 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCongenital Heart Disease Classification Using Phonocardiograms: A Scalable Screening Tool for Diverse Environments
Mar 28, 2025



Congenital heart disease (CHD) is a critical condition that demands early detection, particularly in infancy and childhood. This study presents a deep learning model designed to detect CHD using phonocardiogram (PCG) signals, with a focus on its application in global health. We evaluated our model on several datasets, including the primary dataset from Bangladesh, achieving a high accuracy of 94.1%, sensitivity of 92.7%, specificity of 96.3%. The model also demonstrated robust performance on the public PhysioNet Challenge 2022 and 2016 datasets, underscoring its generalizability to diverse populations and data sources. We assessed the performance of the algorithm for single and multiple auscultation sites on the chest, demonstrating that the model maintains over 85% accuracy even when using a single location. Furthermore, our algorithm was able to achieve an accuracy of 80% on low-quality recordings, which cardiologists deemed non-diagnostic. This research suggests that an AI- driven digital stethoscope could serve as a cost-effective screening tool for CHD in resource-limited settings, enhancing clinical decision support and ultimately improving patient outcomes.
Real-time Neonatal Chest Sound Separation using Deep Learning
Oct 26, 2023Auscultation for neonates is a simple and non-invasive method of providing diagnosis for cardiovascular and respiratory disease. Such diagnosis often requires high-quality heart and lung sounds to be captured during auscultation. However, in most cases, obtaining such high-quality sounds is non-trivial due to the chest sounds containing a mixture of heart, lung, and noise sounds. As such, additional preprocessing is needed to separate the chest sounds into heart and lung sounds. This paper proposes a novel deep-learning approach to separate such chest sounds into heart and lung sounds. Inspired by the Conv-TasNet model, the proposed model has an encoder, decoder, and mask generator. The encoder consists of a 1D convolution model and the decoder consists of a transposed 1D convolution. The mask generator is constructed using stacked 1D convolutions and transformers. The proposed model outperforms previous methods in terms of objective distortion measures by 2.01 dB to 5.06 dB in the artificial dataset, as well as computation time, with at least a 17-time improvement. Therefore, our proposed model could be a suitable preprocessing step for any phonocardiogram-based health monitoring system.
Neonatal Face and Facial Landmark Detection from Video Recordings
Feb 08, 2023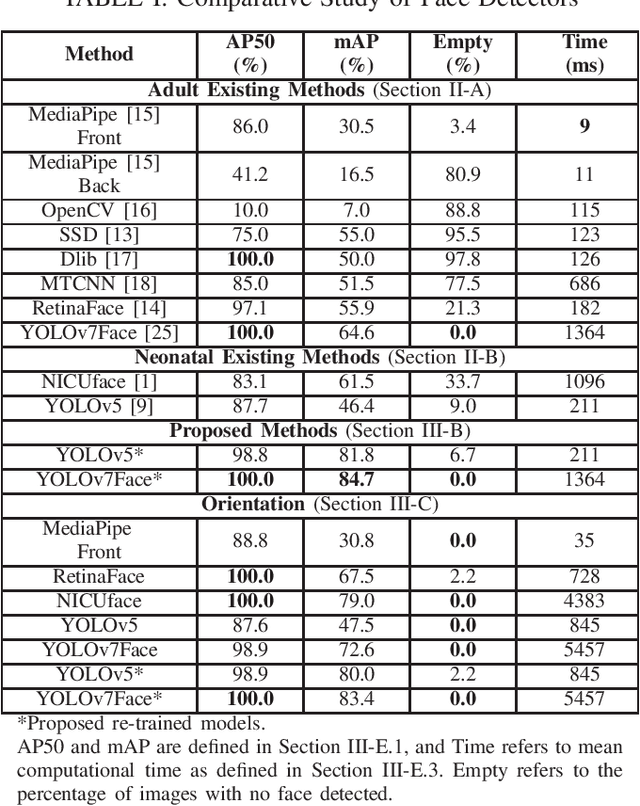
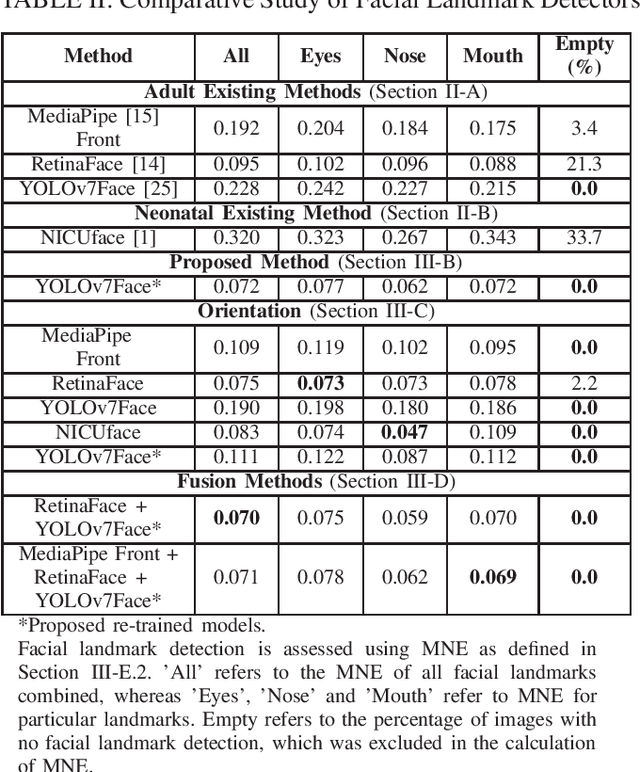
This paper explores automated face and facial landmark detection of neonates, which is an important first step in many video-based neonatal health applications, such as vital sign estimation, pain assessment, sleep-wake classification, and jaundice detection. Utilising three publicly available datasets of neonates in the clinical environment, 366 images (258 subjects) and 89 (66 subjects) were annotated for training and testing, respectively. Transfer