 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving the Predictive Performances of $k$ Nearest Neighbors Learning by Efficient Variable Selection
Nov 04, 2022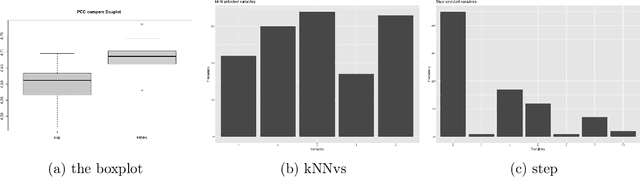
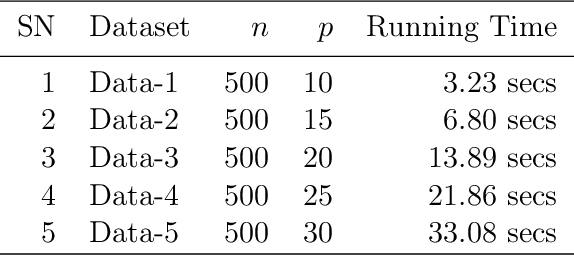
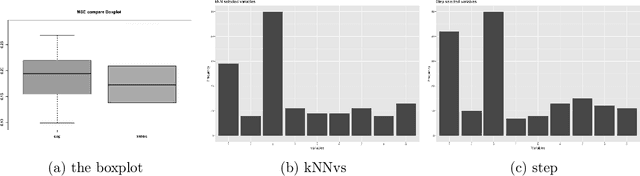
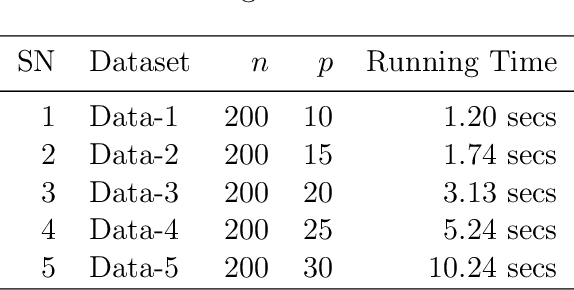
This paper computationally demonstrates a sharp improvement in predictive performance for $k$ nearest neighbors thanks to an efficient forward selection of the predictor variables. We show both simulated and real-world data that this novel repeatedly approaches outperformance regression models under stepwise selection
A Computational Exploration of Emerging Methods of Variable Importance Estimation
Aug 05, 2022



Estimating the importance of variables is an essential task in modern machine learning. This help to evaluate the goodness of a feature in a given model. Several techniques for estimating the importance of variables have been developed during the last decade. In this paper, we proposed a computational and theoretical exploration of the emerging methods of variable importance estimation, namely: Least Absolute Shrinkage and Selection Operator (LASSO), Support Vector Machine (SVM), the Predictive Error Function (PERF), Random Forest (RF), and Extreme Gradient Boosting (XGBOOST) that were tested on different kinds of real-life and simulated data. All these methods can handle both regression and classification tasks seamlessly but all fail when it comes to dealing with data containing missing values. The implementation has shown that PERF has the best performance in the case of highly correlated data closely followed by RF. PERF and XGBOOST are "data-hungry" methods, they had the worst performance on small data sizes but they are the fastest when it comes to the execution time. SVM is the most appropriate when many redundant features are in the dataset. A surplus with the PERF is its natural cut-off at zero helping to separate positive and negative scores with all positive scores indicating essential and significant features while the negatives score indicates useless features. RF and LASSO are very versatile in a way that they can be used in almost all situations despite they are not giving the best results.
