (the model was denoted by Multi-path CNN-BiGRU). The performance of CAS segment and event detection were evaluated. Results showed that improvement in CAS detection was observed among all the proposed architecture-modified models. The F1 score for CAS event detection of the proposed models increased from 0.445 to 0.491-0.530, which was deemed significant. However, the Multi-path CNN-BiGRU model outperformed the other models in terms of the number of winning titles (five) in total nine evaluation metrics. In addition, the Multi-path CNN-BiGRU model did not cause extra computing burden (0.97-fold inference time) compared to the original CNN-BiGRU model. Conclusively, the Multi-path CNN layers can efficiently improve the effectiveness of feature extraction and subsequently result in better CAS detection.
Benchmarking of eight recurrent neural network variants for breath phase and adventitious sound detection on a self-developed open-access lung sound database-HF_Lung_V1
Mar 03, 2021


A reliable, remote, and continuous real-time respiratory sound monitor with automated respiratory sound analysis ability is urgently required in many clinical scenarios-such as in monitoring disease progression of coronavirus disease 2019-to replace conventional auscultation with a handheld stethoscope. However, a robust computerized respiratory sound analysis algorithm has not yet been validated in practical applications. In this study, we developed a lung sound database (HF_Lung_V1) comprising 9,765 audio files of lung sounds (duration of 15 s each), 34,095 inhalation labels, 18,349 exhalation labels, 13,883 continuous adventitious sound (CAS) labels (comprising 8,457 wheeze labels, 686 stridor labels, and 4,740 rhonchi labels), and 15,606 discontinuous adventitious sound labels (all crackles). We conducted benchmark tests for long short-term memory (LSTM), gated recurrent unit (GRU), bidirectional LSTM (BiLSTM), bidirectional GRU (BiGRU), convolutional neural network (CNN)-LSTM, CNN-GRU, CNN-BiLSTM, and CNN-BiGRU models for breath phase detection and adventitious sound detection. We also conducted a performance comparison between the LSTM-based and GRU-based models, between unidirectional and bidirectional models, and between models with and without a CNN. The results revealed that these models exhibited adequate performance in lung sound analysis. The GRU-based models outperformed, in terms of F1 scores and areas under the receiver operating characteristic curves, the LSTM-based models in most of the defined tasks. Furthermore, all bidirectional models outperformed their unidirectional counterparts. Finally, the addition of a CNN improved the accuracy of lung sound analysis, especially in the CAS detection tasks.
An Update of a Progressively Expanded Database for Automated Lung Sound Analysis
Feb 08, 2021

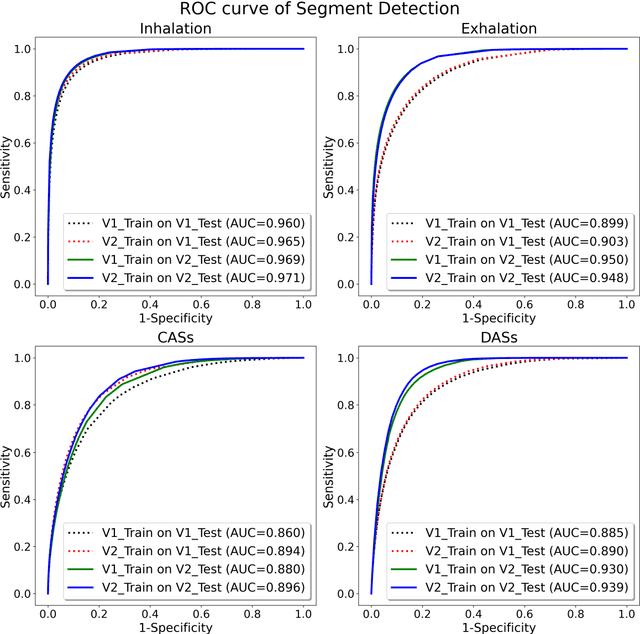
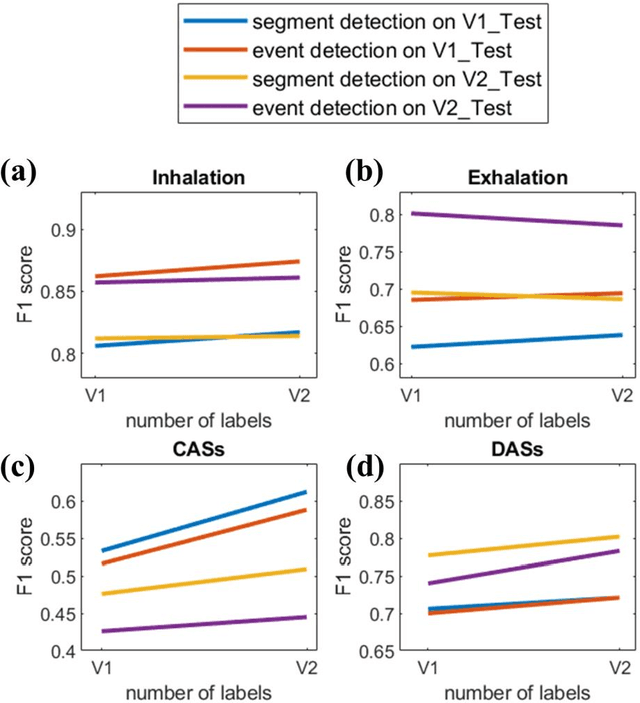
