 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearned Pulse Shaping Design for PAPR Reduction in DFT-s-OFDM
Apr 24, 2024High peak-to-average power ratio (PAPR) is one of the main factors limiting cell coverage for cellular systems, especially in the uplink direction. Discrete Fourier transform spread orthogonal frequency-domain multiplexing (DFT-s-OFDM) with spectrally-extended frequency-domain spectrum shaping (FDSS) is one of the efficient techniques deployed to lower the PAPR of the uplink waveforms. In this work, we propose a machine learning-based framework to determine the FDSS filter, optimizing a tradeoff between the symbol error rate (SER), the PAPR, and the spectral flatness requirements. Our end-to-end optimization framework considers multiple important design constraints, including the Nyquist zero-ISI (inter-symbol interference) condition. The numerical results show that learned FDSS filters lower the PAPR compared to conventional baselines, with minimal SER degradation. Tuning the parameters of the optimization also helps us understand the fundamental limitations and characteristics of the FDSS filters for PAPR reduction.
Neural Compress-and-Forward for the Relay Channel
Apr 22, 2024



The relay channel, consisting of a source-destination pair and a relay, is a fundamental component of cooperative communications. While the capacity of a general relay channel remains unknown, various relaying strategies, including compress-and-forward (CF), have been proposed. For CF, given the correlated signals at the relay and destination, distributed compression techniques, such as Wyner-Ziv coding, can be harnessed to utilize the relay-to-destination link more efficiently. In light of the recent advancements in neural network-based distributed compression, we revisit the relay channel problem, where we integrate a learned one-shot Wyner--Ziv compressor into a primitive relay channel with a finite-capacity and orthogonal (or out-of-band) relay-to-destination link. The resulting neural CF scheme demonstrates that our task-oriented compressor recovers "binning" of the quantized indices at the relay, mimicking the optimal asymptotic CF strategy, although no structure exploiting the knowledge of source statistics was imposed into the design. We show that the proposed neural CF scheme, employing finite order modulation, operates closely to the capacity of a primitive relay channel that assumes a Gaussian codebook. Our learned compressor provides the first proof-of-concept work toward a practical neural CF relaying scheme.
Precoding-oriented Massive MIMO CSI Feedback Design
Feb 22, 2023

Downlink massive multiple-input multiple-output (MIMO) precoding algorithms in frequency division duplexing (FDD) systems rely on accurate channel state information (CSI) feedback from users. In this paper, we analyze the tradeoff between the CSI feedback overhead and the performance achieved by the users in systems in terms of achievable rate. The final goal of the proposed system is to determine the beamforming information (i.e., precoding) from channel realizations. We employ a deep learning-based approach to design the end-to-end precoding-oriented feedback architecture, that includes learned pilots, users' compressors, and base station processing. We propose a loss function that maximizes the sum of achievable rates with minimal feedback overhead. Simulation results show that our approach outperforms previous precoding-oriented methods, and provides more efficient solutions with respect to conventional methods that separate the CSI compression blocks from the precoding processing.
Reinforcement Learning for Channel Coding: Learned Bit-Flipping Decoding
Jun 11, 2019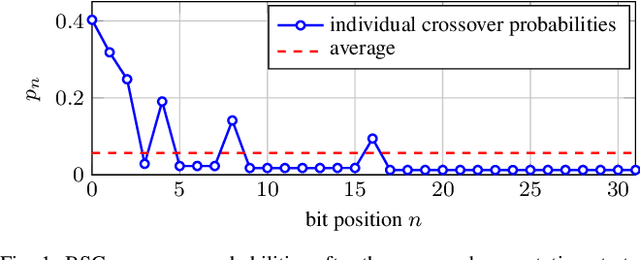

