 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Learning for Segmentation and Quantification of Dopamine Neurons in $\text{Parkinson's Disease}$
Jan 11, 2023$\text{Parkinson's Disease}$ (PD) is the second most common neurodegenerative disease in humans. PD is characterized by the gradual loss of dopaminergic neurons in the Substantia Nigra (a part of the mid-brain). Counting the number of dopaminergic neurons in the Substantia Nigra is one of the most important indexes in evaluating drug efficacy in PD animal models. Currently, analyzing and quantifying dopaminergic neurons is conducted manually by experts through analysis of digital pathology images which is laborious, time-consuming, and highly subjective. As such, a reliable and unbiased automated system is demanded for the quantification of dopaminergic neurons in digital pathology images. We propose an end-to-end deep learning framework for the segmentation and quantification of dopaminergic neurons in PD animal models. To the best of knowledge, this is the first machine learning model that detects the cell body of dopaminergic neurons, counts the number of dopaminergic neurons and provides the phenotypic characteristics of individual dopaminergic neurons as a numerical output. Extensive experiments demonstrate the effectiveness of our model in quantifying neurons with a high precision, which can provide quicker turnaround for drug efficacy studies, better understanding of dopaminergic neuronal health status and unbiased results in PD pre-clinical research.
DiRA: Discriminative, Restorative, and Adversarial Learning for Self-supervised Medical Image Analysis
Apr 21, 2022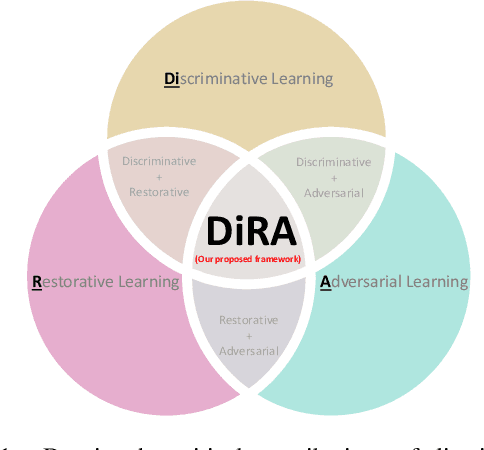

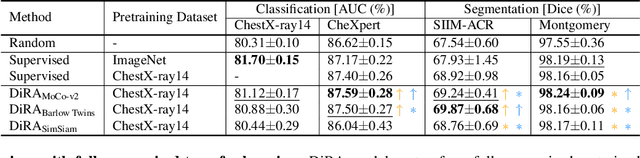
Discriminative learning, restorative learning, and adversarial learning have proven beneficial for self-supervised learning schemes in computer vision and medical imaging. Existing efforts, however, omit their synergistic effects on each other in a ternary setup, which, we envision, can significantly benefit deep semantic representation learning. To realize this vision, we have developed DiRA, the first framework that unites discriminative, restorative, and adversarial learning in a unified manner to collaboratively glean complementary visual information from unlabeled medical images for fine-grained semantic representation learning. Our extensive experiments demonstrate that DiRA (1) encourages collaborative learning among three learning ingredients, resulting in more generalizable representation across organs, diseases, and modalities; (2) outperforms fully supervised ImageNet models and increases robustness in small data regimes, reducing annotation cost across multiple medical imaging applications; (3) learns fine-grained semantic representation, facilitating accurate lesion localization with only image-level annotation; and (4) enhances state-of-the-art restorative approaches, revealing that DiRA is a general mechanism for united representation learning. All code and pre-trained models are available at https: //github.com/JLiangLab/DiRA.