learning was applied to two YOLO-based models, with input training images augmented with random horizontal flipping, photo-metric colour distortion, translation and scaling during each training epoch. Additionally, the re-orientation of input images and fusion of trained deep learning models was explored. Our proposed model based on YOLOv7Face outperformed existing methods with a mean average precision of 84.8% for face detection, and a normalised mean error of 0.072 for facial landmark detection. Overall, this will assist in the development of fully automated neonatal health assessment algorithms.
Recent Advances in Scene Image Representation and Classification
Jun 15, 2022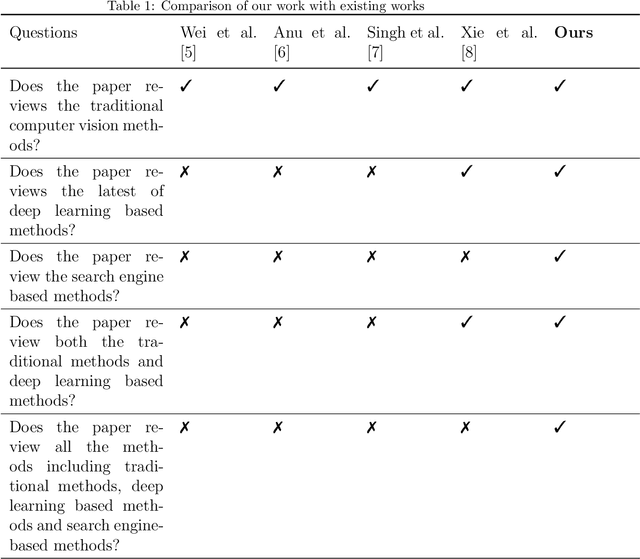
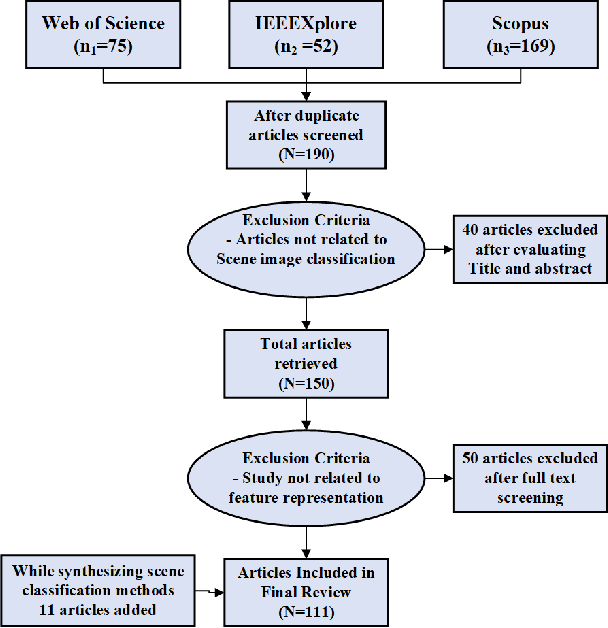
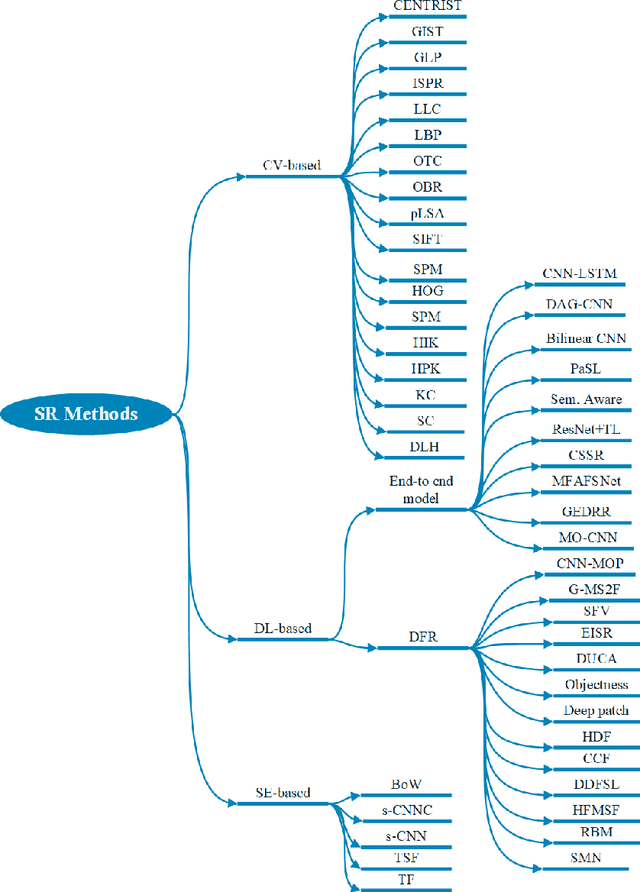
With the rise of deep learning algorithms nowadays, scene image representation methods on big data (e.g., SUN-397) have achieved a significant performance boost in classification. However, the performance is still limited because the scene images are mostly complex in nature having higher intra-class dissimilarity and inter-class similarity problems. To deal with such problems, there are several methods proposed in the literature with their own advantages and limitations. A detailed study of previous works is necessary to understand their pros and cons in image representation and classification. In this paper, we review the existing scene image representation methods that are being used widely for image classification. For this, we, first, devise the taxonomy using the seminal existing methods proposed