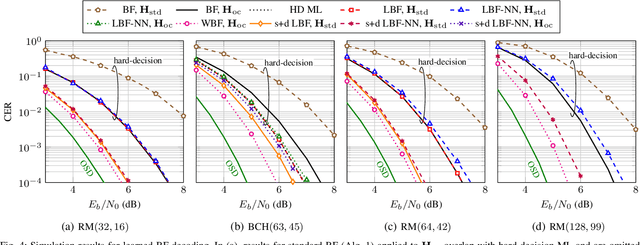
In this paper, we use reinforcement learning to find effective decoding strategies for binary linear codes. We start by reviewing several iterative decoding algorithms that involve a decision-making process at each step, including bit-flipping (BF) decoding, residual belief propagation, and anchor decoding. We then illustrate how such algorithms can be mapped to Markov decision processes allowing for data-driven learning of optimal decision strategies, rather than basing decisions on heuristics or intuition. As a case study, we consider BF decoding for both the binary symmetric and additive white Gaussian noise channel. Our results show that learned BF decoders can offer a range of performance--complexity trade-offs for the considered Reed--Muller and BCH codes, and achieve near-optimal performance in some cases. We also demonstrate learning convergence speed-ups when biasing the learning process towards correct decoding decisions, as opposed to relying only on random explorations and past knowledge.
Learned Belief-Propagation Decoding with Simple Scaling and SNR Adaptation
Jan 24, 2019
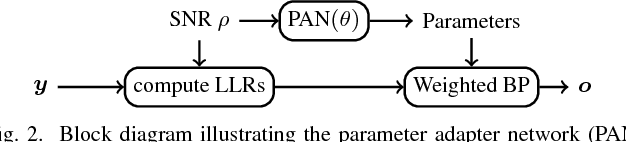
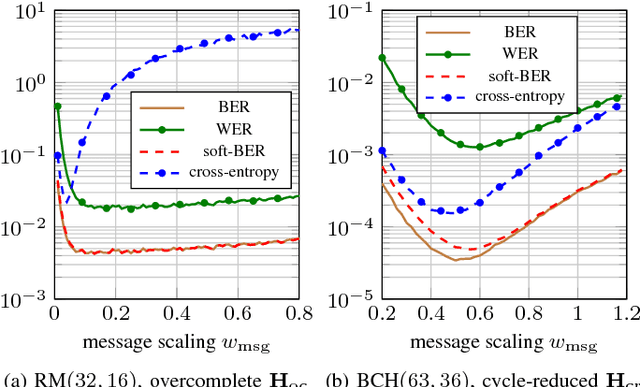
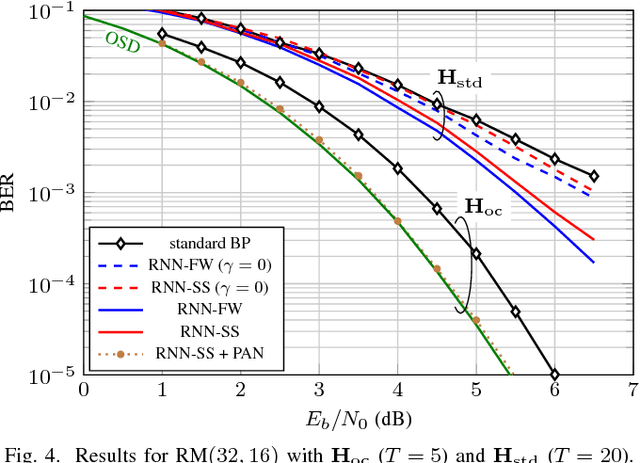
We consider the weighted belief-propagation (WBP) decoder recently proposed by Nachmani et al. where different weights are introduced for each Tanner graph edge and optimized using machine learning techniques. Our focus is on simple-scaling models that use the same weights across certain edges to reduce the storage and computational burden. The main contribution is to show that simple scaling with few parameters often achieves the same gain as the full parameterization. Moreover, several training improvements for WBP are proposed. For example, it is shown that minimizing average binary cross-entropy is suboptimal in general in terms of bit error rate (BER) and a new "soft-BER" loss is proposed which can lead to better performance. We also investigate parameter adapter networks (PANs) that learn the relation between the signal-to-noise ratio and the WBP parameters. As an example, for the (32,16) Reed-Muller code with a highly redundant parity-check matrix, training a PAN with soft-BER loss gives near-maximum-likelihood performance assuming simple scaling with only three parameters.