 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNaive Dictionary On Musical Corpora: From Knowledge Representation To Pattern Recognition
Paper and Code
Nov 29, 2018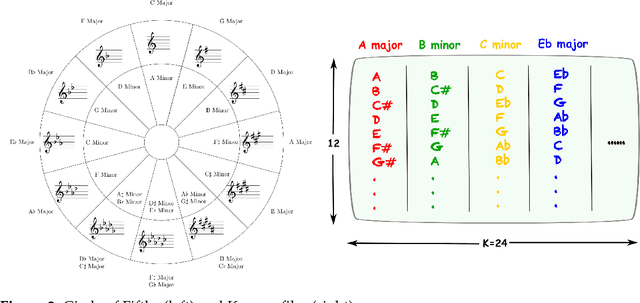
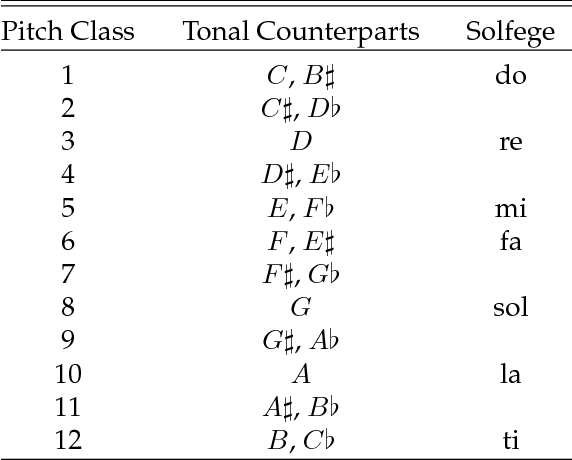
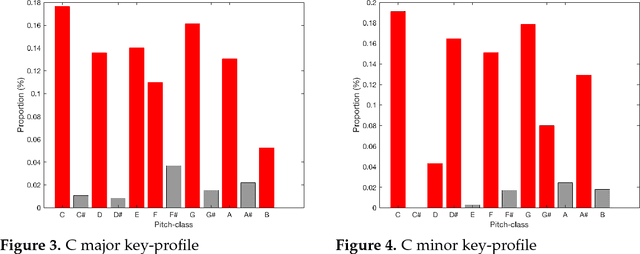
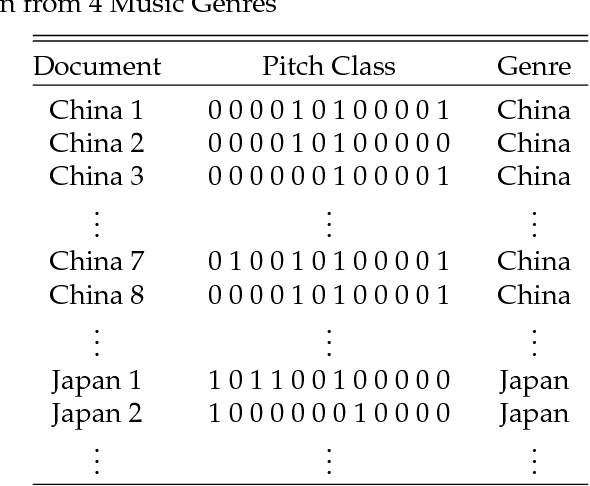
In this paper, we propose and develop the novel idea of treating musical sheets as literary documents in the traditional text analytics parlance, to fully benefit from the vast amount of research already existing in statistical text mining and topic modelling. We specifically introduce the idea of representing any given piece of music as a collection of "musical words" that we codenamed "muselets", which are essentially musical words of various lengths. Given the novelty and therefore the extremely difficulty of properly forming a complete version of a dictionary of muselets, the present paper focuses on a simpler albeit naive version of the ultimate dictionary, which we refer to as a Naive Dictionary because of the fact that all the words are of the same length. We specifically herein construct a naive dictionary featuring a corpus made up of African American, Chinese, Japanese and Arabic music, on which we perform both topic modelling and pattern recognition. Although some of the results based on the Naive Dictionary are reasonably good, we anticipate phenomenal predictive performances once we get around to actually building a full scale complete version of our intended dictionary of muselets.