Naive Dictionary On Musical Corpora: From Knowledge Representation To Pattern Recognition
Nov 29, 2018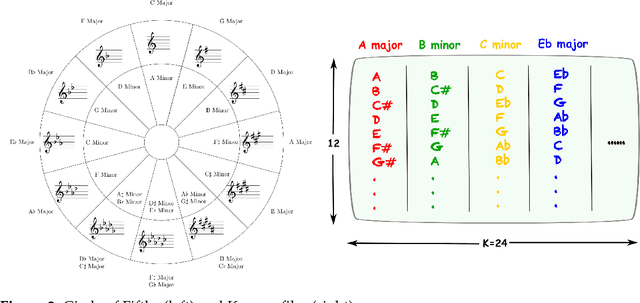
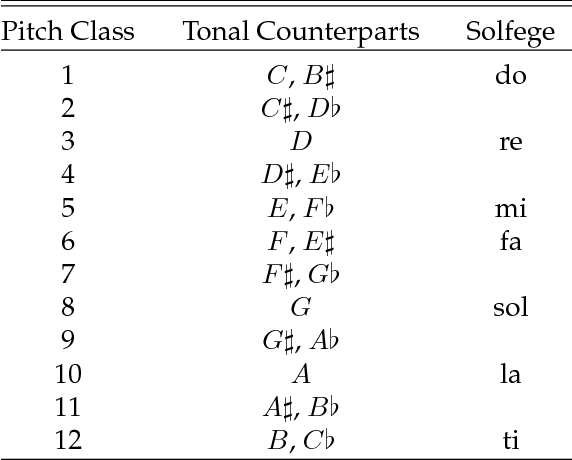
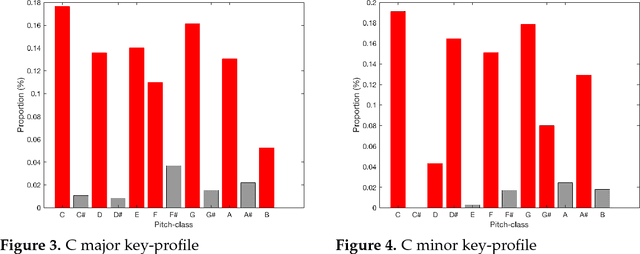
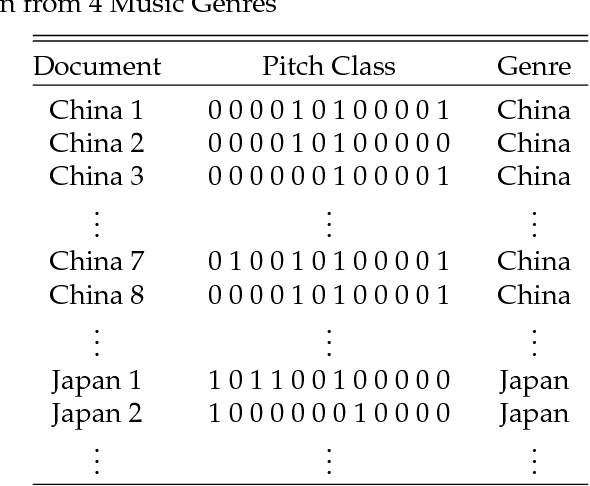
In this paper, we propose and develop the novel idea of treating musical sheets as literary documents in the traditional text analytics parlance, to fully benefit from the vast amount of research already existing in statistical text mining and topic modelling. We specifically introduce the idea of representing any given piece of music as a collection of "musical words" that we codenamed "muselets", which are essentially musical words of various lengths. Given the novelty and therefore the extremely difficulty of properly forming a complete version of a dictionary of muselets, the present paper focuses on a simpler albeit naive version of the ultimate dictionary, which we refer to as a Naive Dictionary because of the fact that all the words are of the same length. We specifically herein construct a naive dictionary featuring a corpus made up of African American, Chinese, Japanese and Arabic music, on which we perform both topic modelling and pattern recognition. Although some of the results based on the Naive Dictionary are reasonably good, we anticipate phenomenal predictive performances once we get around to actually building a full scale complete version of our intended dictionary of muselets.
