 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransferable Visual Words: Exploiting the Semantics of Anatomical Patterns for Self-supervised Learning
Paper and Code
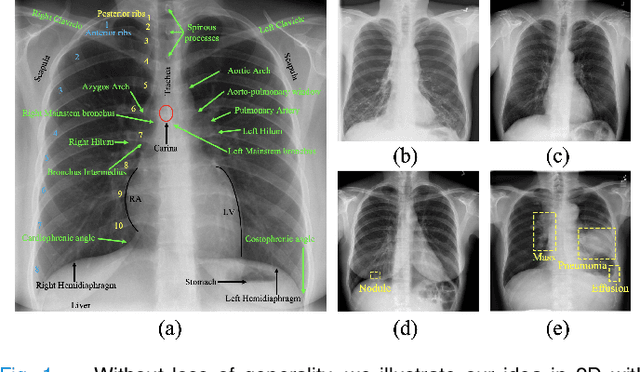
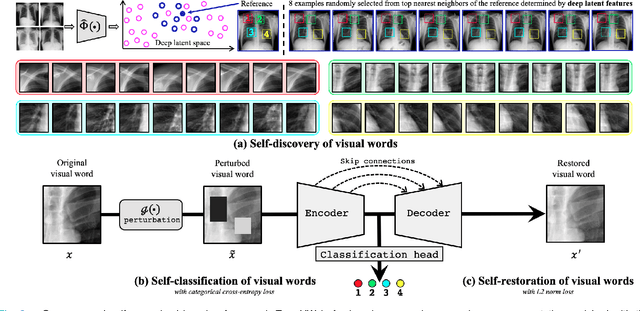
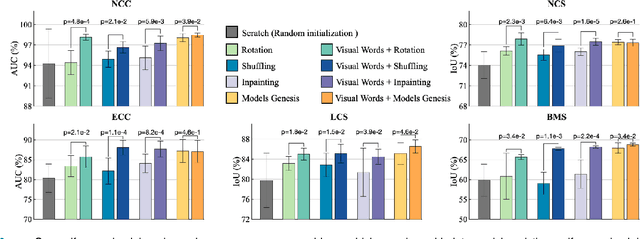

This paper introduces a new concept called "transferable visual words" (TransVW), aiming to achieve annotation efficiency for deep learning in medical image analysis. Medical imaging--focusing on particular parts of the body for defined clinical purposes--generates images of great similarity in anatomy across patients and yields sophisticated anatomical patterns across images, which are associated with rich semantics about human anatomy and which are natural visual words. We show that these visual words can be automatically harvested according to anatomical consistency via self-discovery, and that the self-discovered visual words can serve as strong yet free supervision signals for deep models to learn semantics-enriched generic image representation via self-supervision (self-classification and self-restoration). Our extensive experiments demonstrate the annotation efficiency of TransVW by offering higher performance and faster convergence with reduced annotation cost in several applications. Our TransVW has several important advantages, including (1) TransVW is a fully autodidactic scheme, which exploits the semantics of visual words for self-supervised learning, requiring no expert annotation; (2) visual word learning is an add-on strategy, which complements existing self-supervised methods, boosting their performance; and (3) the learned image representation is semantics-enriched models, which have proven to be more robust and generalizable, saving annotation efforts for a variety of applications through transfer learning. Our code, pre-trained models, and curated visual words are available at https://github.com/JLiangLab/TransVW.