 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Superpixel Segmentation Methods Influence Deforestation Image Classification?
Oct 06, 2025
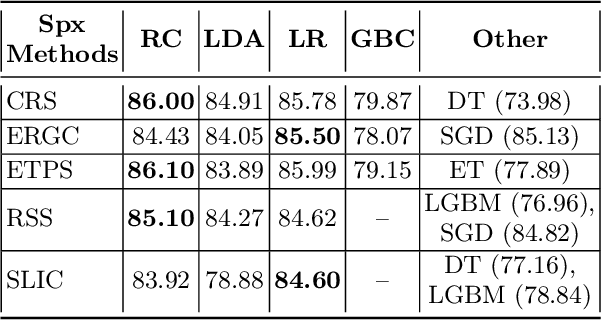

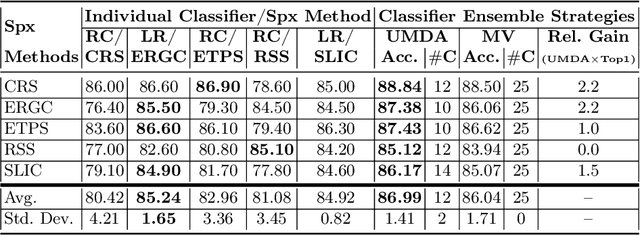
Image segmentation is a crucial step in various visual applications, including environmental monitoring through remote sensing. In the context of the ForestEyes project, which combines citizen science and machine learning to detect deforestation in tropical forests, image segments are used for labeling by volunteers and subsequent model training. Traditionally, the Simple Linear Iterative Clustering (SLIC) algorithm is adopted as the segmentation method. However, recent studies have indicated that other superpixel-based methods outperform SLIC in remote sensing image segmentation, and might suggest that they are more suitable for the task of detecting deforested areas. In this sense, this study investigated the impact of the four best segmentation methods, together with SLIC, on the training of classifiers for the target application. Initially, the results showed little variation in performance among segmentation methods, even when selecting the top five classifiers using the PyCaret AutoML library. However, by applying a classifier fusion approach (ensemble of classifiers), noticeable improvements in balanced accuracy were observed, highlighting the importance of both the choice of segmentation method and the combination of machine learning-based models for deforestation detection tasks.
Sampling Strategies based on Wisdom of Crowds for Amazon Deforestation Detection
Aug 22, 2024
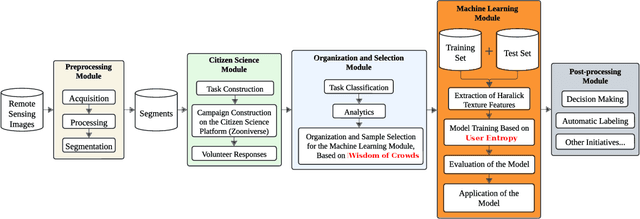

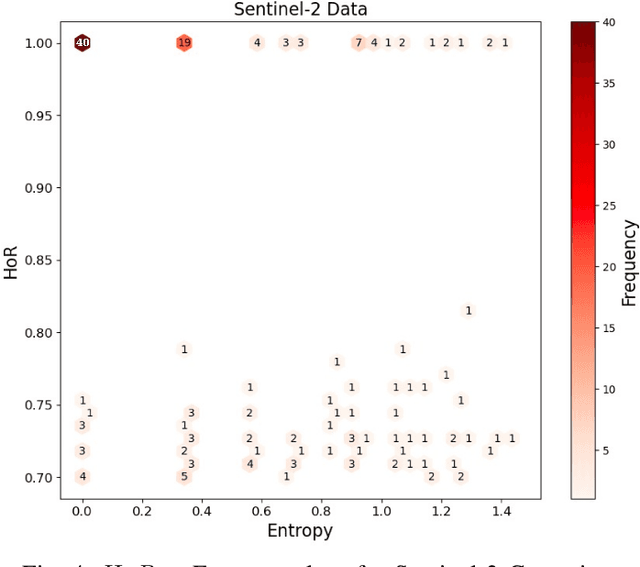
Conserving tropical forests is highly relevant socially and ecologically because of their critical role in the global ecosystem. However, the ongoing deforestation and degradation affect millions of hectares each year, necessitating government or private initiatives to ensure effective forest monitoring. In April 2019, a project based on Citizen Science and Machine Learning models called ForestEyes (FE) was launched with the aim of providing supplementary data to assist experts from government and non-profit organizations in their deforestation monitoring efforts. Recent research has shown that labeling FE project volunteers/citizen scientists helps tailor machine learning models. In this sense, we adopt the FE project to create different sampling strategies based on the wisdom of crowds to select the most suitable samples from the training set to learn an SVM technique and obtain better classification results in deforestation detection tasks. In our experiments, we can show that our strategy based on user entropy-increasing achieved the best classification results in the deforestation detection task when compared with the random sampling strategies, as well as, reducing the convergence time of the SVM technique.