A continuous real-time respiratory sound automated analysis system is needed in clinical practice. Previously, we established an open access lung sound database, HF_Lung_V1, and automated lung sound analysis algorithms capable of detecting inhalation, exhalation, continuous adventitious sounds (CASs) and discontinuous adventitious sounds (DASs). In this study, HF-Lung-V1 has been further expanded to HF-Lung-V2 with 1.45 times of increase in audio files. The convolutional neural network (CNN)-bidirectional gated recurrent unit (BiGRU) model was separately trained with training datasets of HF_Lung_V1 (V1_Train) and HF_Lung_V2 (V2_Train), and then were used for the performance comparisons of segment detection and event detection on both test datasets of HF_Lung_V1 (V1_Test) and HF_Lung_V2 (V2_Test). The performance of segment detection was measured by accuracy, predictive positive value (PPV), sensitivity, specificity, F1 score, receiver operating characteristic (ROC) curve and area under the curve (AUC), whereas that of event detection was evaluated with PPV, sensitivity, and F1 score. Results indicate that the model performance trained by V2_Train showed improvement on both V1_Test and V2_Test in inhalation, CASs and DASs, particularly in CASs, as well as on V1_Test in exhalation.
Development of a Respiratory Sound Labeling Software for Training a Deep Learning-Based Respiratory Sound Analysis Model
Jan 05, 2021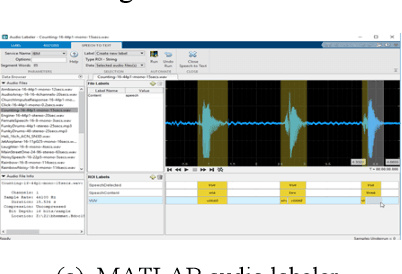
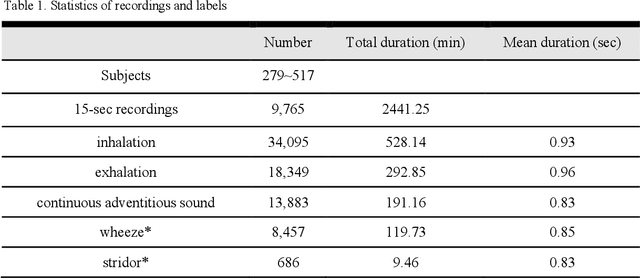
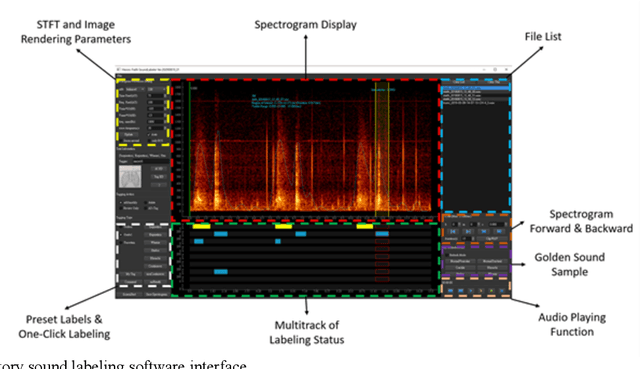

Respiratory auscultation can help healthcare professionals detect abnormal respiratory conditions if adventitious lung sounds are heard. The state-of-the-art artificial intelligence technologies based on deep learning show great potential in the development of automated respiratory sound analysis. To train a deep learning-based model, a huge number of accurate labels of normal breath sounds and adventitious sounds are needed. In this paper, we demonstrate the work of developing a respiratory sound labeling software to help annotators identify and label the inhalation, exhalation, and adventitious respiratory sound more accurately and quickly. Our labeling software integrates six features from MATLAB Audio Labeler, and one commercial audio editor, RX7. As of October, 2019, we have labeled 9,765 15-second-long audio files of breathing lung sounds, and accrued 34,095 inhalation labels,18,349 exhalation labels, 13,883 continuous adventitious sounds (CASs) labels and 15,606 discontinuous adventitious sounds (DASs) labels, which are significantly larger than previously published studies. The trained convolutional recurrent neural networks based on these labels showed good performance with F1-scores of 86.0% on inhalation event detection, 51.6% on CASs event detection and 71.4% on DASs event detection. In conclusion, our results show that our proposed respiratory sound labeling software could easily pre-define a label, perform one-click labeling, and overall facilitate the process of accurately labeling. This software helps develop deep learning-based models that require a huge amount of labeled acoustic data.