in the literature to this date. Next, we compare their performance both qualitatively (e.g., quality of outputs, pros/cons, etc.) and quantitatively (e.g., accuracy). Last, we speculate the prominent research directions in scene image representation tasks. Overall, this survey provides in-depth insights and applications of recent scene image representation methods for traditional Computer Vision (CV)-based methods, Deep Learning (DL)-based methods, and Search Engine (SE)-based methods.
Prediction of Neonatal Respiratory Distress in Term Babies at Birth from Digital Stethoscope Recorded Chest Sounds
Jan 25, 2022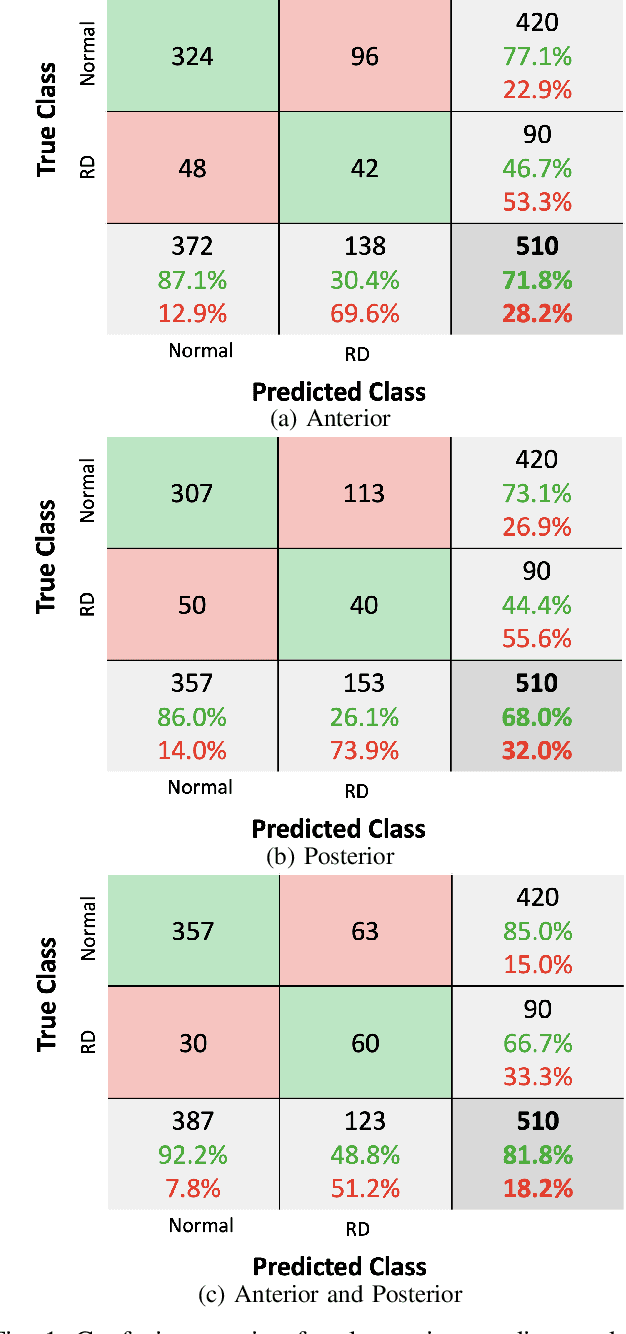
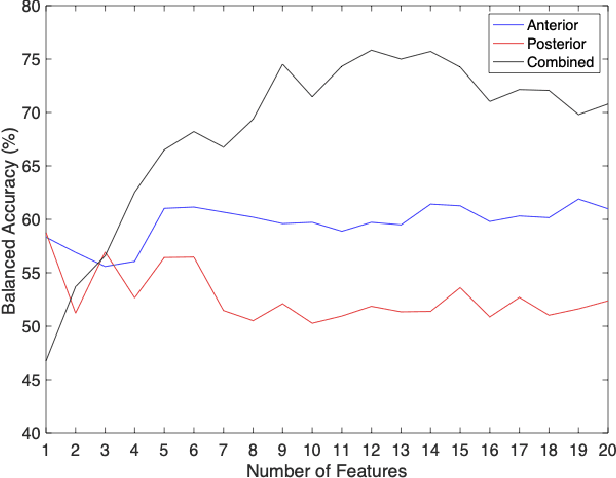
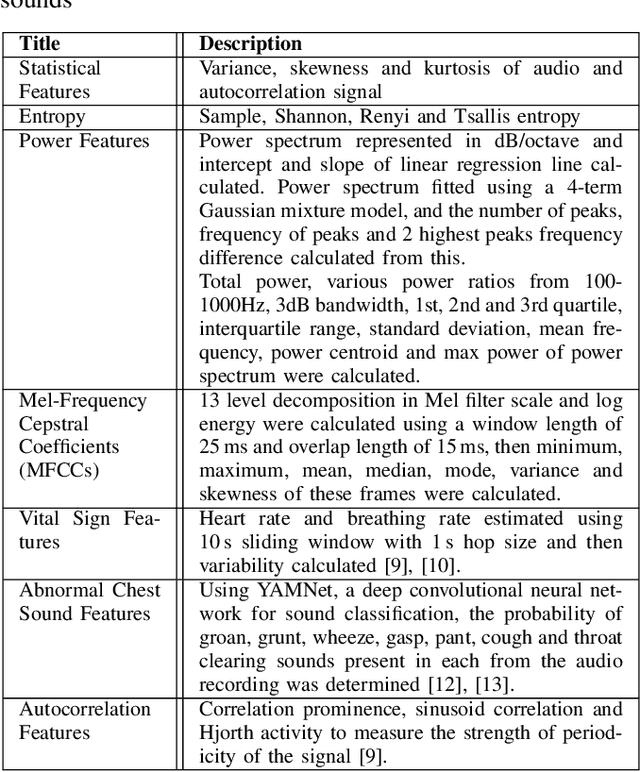
Neonatal respiratory distress is a common condition that if left untreated, can lead to short- and long-term complications. This paper investigates the usage of digital stethoscope recorded chest sounds taken within 1min post-delivery, to enable early detection and prediction of neonatal respiratory distress. Fifty-one term newborns were included in this study, 9 of whom developed respiratory distress. For each newborn, 1min anterior and posterior recordings were taken. These recordings were pre-processed to remove noisy segments and obtain high-quality heart and lung sounds. The random undersampling boosting (RUSBoost) classifier was then trained on a variety of features, such as power and vital sign features extracted from the heart and lung sounds. The RUSBoost algorithm produced specificity, sensitivity, and accuracy results of 85.0%, 66.7% and 81.8%, respectively.