FaceMixup: Enhancing Facial Expression Recognition through Mixed Face Regularization
May 30, 2024
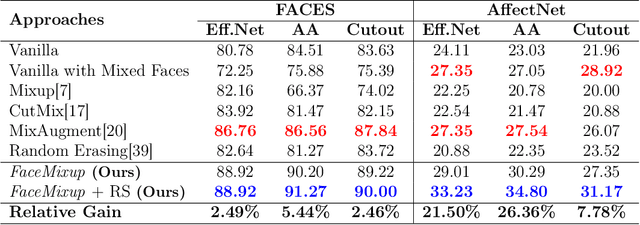
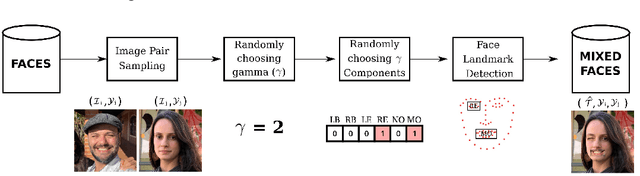
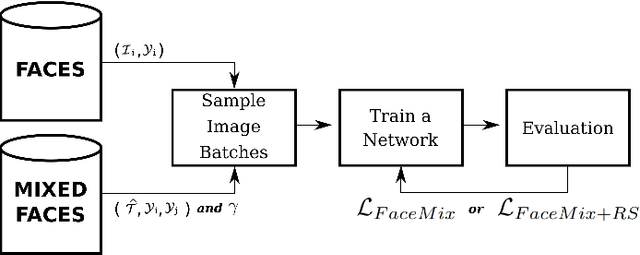
The proliferation of deep learning solutions and the scarcity of large annotated datasets pose significant challenges in real-world applications. Various strategies have been explored to overcome this challenge, with data augmentation (DA) approaches emerging as prominent solutions. DA approaches involve generating additional examples by transforming existing labeled data, thereby enriching the dataset and helping deep learning models achieve improved generalization without succumbing to overfitting. In real applications, where solutions based on deep learning are widely used, there is facial expression recognition (FER), which plays an essential role in human communication, improving a range of knowledge areas (e.g., medicine, security, and marketing). In this paper, we propose a simple and comprehensive face data augmentation approach based on mixed face component regularization that outperforms the classical DA approaches from the literature, including the MixAugment which is a specific approach for the target task in two well-known FER datasets existing in the literature.
A Satellite Band Selection Framework for Amazon Forest Deforestation Detection Task
Apr 03, 2024



The conservation of tropical forests is a topic of significant social and ecological relevance due to their crucial role in the global ecosystem. Unfortunately, deforestation and degradation impact millions of hectares annually, necessitating government or private initiatives for effective forest monitoring. This study introduces a novel framework that employs the Univariate Marginal Distribution Algorithm (UMDA) to select spectral bands from Landsat-8 satellite, optimizing the representation of deforested areas. This selection guides a semantic segmentation architecture, DeepLabv3+, enhancing its performance. Experimental results revealed several band compositions that achieved superior balanced accuracy compared to commonly adopted combinations for deforestation detection, utilizing segment classification via a Support Vector Machine (SVM). Moreover, the optimal band compositions identified by the UMDA-based approach improved the performance of the DeepLabv3+ architecture, surpassing state-of-the-art approaches compared in this study. The observation that a few selected bands outperform the total contradicts the data-driven paradigm prevalent in the deep learning field. Therefore, this suggests an exception to the conventional wisdom that 'more is always better'.
