 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding Dialogue Understanding Models for Low-resource Language Indonesian from Scratch
Oct 24, 2024
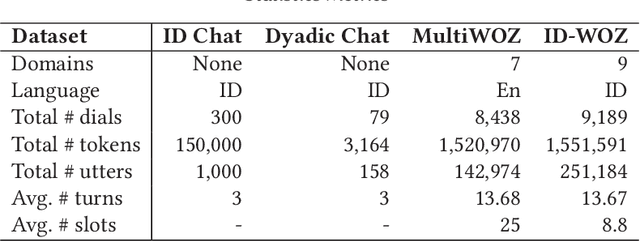
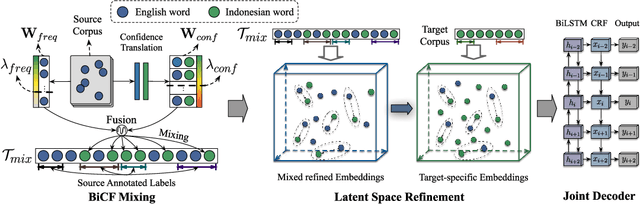

Making use of off-the-shelf resources of resource-rich languages to transfer knowledge for low-resource languages raises much attention recently. The requirements of enabling the model to reach the reliable performance lack well guided, such as the scale of required annotated data or the effective framework. To investigate the first question, we empirically investigate the cost-effectiveness of several methods to train the intent classification and slot-filling models for Indonesia (ID) from scratch by utilizing the English data. Confronting the second challenge, we propose a Bi-Confidence-Frequency Cross-Lingual transfer framework (BiCF), composed by ``BiCF Mixing'', ``Latent Space Refinement'' and ``Joint Decoder'', respectively, to tackle the obstacle of lacking low-resource language dialogue data. Extensive experiments demonstrate our framework performs reliably and cost-efficiently on different scales of manually annotated Indonesian data. We release a large-scale fine-labeled dialogue dataset (ID-WOZ) and ID-BERT of Indonesian for further research.
Referring Expression Grounding by Marginalizing Scene Graph Likelihood
Jun 09, 2019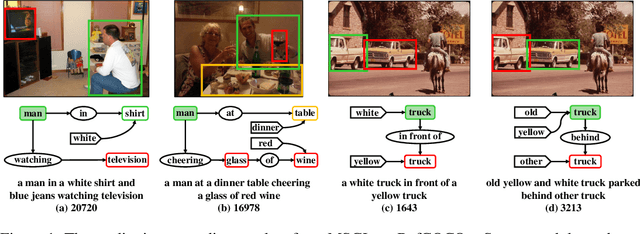



We focus on the task of grounding referring expressions in images, e.g., localizing "the white truck in front of a yellow one". To resolve this task fundamentally, one should first find out the contextual objects (e.g., the "yellow" truck) and then exploit them to disambiguate the referent from other similar objects, by using the attributes and relationships (e.g., "white", "yellow", "in front of"). However, it is extremely challenging to train such a model as the ground-truth of the contextual objects and their relationships are usually missing due to the prohibitive annotation cost. Therefore, nearly all existing methods attempt to evade the above joint grounding and reasoning process, but resort to a holistic association between the sentence and region feature. As a result, they suffer from heavy parameters of fully-connected layers, poor interpretability, and limited generalization to unseen expressions. In this paper, we tackle this challenge by training and inference with the proposed Marginalized Scene Graph Likelihood (MSGL). Specifically, we use scene graph: a graphical representation parsed from the referring expression, where the nodes are objects with attributes and the edges are relationships. Thanks to the conditional random field (CRF) built on scene graph, we can ground every object to its corresponding region, and perform reasoning with the unlabeled contexts by marginalizing out them using the sum-product belief propagation. Overall, our proposed MSGL is effective and interpretable, e.g., on three benchmarks, MSGL consistently outperforms the state-of-the-arts while offers a complete grounding of all the objects in a sentence.