Noisy Neonatal Chest Sound Separation for High-Quality Heart and Lung Sounds
Jan 10, 2022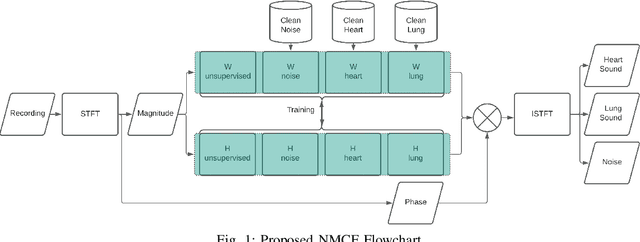
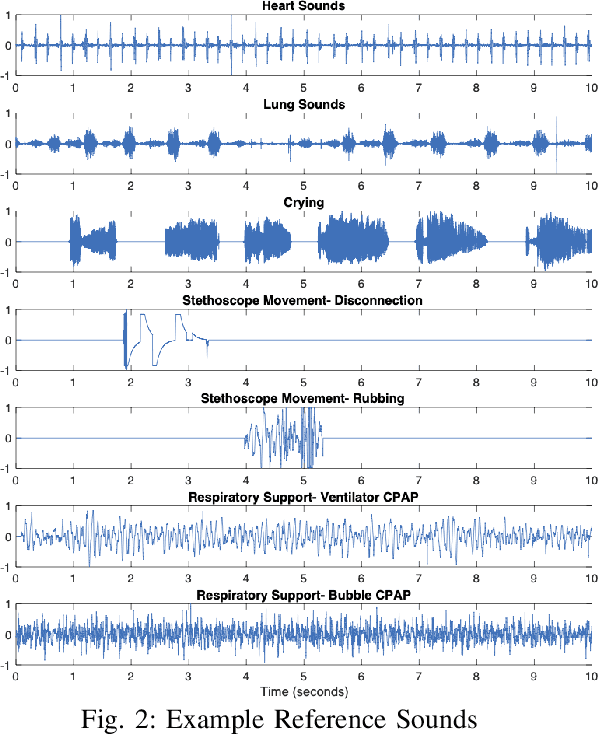
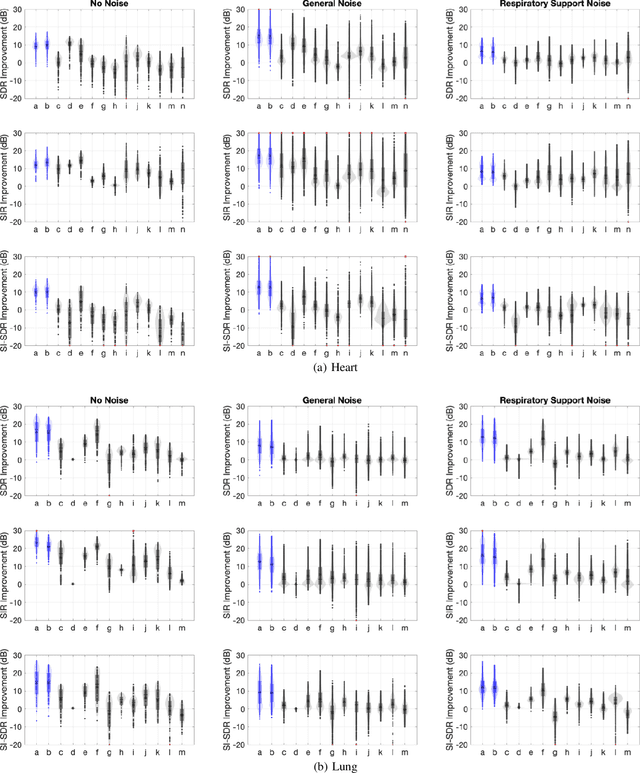
Stethoscope-recorded chest sounds provide the opportunity for remote cardio-respiratory health monitoring of neonates. However, reliable monitoring requires high-quality heart and lung sounds. This paper presents novel Non-negative Matrix Factorisation (NMF) and Non-negative Matrix Co-Factorisation (NMCF) methods for neonatal chest sound separation. To assess these methods and compare with existing single-source separation methods, an artificial mixture dataset was generated comprising of heart, lung and noise sounds. Signal-to-noise ratios were then calculated for these artificial mixtures. These methods were also tested on real-world noisy neonatal chest sounds and assessed based on vital sign estimation error and a signal quality score of 1-5 developed in our previous works. Additionally, the computational cost of all methods was assessed to determine the applicability for real-time processing. Overall, both the proposed NMF and NMCF methods outperform the next best existing method by 2.7dB to 11.6dB for the artificial dataset and 0.40 to 1.12 signal quality improvement for the real-world dataset. The median processing time for the sound separation of a 10s recording was found to be 28.3s for NMCF and 342ms for NMF. Because of stable and robust performance, we believe that our proposed methods are useful to denoise neonatal heart and lung sound in a real-world environment. Codes for proposed and existing methods can be found at: https://github.com/egrooby-monash/Heart-and-Lung-Sound-Separation.