Meta-Learning with Hessian-Free Approach in Deep Neural Nets Training
Sep 07, 2018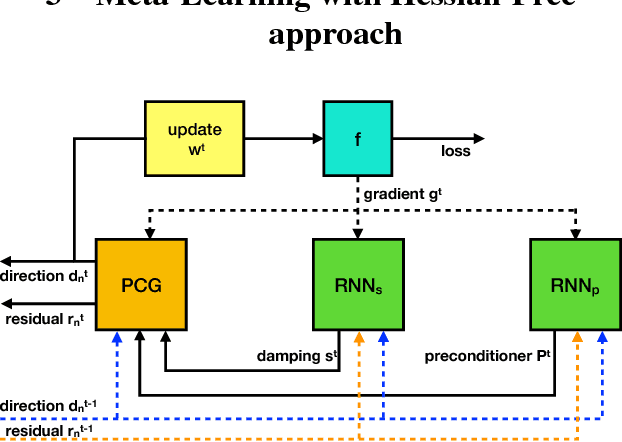
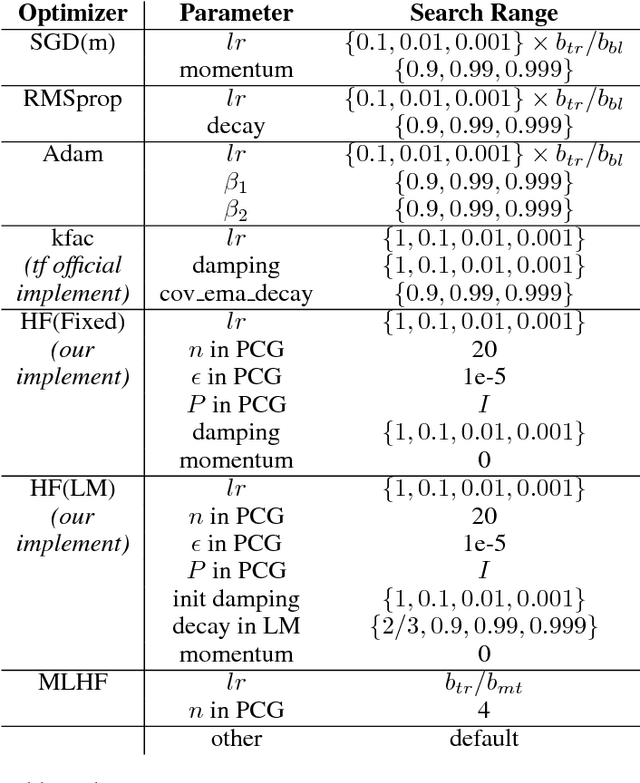
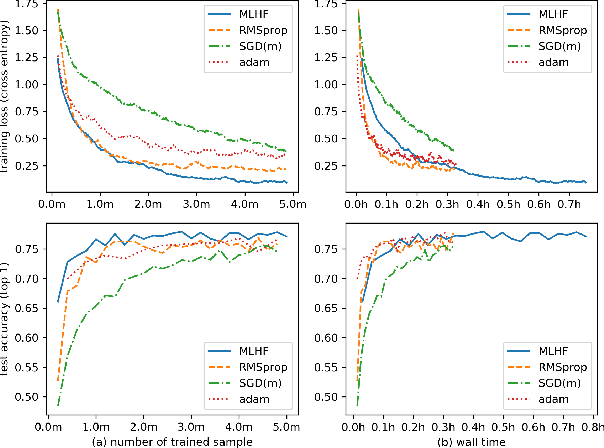
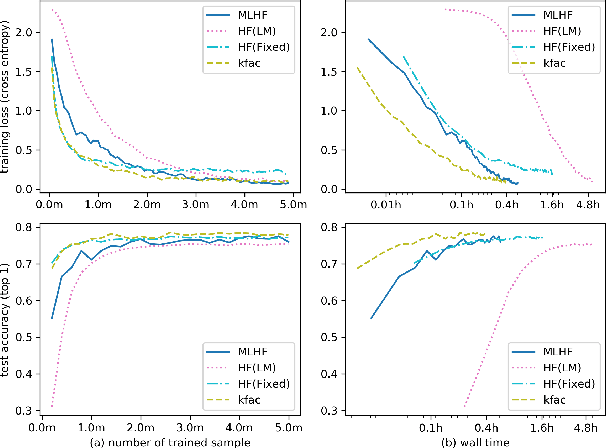
Meta-learning is a promising method to achieve efficient training method towards deep neural net and has been attracting increases interests in recent years. But most of the current methods are still not capable to train complex neuron net model with long-time training process. In this paper, a novel second-order meta-optimizer, named Meta-learning with Hessian-Free(MLHF) approach, is proposed based on the Hessian-Free approach. Two recurrent neural networks are established to generate the damping and the precondition matrix of this Hessian-Free framework. A series of techniques to meta-train the MLHF towards stable and reinforce the meta-training of this optimizer, including the gradient calculation of $H$. Numerical experiments on deep convolution neural nets, including CUDA-convnet and ResNet18(v2), with datasets of CIFAR10 and ILSVRC2012, indicate that the MLHF shows good and continuous training performance during the whole long-time training process, i.e., both the rapid-decreasing early stage and the steadily-deceasing later stage, and so is a promising meta-learning framework towards elevating the training efficiency in real-world deep neural nets.