CAiD: Context-Aware Instance Discrimination for Self-supervised Learning in Medical Imaging
Apr 15, 2022
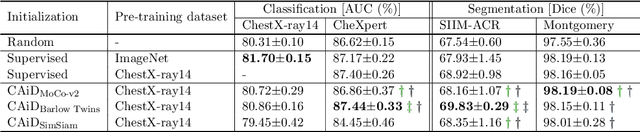
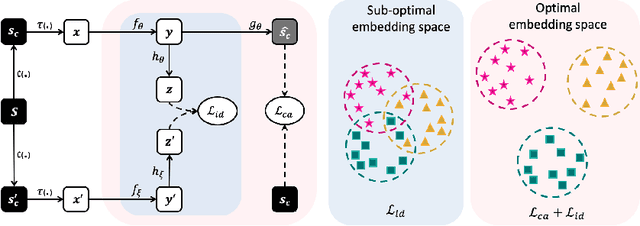

Recently, self-supervised instance discrimination methods have achieved significant success in learning visual representations from unlabeled photographic images. However, given the marked differences between photographic and medical images, the efficacy of instance-based objectives, focusing on learning the most discriminative global features in the image (i.e., wheels in bicycle), remains unknown in medical imaging. Our preliminary analysis showed that high global similarity of medical images in terms of anatomy hampers instance discrimination methods for capturing a set of distinct features, negatively impacting their performance on medical downstream tasks. To alleviate this limitation, we have developed a simple yet effective self-supervised framework, called Context-Aware instance Discrimination (CAiD). CAiD aims to improve instance discrimination learning by providing finer and more discriminative information encoded from a diverse local context of unlabeled medical images. We conduct a systematic analysis to investigate the utility of the learned features from a three-pronged perspective: (i) generalizability and transferability, (ii) separability in the embedding space, and (iii) reusability. Our extensive experiments demonstrate that CAiD (1) enriches representations learned from existing instance discrimination methods; (2) delivers more discriminative features by adequately capturing finer contextual information from individual medial images; and (3) improves reusability of low/mid-level features compared to standard instance discriminative methods. As open science, all codes and pre-trained models are available on our GitHub page: https://github.com/JLiangLab/CAiD.
A Systematic Benchmarking Analysis of Transfer Learning for Medical Image Analysis
Aug 12, 2021
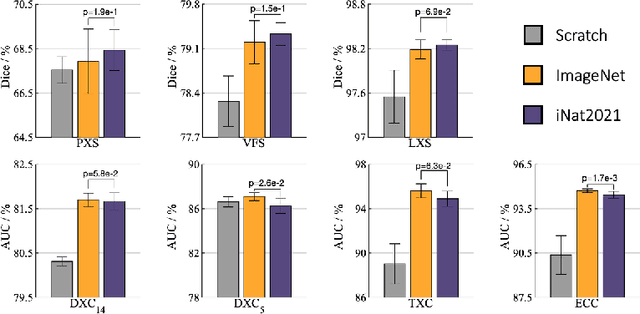
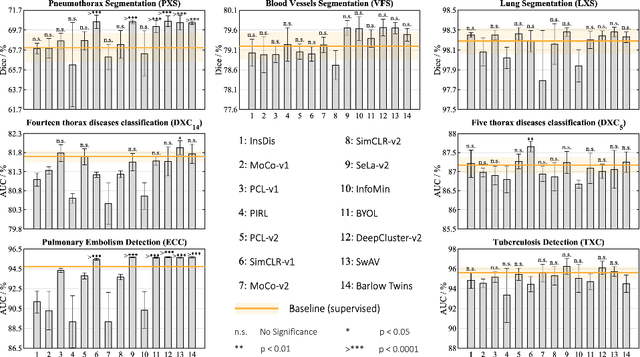
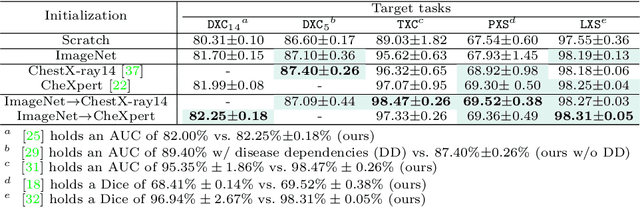
Transfer learning from supervised ImageNet models has been frequently used in medical image analysis. Yet, no large-scale evaluation has been conducted to benchmark the efficacy of newly-developed pre-training techniques for medical image analysis, leaving several important questions unanswered. As the first step in this direction, we conduct a systematic study on the transferability of models pre-trained on iNat2021, the most recent large-scale fine-grained dataset, and 14 top self-supervised ImageNet models on 7 diverse medical tasks in comparison with the supervised ImageNet model. Furthermore, we present