 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Automated and Marker-less Parkinson Disease Assessment: Predicting UPDRS Scores using Sit-stand videos
Apr 10, 2021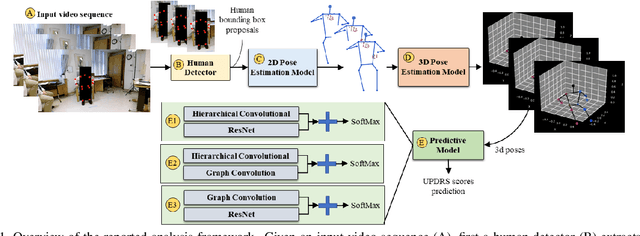

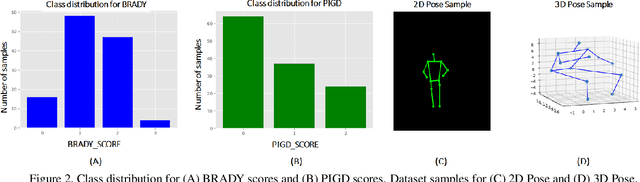
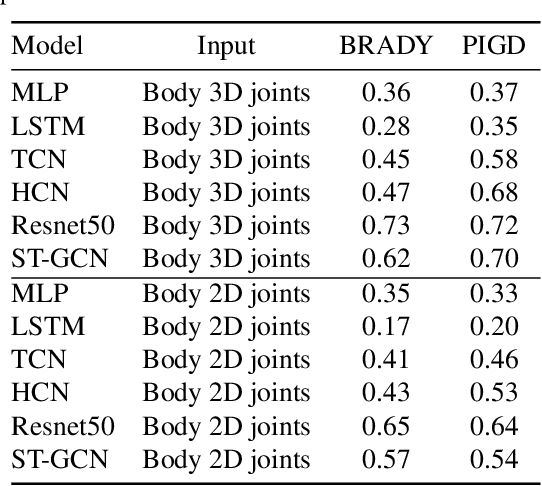
This paper presents a novel deep learning enabled, video based analysis framework for assessing the Unified Parkinsons Disease Rating Scale (UPDRS) that can be used in the clinic or at home. We report results from comparing the performance of the framework to that of trained clinicians on a population of 32 Parkinsons disease (PD) patients. In-person clinical assessments by trained neurologists are used as the ground truth for training our framework and for comparing the performance. We find that the standard sit-to-stand activity can be used to evaluate the UPDRS sub-scores of bradykinesia (BRADY) and posture instability and gait disorders (PIGD). For BRADY we find F1-scores of 0.75 using our framework compared to 0.50 for the video based rater clinicians, while for PIGD we find 0.78 for the framework and 0.45 for the video based rater clinicians. We believe our proposed framework has potential to provide clinically acceptable end points of PD in greater granularity without imposing burdens on patients and clinicians, which empowers a variety of use cases such as passive tracking of PD progression in spaces such as nursing homes, in-home self-assessment, and enhanced tele-medicine.
Deep Gradient Boosting
Jul 29, 2019



Stochastic gradient descent (SGD) has been the dominant optimization method for training deep neural networks due to its many desirable properties. One of the more remarkable and least understood quality of SGD is that it generalizes relatively well on unseen data even when the neural network has millions of parameters. In this work, we show that SGD is an extreme case of deep gradient boosting (DGB) and as such is intrinsically regularized. The key idea of DGB is that back-propagated gradients calculated using the chain rule can be viewed as pseudo-residual targets. Thus at each layer the weight update is calculated by solving the corresponding gradient boosting problem. We hypothesize that some learning tasks can benefit from a more lax regularization requirement and this approach provides a way to control that. We tested this hypothesis on a number of benchmark data sets and show that indeed in a subset of cases DGB outperforms SGD and under-performs on tasks that are more prone to over-fitting, such as image recognition.
Unsupervised Ensemble Regression
Mar 08, 2017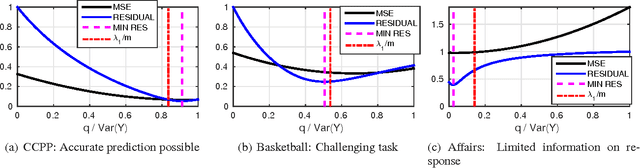
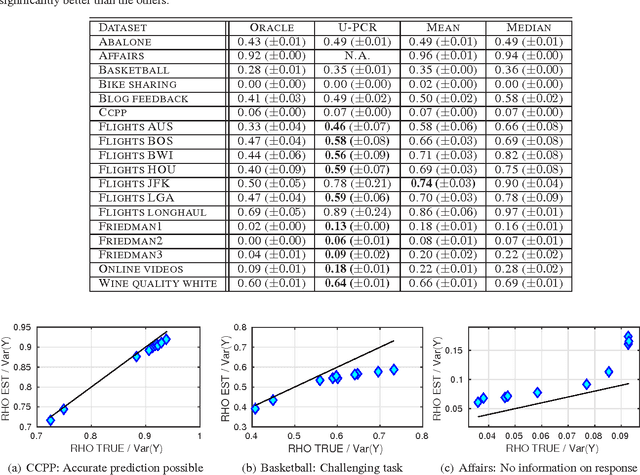
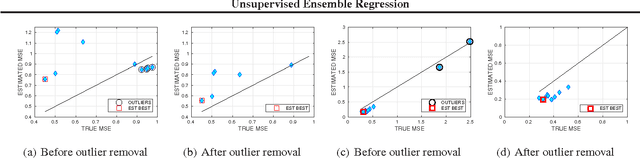
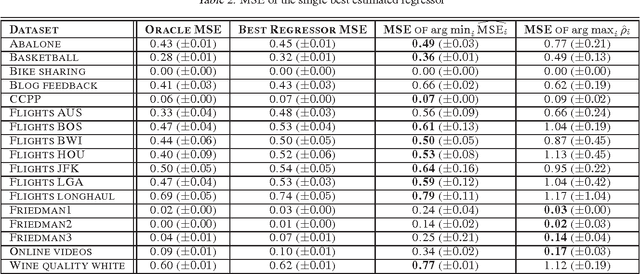
Consider a regression problem where there is no labeled data and the only observations are the predictions $f_i(x_j)$ of $m$ experts $f_{i}$ over many samples $x_j$. With no knowledge on the accuracy of the experts, is it still possible to accurately estimate the unknown responses $y_{j}$? Can one still detect the least or most accurate experts? In this work we propose a framework to study these questions, based on the assumption that the $m$ experts have uncorrelated deviations from the optimal predictor. Assuming the first two moments of the response are known, we develop methods to detect the best and worst regressors, and derive U-PCR, a novel principal components approach for unsupervised ensemble regression. We provide theoretical support for U-PCR and illustrate its improved accuracy over the ensemble mean and median on a variety of regression problems.