 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding Dialogue Understanding Models for Low-resource Language Indonesian from Scratch
Paper and Code
Oct 24, 2024
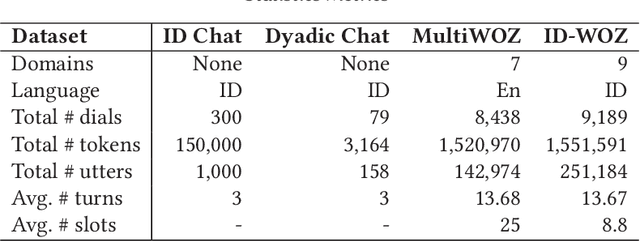
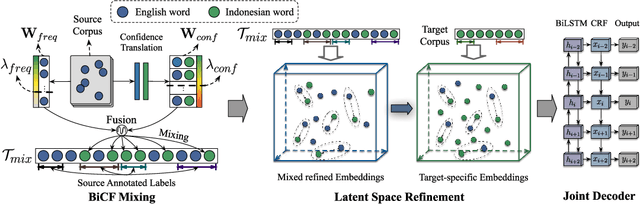

Making use of off-the-shelf resources of resource-rich languages to transfer knowledge for low-resource languages raises much attention recently. The requirements of enabling the model to reach the reliable performance lack well guided, such as the scale of required annotated data or the effective framework. To investigate the first question, we empirically investigate the cost-effectiveness of several methods to train the intent classification and slot-filling models for Indonesia (ID) from scratch by utilizing the English data. Confronting the second challenge, we propose a Bi-Confidence-Frequency Cross-Lingual transfer framework (BiCF), composed by ``BiCF Mixing'', ``Latent Space Refinement'' and ``Joint Decoder'', respectively, to tackle the obstacle of lacking low-resource language dialogue data. Extensive experiments demonstrate our framework performs reliably and cost-efficiently on different scales of manually annotated Indonesian data. We release a large-scale fine-labeled dialogue dataset (ID-WOZ) and ID-BERT of Indonesian for further research.