Real-Time Multi-Level Neonatal Heart and Lung Sound Quality Assessment for Telehealth Applications
Sep 29, 2021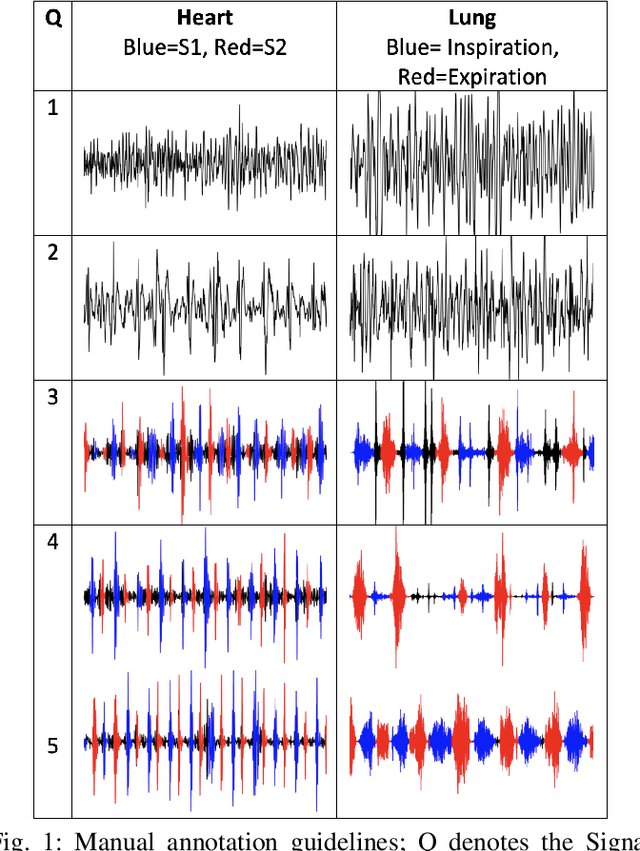
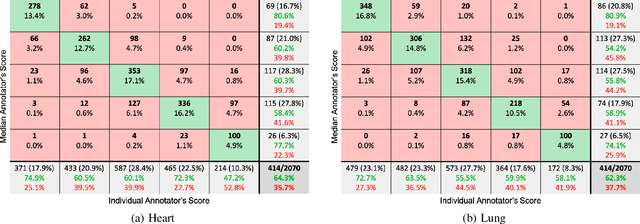
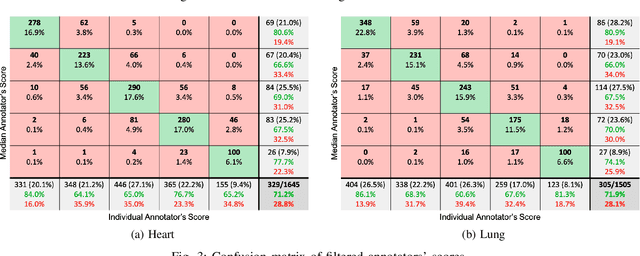
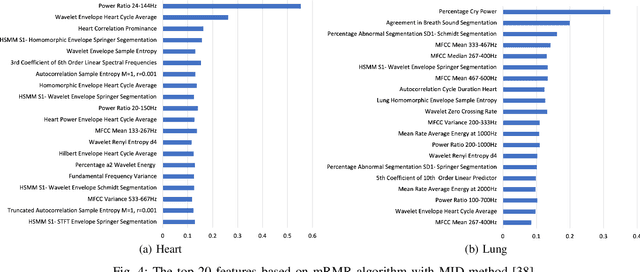
Digital stethoscopes in combination with telehealth allow chest sounds to be easily collected and transmitted for remote monitoring and diagnosis. Chest sounds contain important information about a newborn's cardio-respiratory health. However, low-quality recordings complicate the remote monitoring and diagnosis. In this study, a new method is proposed to objectively and automatically assess heart and lung signal quality on a 5-level scale in real-time and to assess the effect of signal quality on vital sign estimation. For the evaluation, a total of 207 10s long chest sounds were taken from 119 preterm and full-term babies. Thirty of the recordings from ten subjects were obtained with synchronous vital signs from the Neonatal Intensive Care Unit (NICU) based on electrocardiogram recordings. As reference, seven annotators independently assessed the signal quality. For automatic quality classification, 400 features were extracted from the chest sounds. After feature selection using minimum redundancy and maximum relevancy algorithm, class balancing, and hyper-parameter optimization, a variety of multi-class and ordinal classification and regression algorithms were trained. Then, heart rate and breathing rate were automatically estimated from the chest sounds using adapted pre-existing methods. The results of subject-wise leave-one-out cross-validation show that the best-performing models had a mean squared error (MSE) of 0.49 and 0.61, and balanced accuracy of 57% and 51% for heart and lung qualities, respectively. The best-performing models for real-time analysis (<200ms) had MSE of 0.459 and 0.67, and balanced accuracy of 57% and 46%, respectively. Our experimental results underscore that increasing the signal quality leads to a reduction in vital sign error, with only high-quality recordings having a mean absolute error of less than 5 beats per minute, as required for clinical usage.