On the Statistical Challenges of Echo State Networks and Some Potential Remedies
Feb 20, 2018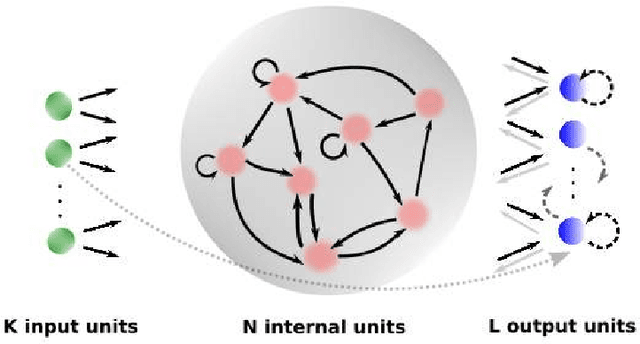

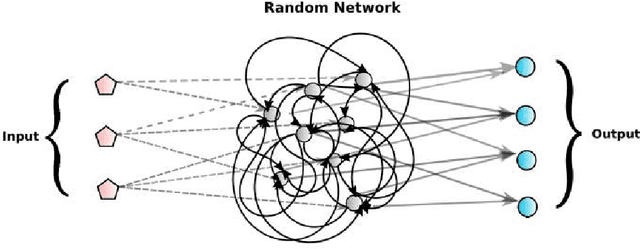
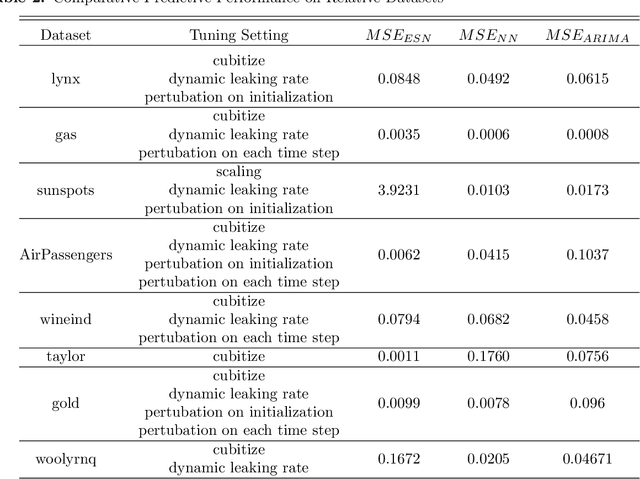
Echo state networks are powerful recurrent neural networks. However, they are often unstable and shaky, making the process of finding an good ESN for a specific dataset quite hard. Obtaining a superb accuracy by using the Echo State Network is a challenging task. We create, develop and implement a family of predictably optimal robust and stable ensemble of Echo State Networks via regularizing the training and perturbing the input. Furthermore, several distributions of weights have been tried based on the shape to see if the shape of the distribution has the impact for reducing the error. We found ESN can track in short term for most dataset, but it collapses in the long run. Short-term tracking with large size reservoir enables ESN to perform strikingly with superior prediction. Based on this scenario, we go a further step to aggregate many of ESNs into an ensemble to lower the variance and stabilize the system by stochastic replications and bootstrapping of input data.
