 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiet Networks: Thin Parameters for Fat Genomics
Mar 16, 2017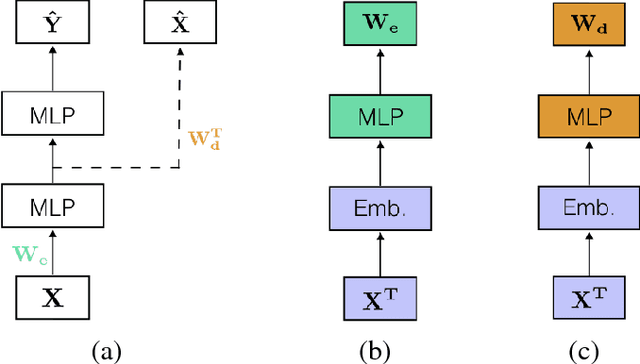
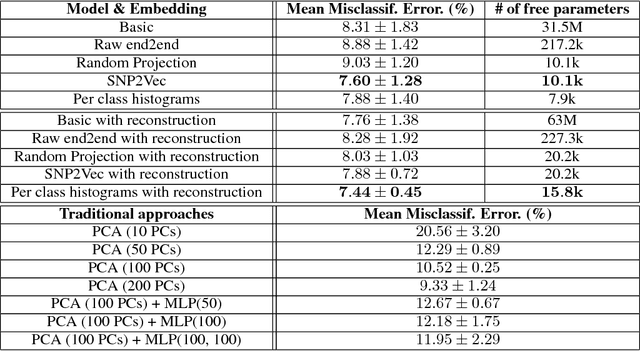
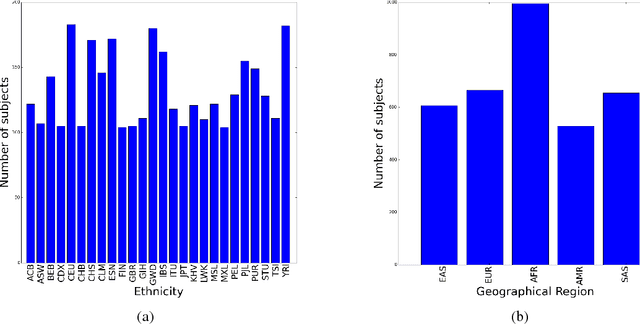
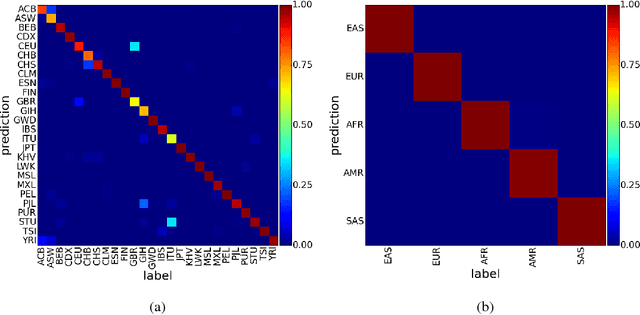
Learning tasks such as those involving genomic data often poses a serious challenge: the number of input features can be orders of magnitude larger than the number of training examples, making it difficult to avoid overfitting, even when using the known regularization techniques. We focus here on tasks in which the input is a description of the genetic variation specific to a patient, the single nucleotide polymorphisms (SNPs), yielding millions of ternary inputs. Improving the ability of deep learning to handle such datasets could have an important impact in precision medicine, where high-dimensional data regarding a particular patient is used to make predictions of interest. Even though the amount of data for such tasks is increasing, this mismatch between the number of examples and the number of inputs remains a concern. Naive implementations of classifier neural networks involve a huge number of free parameters in their first layer: each input feature is associated with as many parameters as there are hidden units. We propose a novel neural network parametrization which considerably reduces the number of free parameters. It is based on the idea that we can first learn or provide a distributed representation for each input feature (e.g. for each position in the genome where variations are observed), and then learn (with another neural network called the parameter prediction network) how to map a feature's distributed representation to the vector of parameters specific to that feature in the classifier neural network (the weights which link the value of the feature to each of the hidden units). We show experimentally on a population stratification task of interest to medical studies that the proposed approach can significantly reduce both the number of parameters and the error rate of the classifier.