a practical approach to bridge the domain gap between natural and medical images by continually (pre-)training supervised ImageNet models on medical images. Our comprehensive evaluation yields new insights: (1) pre-trained models on fine-grained data yield distinctive local representations that are more suitable for medical segmentation tasks, (2) self-supervised ImageNet models learn holistic features more effectively than supervised ImageNet models, and (3) continual pre-training can bridge the domain gap between natural and medical images. We hope that this large-scale open evaluation of transfer learning can direct the future research of deep learning for medical imaging. As open science, all codes and pre-trained models are available on our GitHub page https://github.com/JLiangLab/BenchmarkTransferLearning.
Transferable Visual Words: Exploiting the Semantics of Anatomical Patterns for Self-supervised Learning
Feb 21, 2021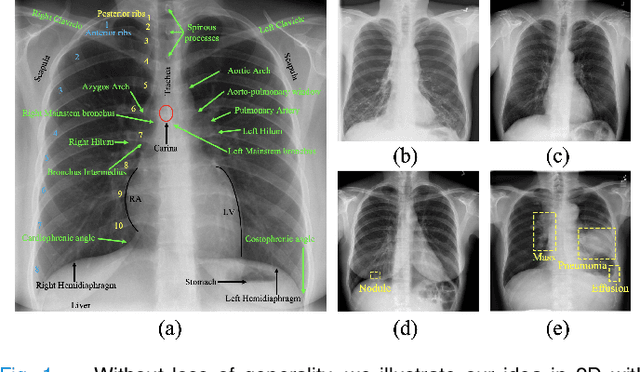
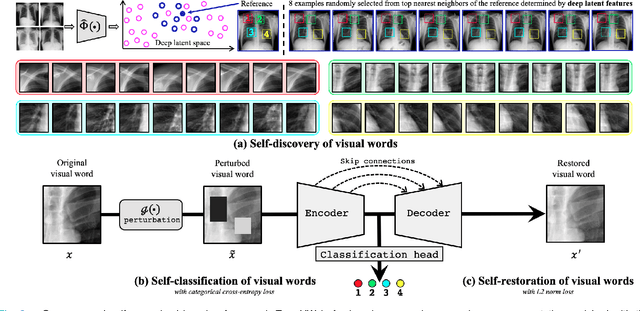
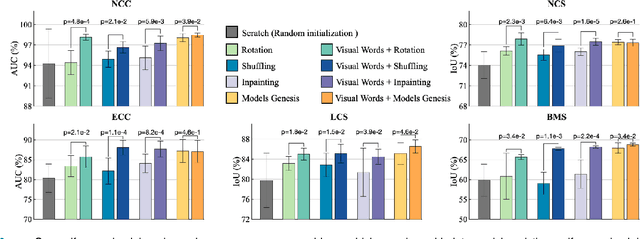

This paper introduces a new concept called "transferable visual words" (TransVW), aiming to achieve annotation efficiency for deep learning in medical image analysis. Medical imaging--focusing on particular parts of the body for defined clinical purposes--generates images of great similarity in anatomy across patients and yields sophisticated anatomical patterns across images, which are associated with rich semantics about human anatomy and which are natural visual words. We show that these visual words can be automatically harvested according to anatomical consistency via self-discovery, and that the self-discovered visual words can serve as strong yet free supervision signals for deep models to learn semantics-enriched generic image representation via self-supervision (self-classification and self-restoration). Our extensive experiments demonstrate the annotation efficiency of TransVW by offering higher performance and faster convergence with reduced annotation cost in several applications. Our TransVW has several important advantages, including (1) TransVW is a fully autodidactic scheme, which exploits the semantics of visual words for self-supervised learning, requiring no expert annotation; (2) visual word learning is an add-on strategy, which complements existing self-supervised methods, boosting their performance; and (3) the learned image representation is semantics-enriched models, which have proven to be more robust and generalizable, saving annotation efforts for a variety of applications through transfer learning. Our code, pre-trained models, and curated visual words are available at https://github.com/JLiangLab/TransVW.