A Framework of Landsat-8 Band Selection based on UMDA for Deforestation Detection
Nov 17, 2023The conservation of tropical forests is a current subject of social and ecological relevance due to their crucial role in the global ecosystem. Unfortunately, millions of hectares are deforested and degraded each year. Therefore, government or private initiatives are needed for monitoring tropical forests. In this sense, this work proposes a novel framework, which uses of distribution estimation algorithm (UMDA) to select spectral bands from Landsat-8 that yield a better representation of deforestation areas to guide a semantic segmentation architecture called DeepLabv3+. In performed experiments, it was possible to find several compositions that reach balanced accuracy superior to 90% in segment classification tasks. Furthermore, the best composition (651) found by UMDA algorithm fed the DeepLabv3+ architecture and surpassed in efficiency and effectiveness all compositions compared in this work.
Combining Deep Metric Learning Approaches for Aerial Scene Classification
Mar 20, 2023Aerial scene classification, which aims to semantically label remote sensing images in a set of predefined classes (e.g., agricultural, beach, and harbor), is a very challenging task in remote sensing due to high intra-class variability and the different scales and orientations of the objects present in the dataset images. In remote sensing area, the use of CNN architectures as an alternative solution is also a reality for scene classification tasks. Generally, these CNNs are used to perform the traditional image classification task. However, another less used way to classify remote sensing image might be the one that uses deep metric learning (DML) approaches. In this sense, this work proposes to employ six DML approaches for aerial scene classification tasks, analysing their behave with four different pre-trained CNNs as well as combining them through the use of evolutionary computation algorithm (UMDA). In performed experiments, it is possible to observe than DML approaches can achieve the best classification results when compared to traditional pre-trained CNNs for three well-known remote sensing aerial scene datasets. In addition, the UMDA algorithm proved to be a promising strategy to combine DML approaches when there is diversity among them, managing to improve at least 5.6% of accuracy in the classification results using almost 50\% of the available classifiers for the construction of the final ensemble of classifiers.
ForestEyes Project: Conception, Enhancements, and Challenges
Aug 24, 2022



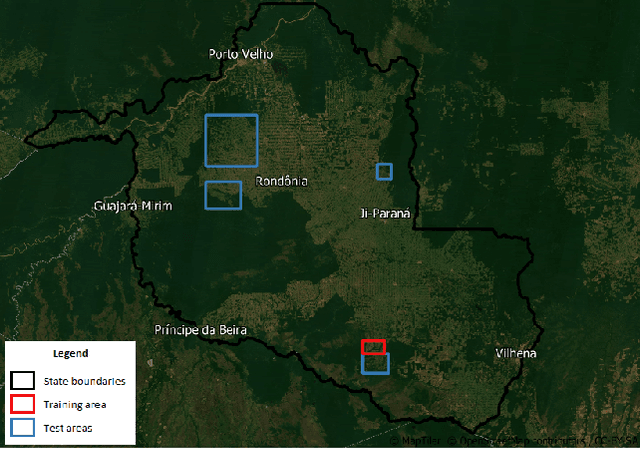
Rainforests play an important role in the global ecosystem. However, significant regions of them are facing deforestation and degradation due to several reasons. Diverse government and private initiatives were created to monitor and alert for deforestation increases from remote sensing images, using different ways to deal with the notable amount of generated data. Citizen Science projects can also be used to reach the same goal. Citizen Science consists of scientific research involving nonprofessional volunteers for analyzing, collecting data, and using their computational resources to outcome advancements in science and to increase the public's understanding of problems in specific knowledge areas such as astronomy, chemistry, mathematics, and physics. In this sense, this work presents a Citizen Science project called ForestEyes, which uses volunteer's answers through the analysis and classification of remote sensing images to monitor deforestation regions in rainforests. To evaluate the quality of those answers, different campaigns/workflows were launched using remote sensing images from Brazilian Legal Amazon and their results were compared to an official groundtruth from the Amazon Deforestation Monitoring Project PRODES. In this work, the first two workflows that enclose the State of Rond\^onia in the years 2013 and 2016 received more than $35,000$ answers from $383$ volunteers in the $2,050$ created tasks in only two and a half weeks after their launch. For the other four workflows, even enclosing the same area (Rond\^onia) and different setups (e.g., image segmentation method, image resolution, and detection target), they received $51,035$ volunteers' answers gathered from $281$ volunteers in $3,358$ tasks. In the performed experiments...