Random Subspace Learning Approach to High-Dimensional Outliers Detection
May 03, 2015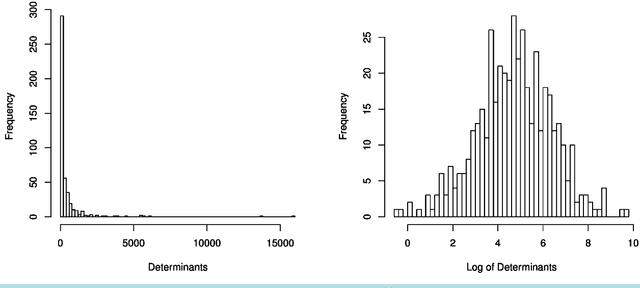
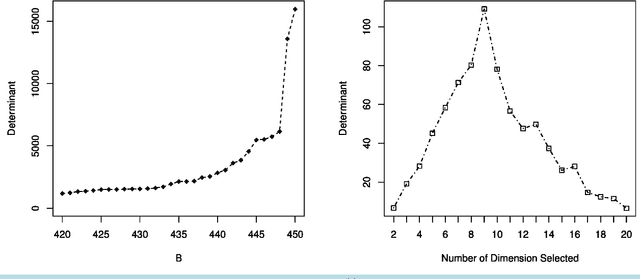
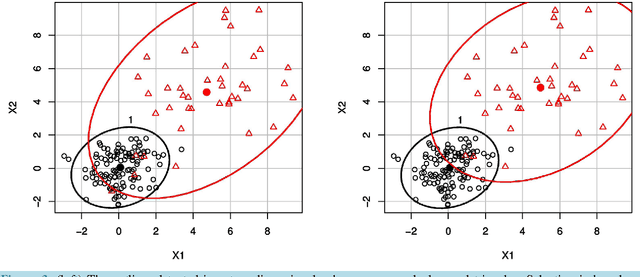
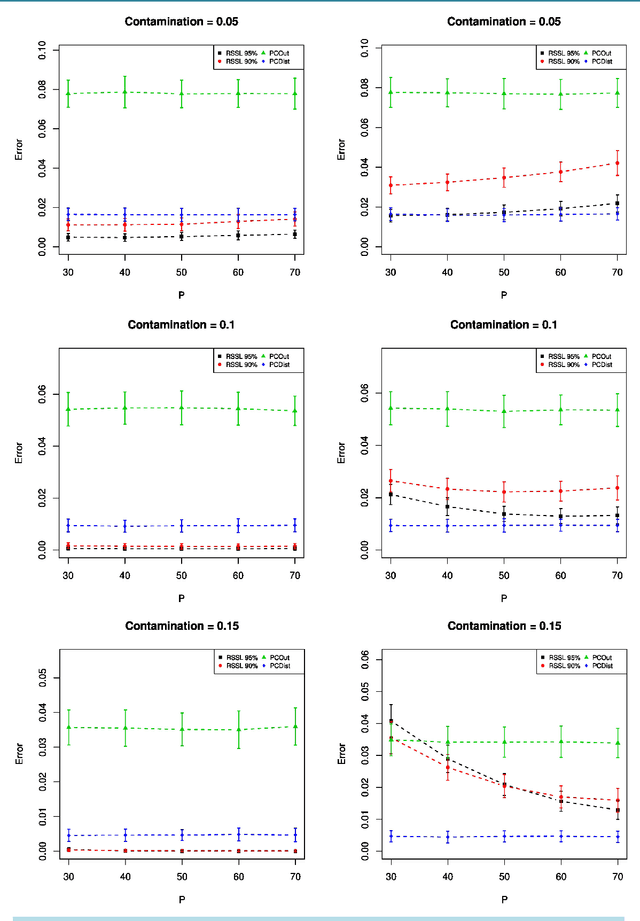
We introduce and develop a novel approach to outlier detection based on adaptation of random subspace learning. Our proposed method handles both high-dimension low-sample size and traditional low-dimensional high-sample size datasets. Essentially, we avoid the computational bottleneck of techniques like minimum covariance determinant (MCD) by computing the needed determinants and associated measures in much lower dimensional subspaces. Both theoretical and computational development of our approach reveal that it is computationally more efficient than the regularized methods in high-dimensional low-sample size, and often competes favorably with existing methods as far as the percentage of correct outlier detection is concerned.