Deep Learning Based Segmentation of Various Brain Lesions for Radiosurgery
Jul 22, 2020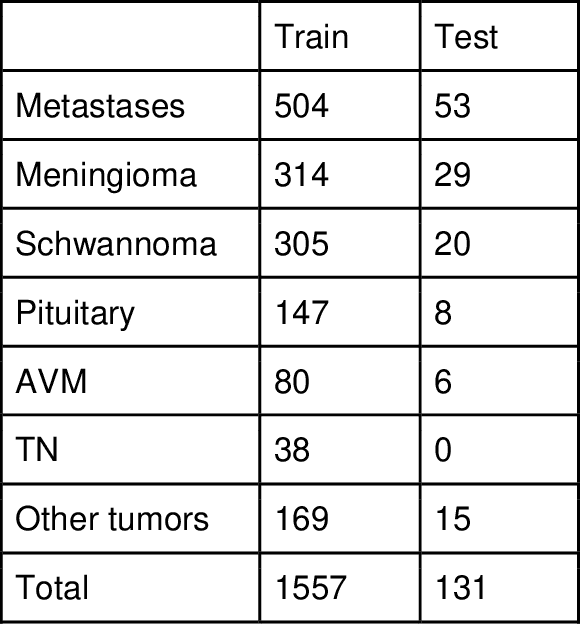
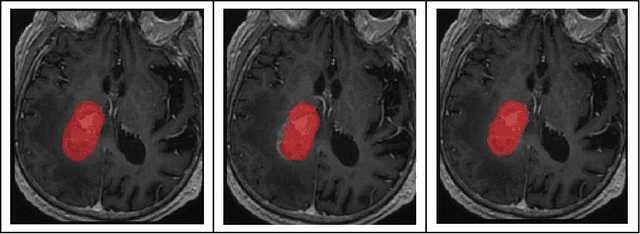
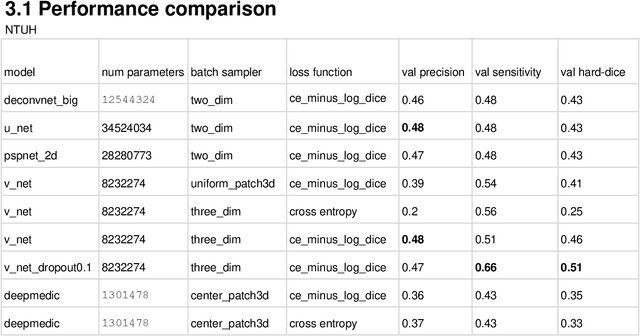
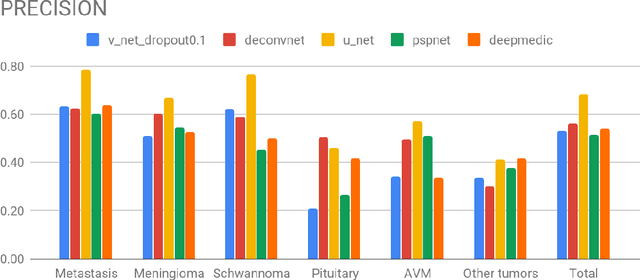
Semantic segmentation of medical images with deep learning models is rapidly developed. In this study, we benchmarked state-of-the-art deep learning segmentation algorithms on our clinical stereotactic radiosurgery dataset, demonstrating the strengths and weaknesses of these algorithms in a fairly practical scenario. In particular, we compared the model performances with respect to their sampling method, model architecture, and the choice of loss functions, identifying the suitable settings for their applications and shedding light on the possible improvements.