 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOvercoming the Retrieval Barrier: Indirect Prompt Injection in the Wild for LLM Systems
Jan 11, 2026Large language models (LLMs) increasingly rely on retrieving information from external corpora. This creates a new attack surface: indirect prompt injection (IPI), where hidden instructions are planted in the corpora and hijack model behavior once retrieved. Previous studies have highlighted this risk but often avoid the hardest step: ensuring that malicious content is actually retrieved. In practice, unoptimized IPI is rarely retrieved under natural queries, which leaves its real-world impact unclear. We address this challenge by decomposing the malicious content into a trigger fragment that guarantees retrieval and an attack fragment that encodes arbitrary attack objectives. Based on this idea, we design an efficient and effective black-box attack algorithm that constructs a compact trigger fragment to guarantee retrieval for any attack fragment. Our attack requires only API access to embedding models, is cost-efficient (as little as $0.21 per target user query on OpenAI's embedding models), and achieves near-100% retrieval across 11 benchmarks and 8 embedding models (including both open-source models and proprietary services). Based on this attack, we present the first end-to-end IPI exploits under natural queries and realistic external corpora, spanning both RAG and agentic systems with diverse attack objectives. These results establish IPI as a practical and severe threat: when a user issued a natural query to summarize emails on frequently asked topics, a single poisoned email was sufficient to coerce GPT-4o into exfiltrating SSH keys with over 80% success in a multi-agent workflow. We further evaluate several defenses and find that they are insufficient to prevent the retrieval of malicious text, highlighting retrieval as a critical open vulnerability.
Accurate Table Question Answering with Accessible LLMs
Jan 06, 2026Given a table T in a database and a question Q in natural language, the table question answering (TQA) task aims to return an accurate answer to Q based on the content of T. Recent state-of-the-art solutions leverage large language models (LLMs) to obtain high-quality answers. However, most rely on proprietary, large-scale LLMs with costly API access, posing a significant financial barrier. This paper instead focuses on TQA with smaller, open-weight LLMs that can run on a desktop or laptop. This setting is challenging, as such LLMs typically have weaker capabilities than large proprietary models, leading to substantial performance degradation with existing methods. We observe that a key reason for this degradation is that prior approaches often require the LLM to solve a highly sophisticated task using long, complex prompts, which exceed the capabilities of small open-weight LLMs. Motivated by this observation, we present Orchestra, a multi-agent approach that unlocks the potential of accessible LLMs for high-quality, cost-effective TQA. Orchestra coordinates a group of LLM agents, each responsible for a relatively simple task, through a structured, layered workflow to solve complex TQA problems -- akin to an orchestra. By reducing the prompt complexity faced by each agent, Orchestra significantly improves output reliability. We implement Orchestra on top of AgentScope, an open-source multi-agent framework, and evaluate it on multiple TQA benchmarks using a wide range of open-weight LLMs. Experimental results show that Orchestra achieves strong performance even with small- to medium-sized models. For example, with Qwen2.5-14B, Orchestra reaches 72.1% accuracy on WikiTQ, approaching the best prior result of 75.3% achieved with GPT-4; with larger Qwen, Llama, or DeepSeek models, Orchestra outperforms all prior methods and establishes new state-of-the-art results across all benchmarks.
