 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransMorph: Transformer for unsupervised medical image registration
Nov 23, 2021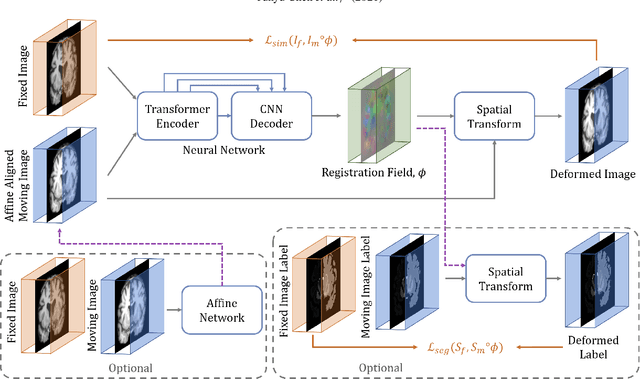

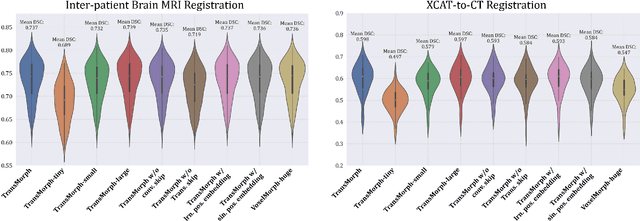
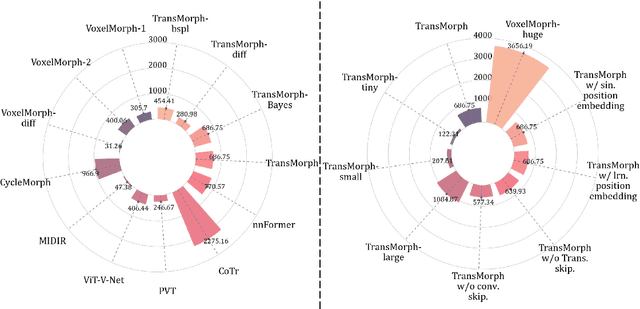
In the last decade, convolutional neural networks (ConvNets) have dominated the field of medical image analysis. However, it is found that the performances of ConvNets may still be limited by their inability to model long-range spatial relations between voxels in an image. Numerous vision Transformers have been proposed recently to address the shortcomings of ConvNets, demonstrating state-of-the-art performances in many medical imaging applications. Transformers may be a strong candidate for image registration because their self-attention mechanism enables a more precise comprehension of the spatial correspondence between moving and fixed images. In this paper, we present TransMorph, a hybrid Transformer-ConvNet model for volumetric medical image registration. We also introduce three variants of TransMorph, with two diffeomorphic variants ensuring the topology-preserving deformations and a Bayesian variant producing a well-calibrated registration uncertainty estimate. The proposed models are extensively validated against a variety of existing registration methods and Transformer architectures using volumetric medical images from two applications: inter-patient brain MRI registration and phantom-to-CT registration. Qualitative and quantitative results demonstrate that TransMorph and its variants lead to a substantial performance improvement over the baseline methods, demonstrating the effectiveness of Transformers for medical image registration.
Learning Fuzzy Clustering for SPECT/CT Segmentation via Convolutional Neural Networks
Apr 22, 2021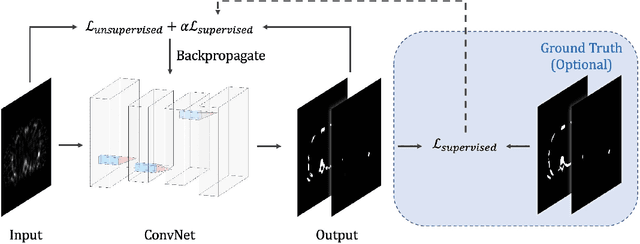

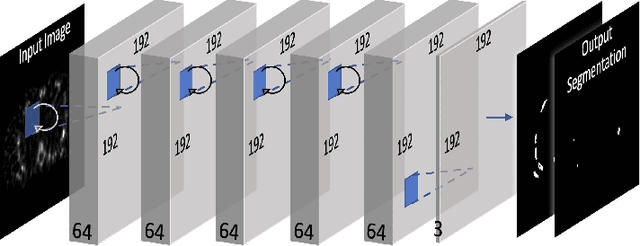

Quantitative bone single-photon emission computed tomography (QBSPECT) has the potential to provide a better quantitative assessment of bone metastasis than planar bone scintigraphy due to its ability to better quantify activity in overlapping structures. An important element of assessing response of bone metastasis is accurate image segmentation. However, limited by the properties of QBSPECT images, the segmentation of anatomical regions-of-interests (ROIs) still relies heavily on the manual delineation by experts. This work proposes a fast and robust automated segmentation method for partitioning a QBSPECT image into lesion, bone, and background. We present a new unsupervised segmentation loss function and its semi- and supervised variants for training a convolutional neural network (ConvNet). The loss functions were developed based on the objective function of the classical Fuzzy C-means (FCM) algorithm. We conducted a comprehensive study to compare our proposed methods with ConvNets trained using supervised loss functions and conventional clustering methods. The Dice similarity coefficient (DSC) and several other metrics were used as figures of merit as applied to the task of delineating lesion and bone in both simulated and clinical SPECT/CT images. We experimentally demonstrated that the proposed methods yielded good segmentation results on a clinical dataset even though the training was done using realistic simulated images. A ConvNet-based image segmentation method that uses novel loss functions was developed and evaluated. The method can operate in unsupervised, semi-supervised, or fully-supervised modes depending on the availability of annotated training data. The results demonstrated that the proposed method provides fast and robust lesion and bone segmentation for QBSPECT/CT. The method can potentially be applied to other medical image segmentation applications.
ViT-V-Net: Vision Transformer for Unsupervised Volumetric Medical Image Registration
Apr 13, 2021