Neuroevolution-based Classifiers for Deforestation Detection in Tropical Forests
Aug 23, 2022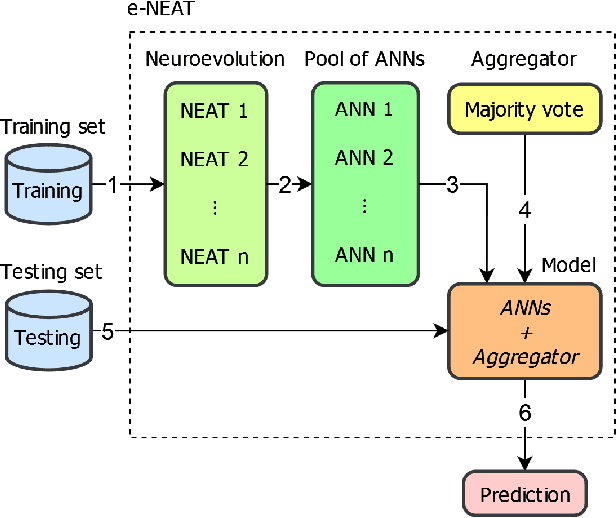
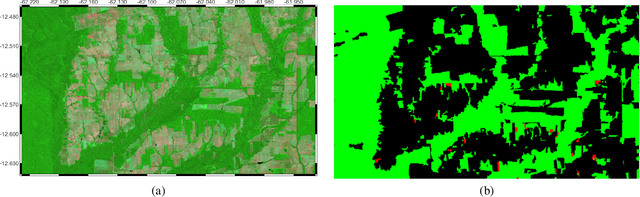

Tropical forests represent the home of many species on the planet for flora and fauna, retaining billions of tons of carbon footprint, promoting clouds and rain formation, implying a crucial role in the global ecosystem, besides representing the home to countless indigenous peoples. Unfortunately, millions of hectares of tropical forests are lost every year due to deforestation or degradation. To mitigate that fact, monitoring and deforestation detection programs are in use, in addition to public policies for the prevention and punishment of criminals. These monitoring/detection programs generally use remote sensing images, image processing techniques, machine learning methods, and expert photointerpretation to analyze, identify and quantify possible changes in forest cover. Several projects have proposed different computational approaches, tools, and models to efficiently identify recent deforestation areas, improving deforestation monitoring programs in tropical forests. In this sense, this paper proposes the use of pattern classifiers based on neuroevolution technique (NEAT) in tropical forest deforestation detection tasks. Furthermore, a novel framework called e-NEAT has been created and achieved classification results above $90\%$ for balanced accuracy measure in the target application using an extremely reduced and limited training set for learning the classification models. These results represent a relative gain of $6.2\%$ over the best baseline ensemble method compared in this paper
An Evolutionary Approach for Creating of Diverse Classifier Ensembles
Aug 23, 2022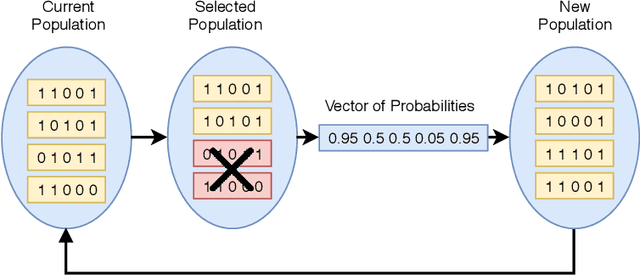

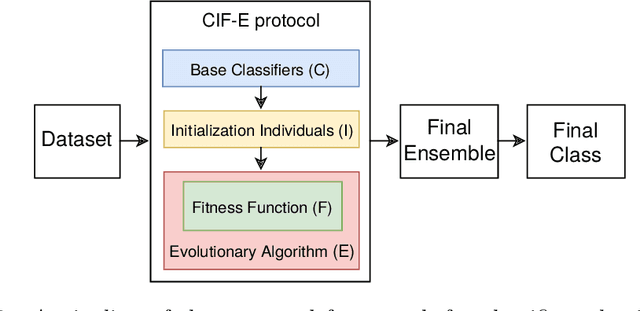
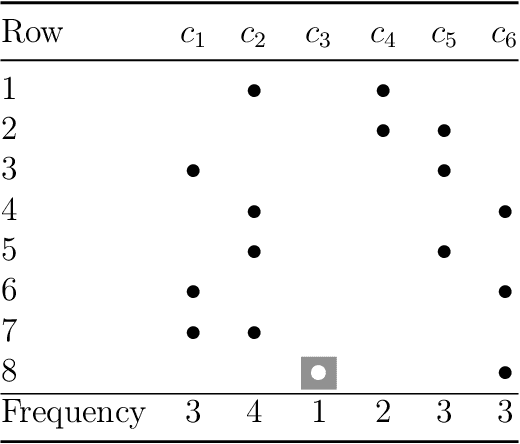
Classification is one of the most studied tasks in data mining and machine learning areas and many works in the literature have been presented to solve classification problems for multiple fields of knowledge such as medicine, biology, security, and remote sensing. Since there is no single classifier that achieves the best results for all kinds of applications, a good alternative is to adopt classifier fusion strategies. A key point in the success of classifier fusion approaches is the combination of diversity and accuracy among classifiers belonging to an ensemble. With a large amount