On the Predictive Properties of Binary Link Functions
Feb 16, 2015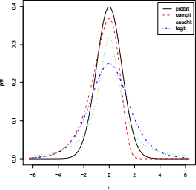
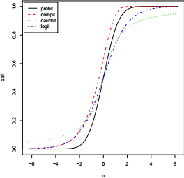
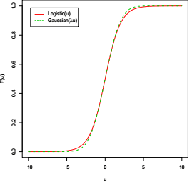
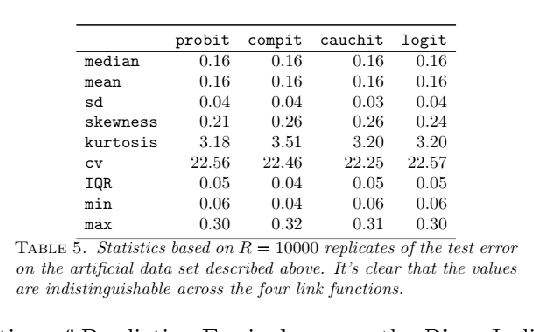
This paper provides a theoretical and computational justification of the long held claim that of the similarity of the probit and logit link functions often used in binary classification. Despite this widespread recognition of the strong similarities between these two link functions, very few (if any) researchers have dedicated time to carry out a formal study aimed at establishing and characterizing firmly all the aspects of the similarities and differences. This paper proposes a definition of both structural and predictive equivalence of link functions-based binary regression models, and explores the various ways in which they are either similar or dissimilar. From a predictive analytics perspective, it turns out that not only are probit and logit perfectly predictively concordant, but the other link functions like cauchit and complementary log log enjoy very high percentage of predictive equivalence. Throughout this paper, simulated and real life examples demonstrate all the equivalence results that we prove theoretically.
Adaptive Random SubSpace Learning (RSSL) Algorithm for Prediction
Feb 09, 2015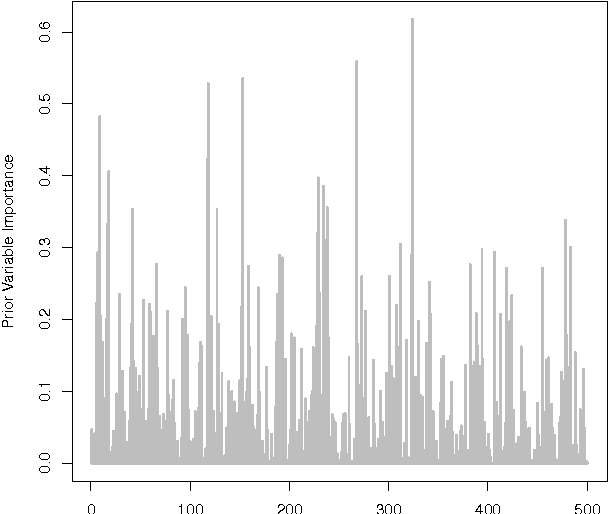
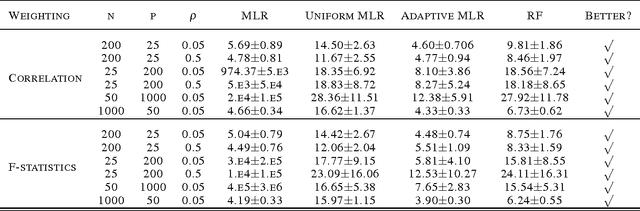
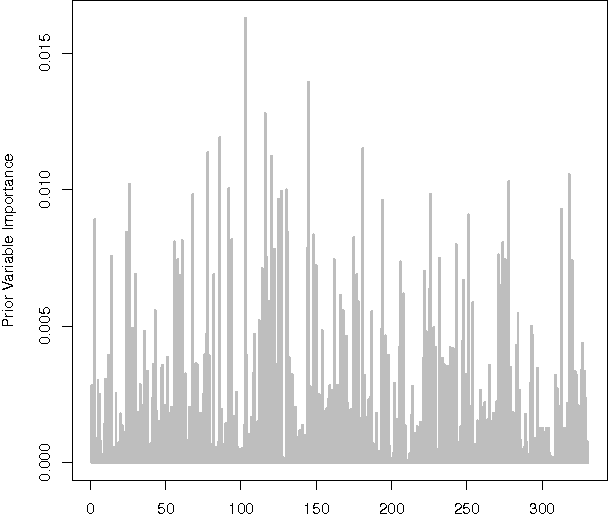
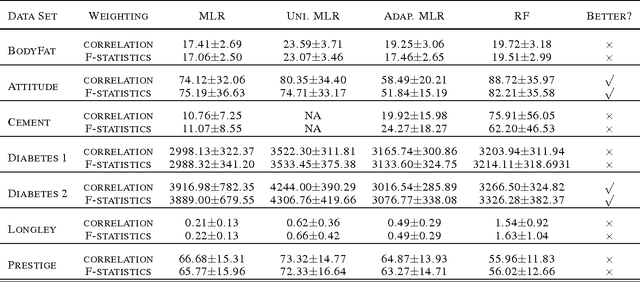
We present a novel adaptive random subspace learning algorithm (RSSL) for prediction purpose. This new framework is flexible where it can be adapted with any learning technique. In this paper, we tested the algorithm for regression and classification problems. In addition, we provide a variety of weighting schemes to increase the robustness of the developed algorithm. These different wighting flavors were evaluated on simulated as well as on real-world data sets considering the cases where the ratio between features (attributes) and instances (samples) is large and vice versa. The framework of the new algorithm consists of many stages: first, calculate the weights of all features on the data set using the correlation coefficient and F-statistic statistical measurements. Second, randomly draw n samples with replacement from the data set. Third, perform regular bootstrap sampling (bagging). Fourth, draw without replacement the indices of the chosen variables. The decision was taken based on the heuristic subspacing scheme. Fifth, call base learners and build the model. Sixth, use the model for prediction purpose on test set of the data. The results show the advancement of the adaptive RSSL algorithm in most of the cases compared with the synonym (conventional) machine learning algorithms.