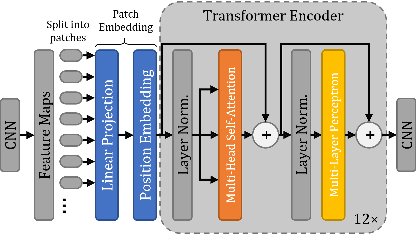
In the last decade, convolutional neural networks (ConvNets) have dominated and achieved state-of-the-art performances in a variety of medical imaging applications. However, the performances of ConvNets are still limited by lacking the understanding of long-range spatial relations in an image. The recently proposed Vision Transformer (ViT) for image classification uses a purely self-attention-based model that learns long-range spatial relations to focus on the relevant parts of an image. Nevertheless, ViT emphasizes the low-resolution features because of the consecutive downsamplings, result in a lack of detailed localization information, making it unsuitable for image registration. Recently, several ViT-based image segmentation methods have been combined with ConvNets to improve the recovery of detailed localization information. Inspired by them, we present ViT-V-Net, which bridges ViT and ConvNet to provide volumetric medical image registration. The experimental results presented here demonstrate that the proposed architecture achieves superior performance to several top-performing registration methods.
An Unsupervised Learning Model for Medical Image Segmentation
Jan 28, 2020


For the majority of the learning-based segmentation methods, a large quantity of high-quality training data is required. In this paper, we present a novel learning-based segmentation model that could be trained semi- or un- supervised. Specifically, in the unsupervised setting, we parameterize the Active contour without edges (ACWE) framework via a convolutional neural network (ConvNet), and optimize the parameters of the ConvNet using a self-supervised method. In another setting (semi-supervised), the auxiliary segmentation ground truth is used during training. We show that the method provides fast and high-quality bone segmentation in the context of single-photon emission computed tomography (SPECT) image.
Generating Patient-like Phantoms Using Fully Unsupervised Deformable Image Registration with Convolutional Neural Networks
Dec 27, 2019
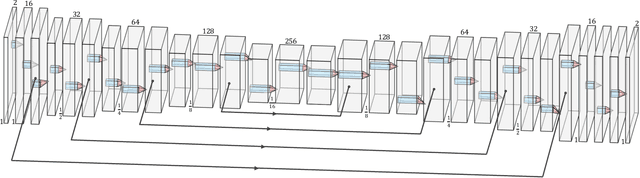

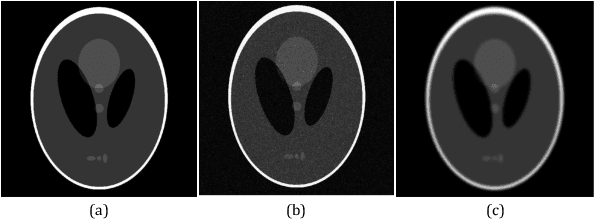
The use of Convolutional neural networks (ConvNets) in medical imaging research has become widespread in recent years. However, a major drawback of these methods is that they require a large number of annotated training images. Data augmentation has been proposed to alleviate this. One data augmentation strategy is to apply random deformation to existing image data, but the deformed images often will not follow exhibit realistic shape or intensity patterns. In this paper, we present a novel, ConvNet based image registration method for creating patient-like digital phantoms from the existing computerized phantoms. Unlike existing learning-based registration techniques, for which the performance predominantly depends on the domain-specific training images, the proposed method is fully unsupervised, meaning that it optimizes an objective function independently of training data for a given image pair. While classical methods registration also do not require training data, they work in lower-dimensional parameter space; the proposed approach operates directly in the high-dimensional parameter space without any training beforehand. In this paper, we show that the resulting deformed phantom competently matches the anatomy model of a real human while providing the "gold-standard" for the anatomies. Combined with simulation programs, the generated phantoms could potentially serve as a data augmentation tool in today's deep learning studies.
Feature-Based Image Clustering and Segmentation Using Wavelets
Jul 05, 2019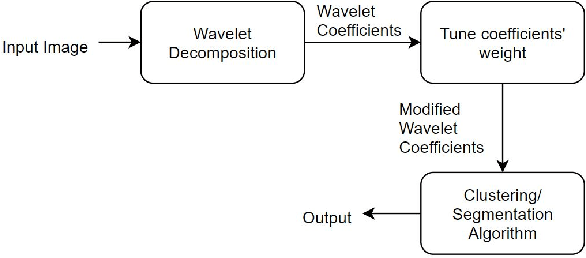

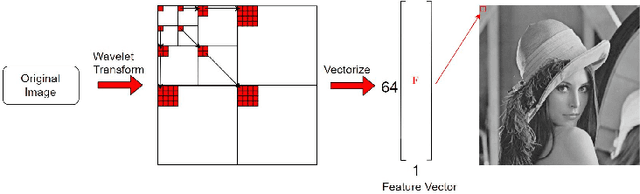

Pixel intensity is a widely used feature for clustering and segmentation algorithms, the resulting segmentation using only intensity values might suffer from noises and lack of spatial context information. Wavelet transform is often used for image denoising and classification. We proposed a novel method to incorporate Wavelet features in segmentation and clustering algorithms. The conventional K-means, Fuzzy c-means (FCM), and Active contour without edges (ACWE) algorithms were modified to adapt Wavelet features, leading to robust clustering/segmentation algorithms. A weighting parameter to control the weight of low-frequency sub-band information was also introduced. The new algorithms showed the capability to converge to different segmentation results based on the frequency information derived from the Wavelet sub-bands.