of classification models available in the literature, one challenge is the choice of the most suitable classifiers to compose the final classification system, which generates the need of classifier selection strategies. We address this point by proposing a framework for classifier selection and fusion based on a four-step protocol called CIF-E (Classifiers, Initialization, Fitness function, and Evolutionary algorithm). We implement and evaluate 24 varied ensemble approaches following the proposed CIF-E protocol and we are able to find the most accurate approach. A comparative analysis has also been performed among the best approaches and many other baselines from the literature. The experiments show that the proposed evolutionary approach based on Univariate Marginal Distribution Algorithm (UMDA) can outperform the state-of-the-art literature approaches in many well-known UCI datasets.
Os Dados dos Brasileiros sob Risco na Era da Inteligência Artificial?
May 03, 2022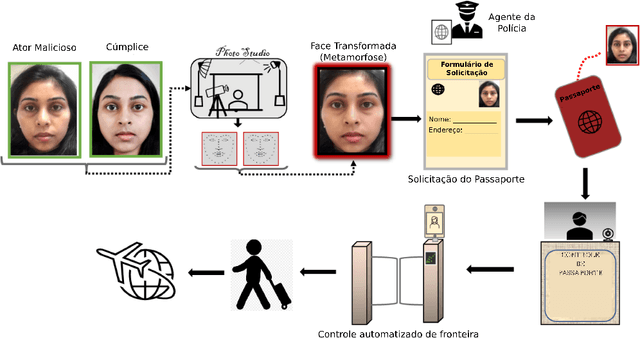
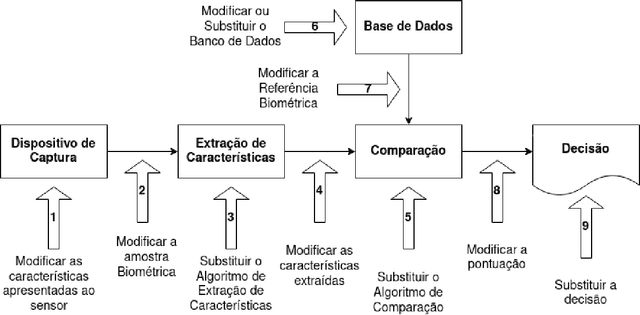
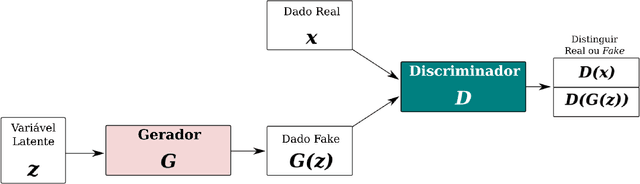

Advances in image processing and analysis as well as machine learning techniques have contributed to the use of biometric recognition systems in daily people tasks. These tasks range from simple access to mobile devices to tagging friends in photos shared on social networks and complex financial operations on self-service devices for banking transactions. In China, the use of these systems goes beyond personal use becoming a country's government policy with the objective of monitoring the behavior of its population. On July 05th 2021, the Brazilian government announced acquisition of a biometric recognition system to be used nationwide. In the opposite direction to China, Europe and some American cities have already started the discussion about the legality of using biometric systems in public places, even banning this practice in their territory. In order to open a deeper discussion about the risks and legality of using these systems, this work exposes the vulnerabilities of biometric recognition systems, focusing its efforts on the face modality. Furthermore, it shows how it is possible to fool a biometric system through a well-known presentation attack approach in the literature called morphing. Finally, a list of ten concerns was created to start the discussion about the security of citizen data and data privacy law in the Age of Artificial Intelligence (AI).