A Taxonomy of Big Data for Optimal Predictive Machine Learning and Data Mining
Jan 03, 2015
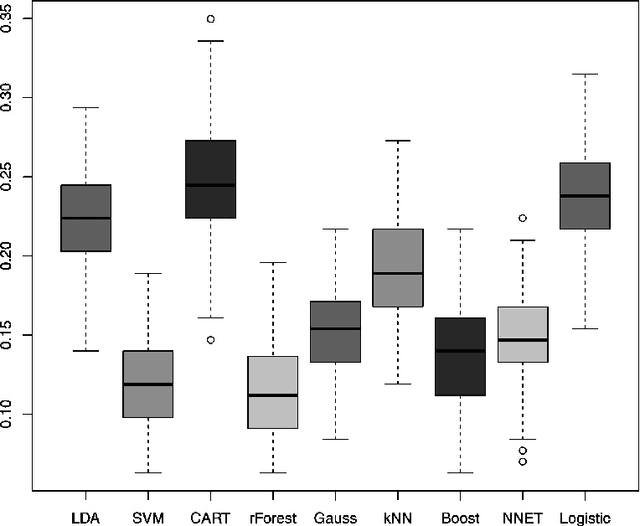

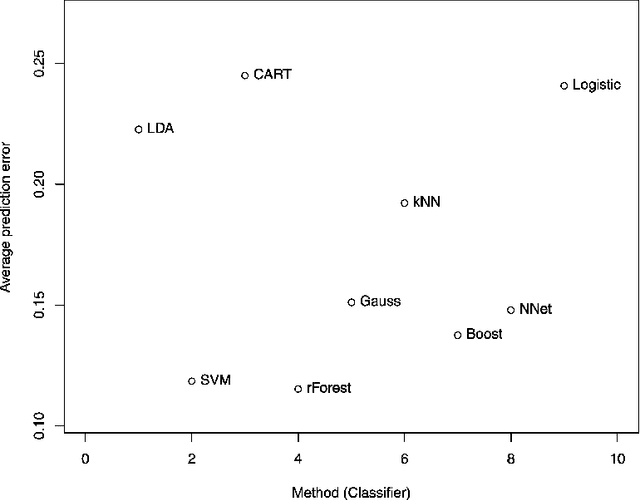
Big data comes in various ways, types, shapes, forms and sizes. Indeed, almost all areas of science, technology, medicine, public health, economics, business, linguistics and social science are bombarded by ever increasing flows of data begging to analyzed efficiently and effectively. In this paper, we propose a rough idea of a possible taxonomy of big data, along with some of the most commonly used tools for handling each particular category of bigness. The dimensionality p of the input space and the sample size n are usually the main ingredients in the characterization of data bigness. The specific statistical machine learning technique used to handle a particular big data set will depend on which category it falls in within the bigness taxonomy. Large p small n data sets for instance require a different set of tools from the large n small p variety. Among other tools, we discuss Preprocessing, Standardization, Imputation, Projection, Regularization, Penalization, Compression, Reduction, Selection, Kernelization, Hybridization, Parallelization, Aggregation, Randomization, Replication, Sequentialization. Indeed, it is important to emphasize right away that the so-called no free lunch theorem applies here, in the sense that there is no universally superior method that outperforms all other methods on all categories of bigness. It is also important to stress the fact that simplicity in the sense of Ockham's razor non plurality principle of parsimony tends to reign supreme when it comes to massive data. We conclude with a comparison of the predictive performance of some of the most commonly used methods on a few data sets.