Challenges of Driver Drowsiness Prediction: The Remaining Steps to Implementation
Sep 17, 2021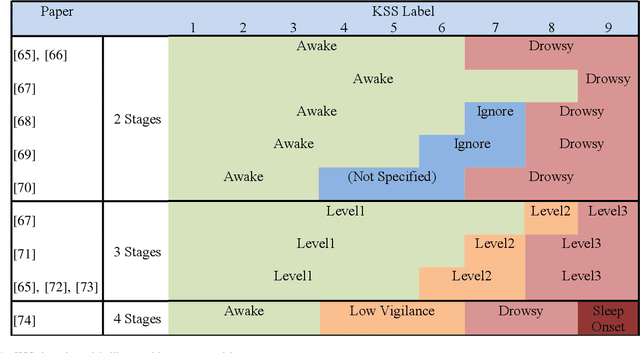


Driver drowsiness has caused a large number of serious injuries and deaths on public roads and incurred billions of taxpayer dollars in costs. Hence, monitoring of drowsiness is critical to reduce this burden on society. This paper surveys the broad range of solutions proposed to address the challenges of driver drowsiness, and identifies the key steps required for successful implementation. Although some commercial products already exist, with vehicle-based methods most commonly implemented by automotive manufacturers, these systems may not have the level of accuracy required to properly predict and monitor drowsiness. State-of-the-art models use physiological, behavioural and vehicle-based methods to detect drowsiness, with hybrid methods emerging as a superior approach. Current setbacks to implementing these methods include late detection, intrusiveness and subject diversity. In particular, physiological monitoring methods such as Electroencephalography (EEG) are intrusive to drivers; while behavioural monitoring is least robust, affected by external factors such as lighting, as well as being subject to privacy concerns. Drowsiness detection models are often developed and validated based on subjective measures, with the Karolinska Sleepiness Scale being the most popular. Subjective and incoherent labelling of drowsiness, lack of on road data and inconsistent protocols for data collection are among other challenges to be addressed to progress drowsiness detection for reliable on-road use.
A New Non-Negative Matrix Co-Factorisation Approach for Noisy Neonatal Chest Sound Separation
Sep 04, 2021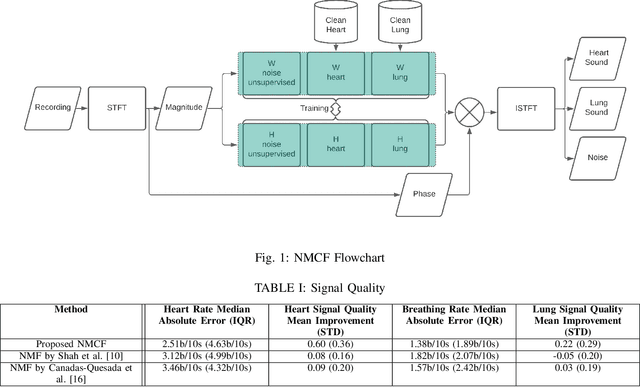
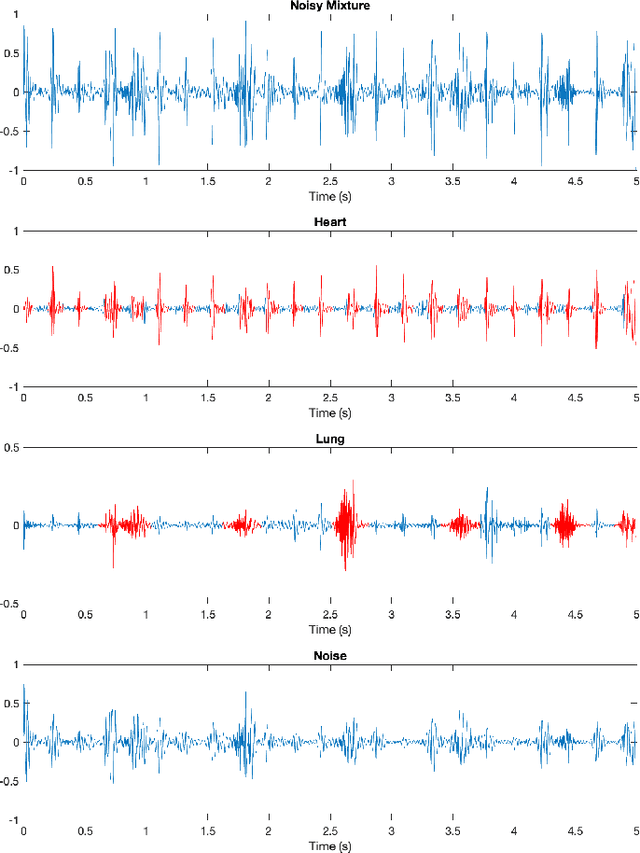
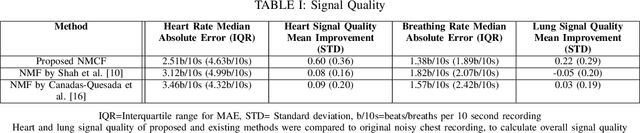
Obtaining high-quality heart and lung sounds enables clinicians to accurately assess a newborn's cardio-respiratory health and provide timely care. However, noisy chest sound recordings are common, hindering timely and accurate assessment. A new Non-negative Matrix Co-Factorisation-based approach is proposed to separate noisy chest sound recordings into heart, lung, and noise components to address this problem. This method is achieved through training with 20 high-quality heart and lung sounds, in parallel with separating the sounds of the noisy recording. The method was tested on 68 10-second noisy recordings containing both heart and lung sounds and compared to the current state of the art Non-negative Matrix Factorisation methods. Results show significant improvements in heart and lung sound quality scores respectively, and improved accuracy of 3.6bpm and 1.2bpm in heart and breathing rate estimation respectively, when compared to existing methods.