Skellam Mixture Mechanism: a Novel Approach to Federated Learning with Differential Privacy
Dec 08, 2022


Deep neural networks have strong capabilities of memorizing the underlying training data, which can be a serious privacy concern. An effective solution to this problem is to train models with differential privacy, which provides rigorous privacy guarantees by injecting random noise to the gradients. This paper focuses on the scenario where sensitive data are distributed among multiple participants, who jointly train a model through federated learning (FL), using both secure multiparty computation (MPC) to ensure the confidentiality of each gradient update, and differential privacy to avoid data leakage in the resulting model. A major challenge in this setting is that common mechanisms for enforcing DP in deep learning, which inject real-valued noise, are fundamentally incompatible with MPC, which exchanges finite-field integers among the participants. Consequently, most existing DP mechanisms require rather high noise levels, leading to poor model utility. Motivated by this, we propose Skellam mixture mechanism (SMM), an approach to enforce DP on models built via FL. Compared to existing methods, SMM eliminates the assumption that the input gradients must be integer-valued, and, thus, reduces the amount of noise injected to preserve DP. Further, SMM allows tight privacy accounting due to the nice composition and sub-sampling properties of the Skellam distribution, which are key to accurate deep learning with DP. The theoretical analysis of SMM is highly non-trivial, especially considering (i) the complicated math of differentially private deep learning in general and (ii) the fact that the mixture of two Skellam distributions is rather complex, and to our knowledge, has not been studied in the DP literature. Extensive experiments on various practical settings demonstrate that SMM consistently and significantly outperforms existing solutions in terms of the utility of the resulting model.
DPIS: An Enhanced Mechanism for Differentially Private SGD with Importance Sampling
Oct 19, 2022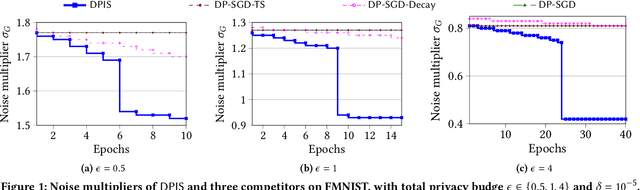
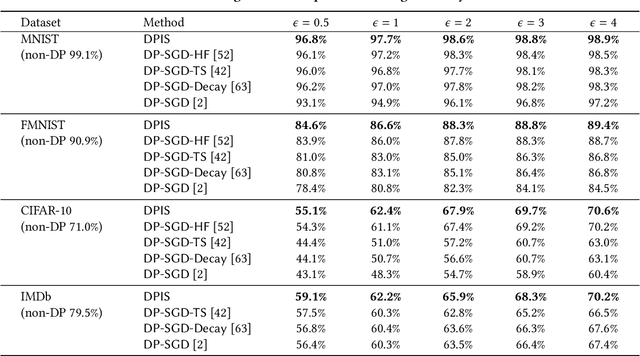
Nowadays, differential privacy (DP) has become a well-accepted standard for privacy protection, and deep neural networks (DNN) have been immensely successful in machine learning. The combination of these two techniques, i.e., deep learning with differential privacy, promises the privacy-preserving release of high-utility models trained with sensitive data such as medical records. A classic mechanism for this purpose is DP-SGD, which is a differentially private version of the stochastic gradient descent (SGD) optimizer commonly used for DNN training. Subsequent approaches have improved various aspects of the model training process, including noise decay schedule, model architecture, feature engineering, and hyperparameter tuning. However, the core mechanism for enforcing DP in the SGD optimizer remains unchanged ever since the original DP-SGD algorithm, which has increasingly become a fundamental barrier limiting the performance of DP-compliant machine learning solutions. Motivated by this, we propose DPIS, a novel mechanism for differentially private SGD training that can be used as a drop-in replacement of the core optimizer of DP-SGD, with consistent and significant accuracy gains over the latter. The main idea is to employ importance sampling (IS) in each SGD iteration for mini-batch selection, which reduces both sampling variance and the amount of random noise injected to the gradients that is required to satisfy DP. Integrating IS into the complex mathematical machinery of DP-SGD is highly non-trivial. DPIS addresses the challenge through novel mechanism designs, fine-grained privacy analysis, efficiency enhancements, and an adaptive gradient clipping optimization. Extensive experiments on four benchmark datasets, namely MNIST, FMNIST, CIFAR-10 and IMDb, demonstrate the superior effectiveness of DPIS over existing solutions for deep learning with differential privacy.
* A short version of this paper will appear in CCS 2022