Learning Semantics-enriched Representation via Self-discovery, Self-classification, and Self-restoration
Jul 14, 2020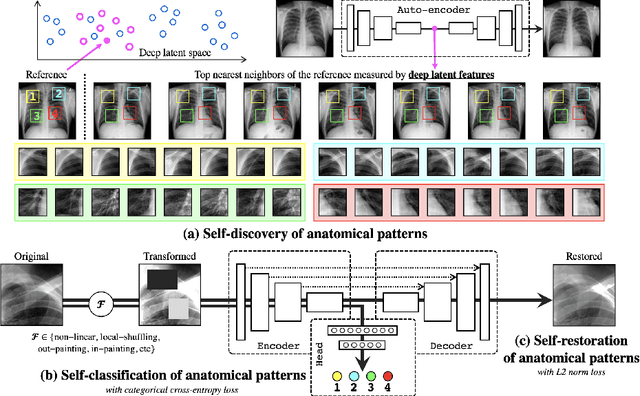
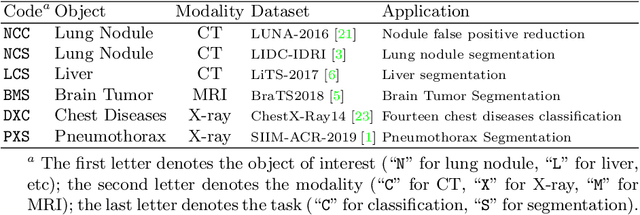

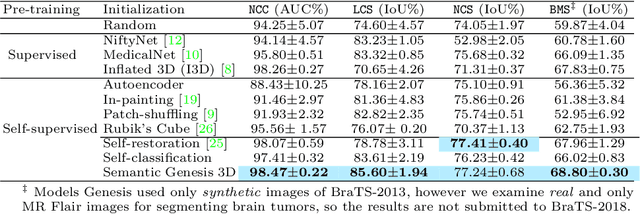
Medical images are naturally associated with rich semantics about the human anatomy, reflected in an abundance of recurring anatomical patterns, offering unique potential to foster deep semantic representation learning and yield semantically more powerful models for different medical applications. But how exactly such strong yet free semantics embedded in medical images can be harnessed for self-supervised learning remains largely unexplored. To this end, we train deep models to learn semantically enriched visual representation by self-discovery, self-classification, and self-restoration of the anatomy underneath medical images, resulting in a semantics-enriched, general-purpose, pre-trained 3D model, named Semantic Genesis. We examine our Semantic Genesis with all the publicly-available pre-trained models, by either self-supervision or fully supervision, on the six distinct target tasks, covering both classification and segmentation in various medical modalities (i.e.,CT, MRI, and X-ray). Our extensive experiments demonstrate that Semantic Genesis significantly exceeds all of its 3D counterparts as well as the de facto ImageNet-based transfer learning in 2D. This performance is attributed to our novel self-supervised learning framework, encouraging deep models to learn compelling semantic representation from abundant anatomical patterns resulting from consistent anatomies embedded in medical images. Code and pre-trained Semantic Genesis are available at https://github.com/JLiangLab/SemanticGenesis .