Probit Normal Correlated Topic Models
Oct 03, 2014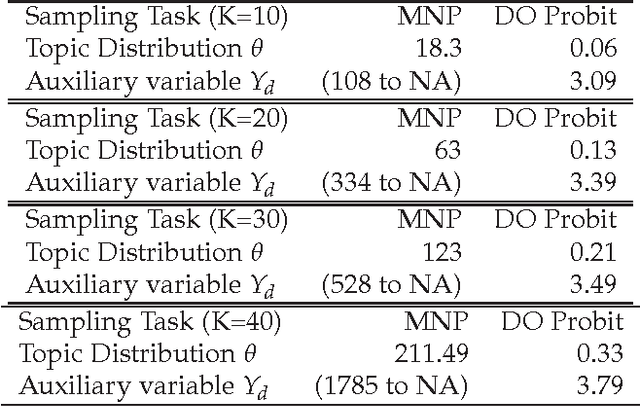
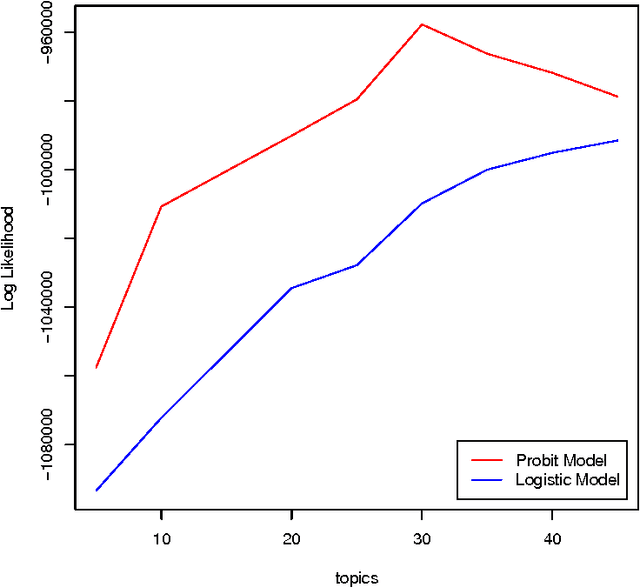
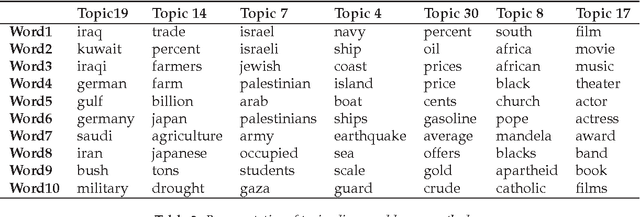

The logistic normal distribution has recently been adapted via the transformation of multivariate Gaus- sian variables to model the topical distribution of documents in the presence of correlations among topics. In this paper, we propose a probit normal alternative approach to modelling correlated topical structures. Our use of the probit model in the context of topic discovery is novel, as many authors have so far con- centrated solely of the logistic model partly due to the formidable inefficiency of the multinomial probit model even in the case of very small topical spaces. We herein circumvent the inefficiency of multinomial probit estimation by using an adaptation of the diagonal orthant multinomial probit in the topic models context, resulting in the ability of our topic modelling scheme to handle corpuses with a large number of latent topics. An additional and very important benefit of our method lies in the fact that unlike with the logistic normal model whose non-conjugacy leads to the need for sophisticated sampling schemes, our ap- proach exploits the natural conjugacy inherent in the auxiliary formulation of the probit model to achieve greater simplicity. The application of our proposed scheme to a well known Associated Press corpus not only helps discover a large number of meaningful topics but also reveals the capturing of compellingly intuitive correlations among certain topics. Besides, our proposed approach lends itself to even further scalability thanks to various existing high performance algorithms and architectures capable of handling millions of documents.