Neonatal Bowel Sound Detection Using Convolutional Neural Network and Laplace Hidden Semi-Markov Model
Aug 17, 2021
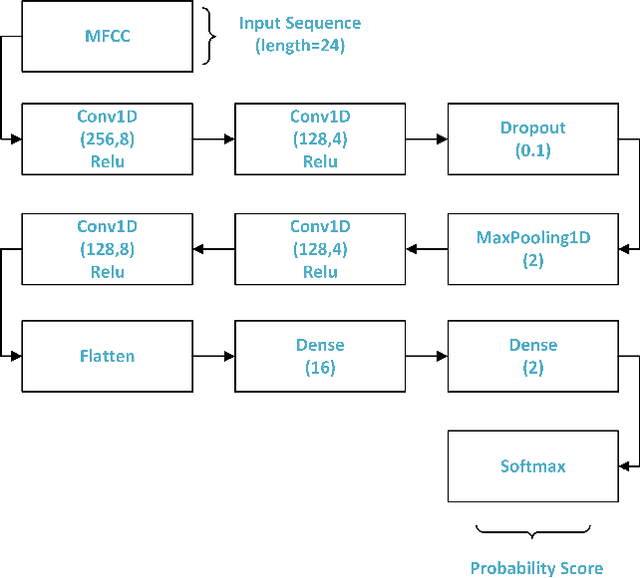
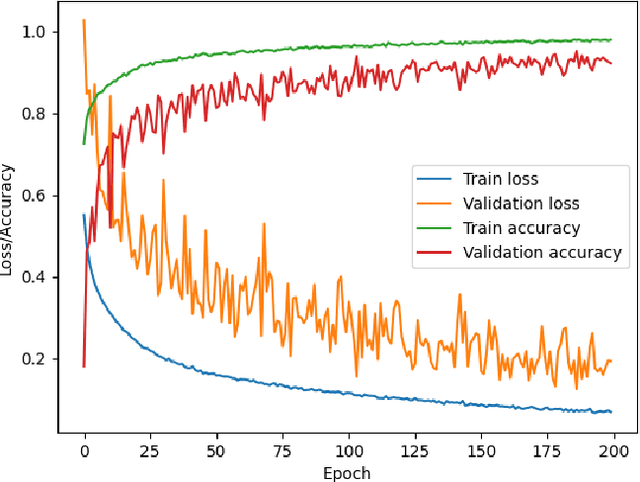
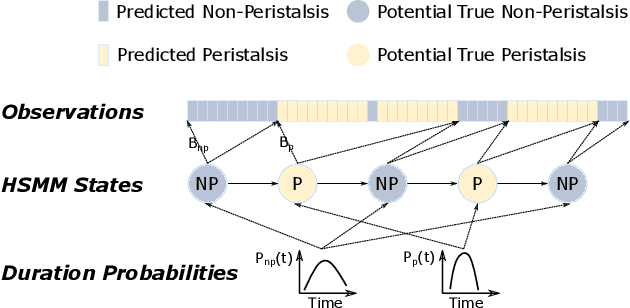
Abdominal auscultation is a convenient, safe and inexpensive method to assess bowel conditions, which is essential in neonatal care. It helps early detection of neonatal bowel dysfunctions and allows timely intervention. This paper presents a neonatal bowel sound detection method to assist the auscultation. Specifically, a Convolutional Neural Network (CNN) is proposed to classify peristalsis and non-peristalsis sounds. The classification is then optimized using a Laplace Hidden Semi-Markov Model (HSMM). The proposed method is validated on abdominal sounds from 49 newborn infants admitted to our tertiary Neonatal Intensive Care Unit (NICU). The results show that the method can effectively detect bowel sounds with accuracy and area under curve (AUC) score being 89.81% and 83.96% respectively, outperforming 13 baseline methods. Furthermore, the proposed Laplace HSMM refinement strategy is proven capable to enhance other bowel sound detection models. The outcomes of this work have the potential to facilitate future telehealth applications for neonatal care. The source code of our work can be found at: https://bitbucket.org/chirudeakin/neonatal-bowel-sound-classification/